Introduzione

Obiettivi
Questo manuale si prefigge di coprire un vasto spettro di caratteristiche di programmazione in linguaggio Go, tramite esempi commentati, e con riferimenti di approfondimento al manuale ufficiale.
Prerequisiti
Il corso è indirizzato a chi possiede conoscenze ed esperienza di programmazione di altri linguaggi, preferibilmente il linguaggio C, C++ o Java, ma anche le versioni moderne di JavaScript.
Si dà per scontata una familiarità con i consueti costrutti di selezione (if, switch) e di ciclo (for, while, foreach), con i fondamenti della programmazione orientata agli oggetti, con il passaggio di parametri per valore e per riferimento, col concetto di puntatore, nonchè dei principi di interazione col sistema operativo sottostante, in particolare Unix-like.
Il Linguaggio Go
Origini

Go (Golang) è un linguaggio di programmazione sviluppato da Google a partire dal 2007.
Il linguaggio si chiama ufficialmente Go. Per evitare problemi con le ricerche in Internet, viene anche chiamato Golang.
I suoi autori sono famosi:
- Ken Thompson - uno degli inventori originali del sistema operativo Unix
- Rob Pike
- Robert Griesemer
Proprietà

Il linguaggio Go è:
- Compilato
- Più efficiente dei linguaggi interpretati
- Richiede il tempo di compilazione
- Supporta tutti i maggiori sistemi operativi e CPU
- Garbage Collected
- Gestione automatica dell'allocazione di memoria
- Veloce e senza latenza
- Concorrente
- Più threads di esecuzione simultanei
- Strutture di concorernza nel linguaggio di base
Il principo filosofico guida di Go è la massima semplicità.
Non devono esserci più modi per compiere un'operazione tramite un programma, ma uno solo, quello giusto.
Go è un linguaggio procedurale, imperativo. Non è un linguaggio Object Oriented, anche se ne riproduce alcuni features.
Non è un linguaggio progettato per l'estrema velocità o performance, nè per la sua abilità a trattare quantità notevoli di dati, per quanto sia piuttosto efficiente.
E' un linguaggio di programmazione generico, non specialistico. Il suo scopo è di produrre programmi comprensibili, e indirettamente di reintrodurre il piacere della programmazione. Il suo punto di forza è la realizzazione di programmi concorrenti, composti di più threads di esecuzione, che si distribuiscono trasparentemente sulle CPU disponibili.
Attribuzioni
Molto del codice in questo gitbook è copiato dal sito https://gobyexample.com di Mark McGranaghan, che lo ha concesso sotto i termini dells licenza Creative Commons Attribution 3.0 Unported License (http://creativecommons.org/licenses/by/3.0/ ).
Non è stata consultata la versione italiana di tale sito, disponibile su https://github.com/golangit/gobyexample di Nicola Corti and Morgan Bazalgette.
Al codice originale sono stati apportati alcuni cambiamenti, e sono stati tradotti i commenti.
Licenza

Il presente documento è copyright Michele Simioli e fornito con la licenza Creative Commons Attribution 3.0 Unported License, il cui sito è indicato sopra.
Si ricorda che l'utilizzo consistente di codice di questo gitbook in lavori derivati richiede anche l'attribuzione al creatore del codice originale.
Michele Simioli (michele@simioli.it)
Ultimo aggiornamento: Marzo 2024
Fondamenti di Programmazione
Un file sorgente Go ha una certa struttura di base, e una indentazione ben definita.
Un progetto Go ha una serie di sottodirectories e packages che ne determinano la struttura ed organizzano il materiale, il cosiddetto scaffolding.
Il compilatore Go va appositamente installato e configurato tramite una serie di variabili d'ambiente. Il workflow consiste principalmente nelle operazioni di editing, build e run e viene eseguito con opporuni argomenti del comando go.
Il Go possiede una serie di costrutti di controllo - di decisione e di ciclo - simili a quelli di altri linguaggi di programmazione.
Installazione

Installazione in Linux
Scaricare l'ultima release dal sito https://golang.org/dl/
Selezionare la versione adatta al proprio sistema operativo.
E' opportuno scaricare l'ultima versione dal sito ufficiale e non adottare la versione contenuta nell'ambiente di pacchetti Linux. Go è in continua evoluzione e l'ultima versione, oltre a nuove features, contiene le patch alla versione precedente.
Spacchettare il file scaricato sotto /opt col comando, p.es.:
sudo tar xvzf go1.22.1.linux-amd64.tar.gz -C /opt
L'installazione sotto /opt è vantaggiosa perchè permette la disinstallazione solo cancellando ricorsivamente /opt/go....
Go e Moduli
Il linguaggio Go, dalla release 1.11 supporta la programmazione tramite moduli. I moduli aiutano molto nel controllo delle dipendenze del nostro programma.
Sfortunatamente la gestione dei moduli non è da considerarsi un argomento semplice ed è opportuno non trattarli in un corso iniziale.
Meglio considerare prima la programmazione tradizionale di Go, senza l'uso dei moduli.
Per disabilitare i moduli occorre impostare la variabile d'ambiente GO111MODULE=off.
Scaffolding
Lo sviluppo in Go ha uno scaffolding ben definito, ovvero una impalcatura di directory, che bisogna preparare.
Tutto il materiale di sviluppo di Go è relativo ad una directory di base.
Supponiamo di decidere che la directory in cui produrre i programmi Go sia $HOME/go:
mkdir ~/go
La directory $HOME/go ha una struttura da formare:
mkdir ~/go/src
mkdir ~/go/bin
mkdir ~/go/pkg
I nostri progetti saranno tutti in sottodirectories di
~/go/src.
Modifica di ~/.profile
E' necessario impostare un certo numero di variabili d'ambiente.
Modificare il PATH in ~/.profile:
export GO111MODULE=off
export GOROOT=/opt/go
export GOPATH=$HOME/go
export GOBIN=$GOPATH/bin
export PATH=$GOBIN:$GOROOT/bin:$PATH
La variabile d'ambiente GOROOT indica la locazione in cui si trova la distribuzione di Go. La sua sottodirectory bin contiene il compilatore e le altre utilities e deve trovarsi nel PATH.
La variabile d'ambiente GOPATH indica le directories in cui si trovano i nostri progetti scritti in Go.
La variabile d'ambiente GOBIN indica la locazione in cui verranno installati i programmi eseguibili dei nostri progetti Go.
Dopo il cambiamento di .profile è necessario un relogin per attivare le variabili d'ambiente per tutto il sistema.
Installazione in Windows
- Scaricare da
http://golang.org/dl/p.es. la versione go1.22.1.windows-amd64.msi (circa 120 MB) - Procedere con il Wizard di installazione
- Come locazione di installazione schegliere una directory sotto la directory dell’utente corrente [
%USERPROFILE%], p.es.goroot(creare la directory)C:\Users\USER\goroot - Notare che vengono create/modificate le variabili d’ambiente
GOPATH=C:\Users\USER\goePath=...;%USERPROFILE%\go\bin - In una finestra CMD, verificare l’installazione con
go version
Scaffolding in Windows
Lo scaffolding è la struttura di directories necessarie ai componenti di Go.
Queste directories devono venire create in Windows:
- C:\Users\USER\go\bin
- Contiene gli eseguibili installati
- C:\Users\USER\go\pkg
- Contiene i packages installati
- C:\Users\USER\go\src
- Contiene i sorgenti dei vari progetti Go
Sotto src creare la directory ex per gli esempi: C:\Users\USER\go\src\ex
Ogni esempio è nella sua directory, sotto src/ex, P.es: C:\Users\USER\go\src\ex\010hello
Strumenti di Sviluppo Programmi
Editor
Necessario per la scrittura del codice prima della compilazione,
Raccomandato: Visual Studio Code
- Sia per Linux che Windows
- Aggiungere i plugin: Go, Code Runner
Git
Controllo versioni del codice sorgente:
- Il controllo versione è usato in progetti complessi per testare alternative e per mantenere una storia dello sviluppo del progetto
- Git è disponibile in tutte le versioni di Linux
- In Windows si può usare: Git Bash
- Terminale che emula i comandi Linux e include Git
Visual Studio Code

Scaricare da https://code.visualstudio.com/Download e procedere con l’installazione
La locazione di installazione è: C:\Users\USER\AppData\Local\Programs\Microsoft VS Code
La locazione è automaticamente aggiunta al Path
Installare le estensioni:
Go 0.41.2- Supporto al linguaggio Go
Code Runner 0.12.1- Permette il lancio di programmi da VSC
Assicurarsi che l’indentazione sia di 2 spazi bianchi:
Files -> Preferences -> Settings -> Text Editor -> Formatting -> Format On Save
Files -> Preferences -> Settings -> Commonly Used -> Editor:Tab Size: 2
Aprire la cartella C:\Users\USER\go\src
Git Bash

Fornisce due vantaggi:
- Un terminale con emulazione dei comandi Linux e della shell Bash
- Il controllo di codice sorgente Git
Creare la directory in cui installarlo, p.es: C:\Users\USER\gitroot
Scaricare dal sito https://git-scm.com/downloads e procedere con l’installazione
- Installare nella directory appositamente creata
- Lasciare tutti gli altri default
Configurazione:
- Aprire il terminale Git Bash
- Dare i comandi:
git config --global user.name "Nome Cognome"
git config --global user.email "utente@provider.it"
Ciao Mondo

Preparazione Manuale del Progetto
Ogni applicativo Go è sviluppato al di sotto di una directory di progetto - anche chiamata directory di contesto.
- Contiene il package main, che ha la funzione main(), punto di ingresso dell’applicativo
- Deve esserci una e una sola funzione main()
- Contiene eventuali sottodirectories per i package sviluppati nell’applicativo
- Ogni directory di package ha il nome del package
In Windows generare la directory: C:\Users\USER\go\src\ex\010hello
- Andare in quella directory
- Editare il file main.go
- C’è un solo file del package main in questo semplice applicativo
- Non vi sono altri packages
Preparazione con Visual Studio Code
Creare la cartella ex:
- In tale cartella creare la cartella
010hello - In tale cartella creare il file
010hello.go
Compare una pagina di descrizione dell’estensione di supporto al Go.
Compare inoltre un pop-up in basso a destra, che suggerisce l’installazione di un tool di supporto:
- Selezionare
Install All - Sono tutte le utilities Go a cui VSC accede per gestire il codice, p.es. la riformattazione automatica
- Installare tutte le utilities subito risparmia tempo in seguito
- Impiega un po’ di tempo
Programma
Questo è il classico 'Hello World' in go:
(010hello.go):
// Tutti i file di codice iniziano con la
// dichiarazine package - una sola
// Un package è uno spazio nomi
package main
// Sono importati i moduli che definiscono
// i simboli usati nel file
// E' un errore importare un modulo e non usarlo
import "fmt"
// Ogni eseguibile ha una e una sola funzione main
// Definisce il punto d'ingresso del programma
func main() {
// La funzione Println è nel modulo fmt
// Con iniziale maiuscola - simboli public
// minuscola - private al file che li definisce
fmt.Println("hello world")
}
L'esecuzione comincia dalla funzione main().
La dichiarazione package dichiara un namespace.
Un file sorgente può dichiarare un solo package.
Tutti i file Go devono dichiarare un package.
La funzione main deve essere nel package main, e ve ne può essere solo una nell'intero package.
Il namespace si può estendere ad altri file che dichiarano lo stesso package.
Il compilatore nel risolvere i riferimenti cerca in tutti i file dichiaranti lo stesso package, nella stessa directory di progetto.
Il package main serve per il programma principale, che viene compilato e linkato come eseguibile standalone.
Altri package vengono compilati separatamente e installati al di sotto della directory $GOPATH/pkg. Altri programmi possono poi includere i packages così preparati.
Le funzioni sono globali, cioè visibili in tutto il package.
Compilazione ed Esecuzione
Linea di Comando Linux
Posizionarsi nella directory contenente il programma:
Compilare e lanciare insieme:
go run 010hello.go
Solo compilare:
go build -o hello 010hello.go
- L’opzione
-ospecifica il nome dell’eseguibile - Altrimenti prende il nome dalla directory
Eseguire:
./hello
VSC in Windows
Run diretto da VSC:
- Click destro nella finestra del codice:
Run Code - Si apre la finestra di output col run del nostro codice
Alternativa:
- Aprire la finestra di terminale
View -> Terminal - Cambiare directory:
cd ex\010hello - Compilare e lanciare insieme:
go run 010hello.go
- Solo compilare:
go build -o hello.exe 010hello.go
-
L’opzione
-ospecifica il nome dell’eseguibile, deve avere estensione.exe -
Altrimenti prende il nome dalla directory
-
Eseguire:
hello
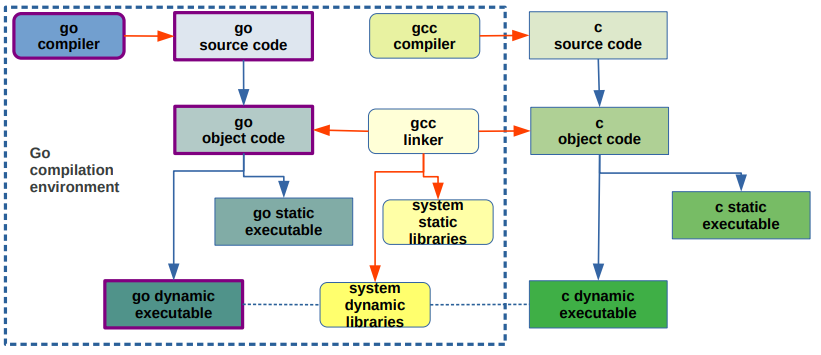
Il file non è sorgente, nè codice intermedio, ma eseguibile nativo Unix ELF. Go è un compilatore, non un interprete.
Il file di default è linkato staticamente, quindi direttamente eseguibile su altri computer della stessa architettura e sistema operativo.
Osservazioni
Organizzazione dei sorgenti
Un programma complesso è solitamente composto da molti file sorgente.
E' opportuno creare una sottodirectory di src che contenga tutti e soli i file del programma in sviluppo.
Terminazione di istruzioni
Le istruzioni NON sono terminate da un punto e virgola ma da un newline (RETURN).
Go inserisce silenziosamente e invisibilmente un punto e virgola al termine di ogni istruzione prima della compilazione del file.
Posizione delle graffe
Seguono lo standard del linguaggio C in versione di Kernighan e Ritchie. Non sono previste alternative, come per esempio in C++.
Il seguente esempio è errato:
func main()
{
fmt.Println("hello world")
}
Il seguente esempio è corretto:
func main(){
fmt.Println("hello world")
}
Per assicurarsi della stesura corretta del file sorgente, incluso le graffe, c'è l'utility gofmt, fornita nel pacchetto Go, da usarsi come:
gofmt file.go
Commenti
Sono accettabili i due tipi di commenti del linguaggio C++:
- inizio con
/*e termine con*/su un qualsiasi numero di linee - inizio con
//e termine a fine linea
I commenti stile /* ... */ non sono innestabili
I commenti sono molto importanti in alcune posizioni chiave, perchè sono sentiti dall'ambiente di produzione di documentazione godoc:
- all'inizio del programma, appena prima della dichiarazione
package - in un programma di package, non main, prima delle funzioni o simboli esportati
Parole Chiave
Non si possono usare come identificativi, come in qualsiasi linguaggio.

Operatori e Delimitatori
Simboli con significato già assegnato, non possono essere parte di identificatori.

Tipi e valori

Naturalmente Go ha più tipi e valori che possono essere assegnati a ciascun tipo.
Per esempio:
(020values.go):
package main
import "fmt"
func main() {
// Concatenazione di stringhe con l'operatore +
fmt.Println("go" + "lang")
// Interi e float
fmt.Println("1+1 =", 1+1)
fmt.Println("7.0/3.0 =", 7.0/3.0)
// Booleani con operatori AND, OR e NOT
fmt.Println(true && false)
fmt.Println(true || false)
fmt.Println(!true)
}
Le costanti stringa sono racchiuse tra doppi apici o apici singoli rovesciati. Le costanti numero sono float a 64 bit di precisione se hanno il punto decimale o l'esponente. Le costanti booleane hanno il valore true o false.
Letterali
La seguente è una piccola sintassi di Backus-Naur per i token letterali di Go.
Letterali interi
int_lit = decimal_lit | octal_lit | hex_lit .
decimal_lit = ( "1" … "9" ) { decimal_digit } .
octal_lit = "0" { octal_digit } .
hex_lit = "0" ( "x" | "X" ) hex_digit { hex_digit }
Letterali float
float_lit = decimals "." [ decimals ] [ exponent ] |
decimals exponent |
"." decimals [ exponent ] .
decimals = decimal_digit { decimal_digit } .
exponent = ( "e" | "E" ) [ "+" | "-" ] decimals
Letterali immaginari
imaginary_lit = (decimals | float_lit) "i"
Letterali per rune
Una runa è il carattere, non la sua rappresentazione in codice Unicode.
rune_lit = "'" ( unicode_value | byte_value ) "'" .
unicode_value = unicode_char | little_u_value | big_u_value |
escaped_char .
byte_value = octal_byte_value | hex_byte_value .
octal_byte_value = `\` octal_digit octal_digit octal_digit .
hex_byte_value = `\` "x" hex_digit hex_digit .
little_u_value = `\` "u" hex_digit hex_digit hex_digit hex_digit .
big_u_value = `\` "U" hex_digit hex_digit hex_digit hex_digit
hex_digit hex_digit hex_digit hex_digit .
escaped_char = `\` ( "a" | "b" | "f" | "n" | "r" | "t" | "v" | `\` | "'" | `"` )
Caratteri speciali
\a U+0007 alert or bell
\b U+0008 backspace
\f U+000C form feed
\n U+000A line feed or newline
\r U+000D carriage return
\t U+0009 horizontal tab
\v U+000b vertical tab
\\ U+005c backslash
\' U+0027 single quote (valid escape only within rune literals)
\" U+0022 double quote (valid escape only within string literals)
Variabili
Le variabili sono dichiarate esplicitamente con la parola chiave var indicandone a seguire il nome poi il tipo.
Per esempio:
(030variables.go):
package main
import "fmt"
func main() {
// Dichiarazione di variabile
// Il tipo è dopo il nome
var a string = "initial"
fmt.Println(a)
// Dichiarazione e assegnazione di più variabili
var b, c int = 1, 2
fmt.Println(b, c)
// Il tipo è dedotto dal valore assegnato
var d = true
fmt.Println(d)
// In asssenza di assegnazione la variabile
// vale lo zero del suo tipo
var e int
fmt.Println(e)
// Abbreviazione di dichiarazione e assegnazione
f := "short"
fmt.Println(f)
}
Le variabili possono essere inizializzate all'istante della dichiarazione, assegnandovi
un valore con l'operatore =.
Le variabili non inizializzate hanno come valore lo zero del loro tipo, i.e.
0, 0.0, "", false.
Si possono dichiarare più varibili in una sola dichiarazione, ed anche inizializzarle nell'ordine rispettivo.
Se vi è un'inizializzazione immediata, in molti casi Go può dedurre il tipo della variabile dal tipo della costante che le viene assegnata.
La parola var può essere omessa se vi è un'inizializzazione immediata ad un tipo noto e si usa l'operatore :=, di dichiarazione e inizializzazione. P.es.:
x := 5
saluto := "Ciao"
raggio := 3.89
condizione := true
è come:
var x int = 5
var saluto string = "Ciao"
var raggio float64 = 3.09
var condizione bool = true
Si può usare l'assegnazione e dichiarazione combinata := solo la prima volta. Tutte le volte seguenti è solo un'assegnazione con =.
Per esempio il seguente codice è errato:
x := 3
.......
x := 5
Doveva essere:
x := 3
.......
x = 5
Una stringa è immutabile. Deve essere inizializzata al momento della dichiarazione e non può più essere assegnata. Non si può solo dichiarare una stringa come in:
string saluto
...
saluto = "Ciao"
Tipi delle Variabili
I tipi come al solito determinano lo storaggio in memoria e la rappresentazione.
| Tipo | Storaggio |
|---|---|
uint8 | 8-bit integers (0 to 255) |
uint16 | 16-bit integers (0 to 65535) |
uint32 | 32-bit integers (0 to 4294967295) |
uint64 | 64-bit integers (0 to 18446744073709551615) |
int8 | signed 8-bit integers (-128 to 127) |
int16 | signed 16-bit integers (-32768 to 32767) |
int32 | signed 32-bit integers (-2147483648 to 2147483647) |
int64 | signed 64-bit integers (-9223372036854775808 to 9223372036854775807) |
float32 | IEEE-754 32-bit floating-point numbers |
float64 | IEEE-754 64-bit floating-point numbers |
complex64 | complex numbers with float32 real and imaginary parts |
complex128 | complex numbers with float64 real and imaginary parts |
byte | alias for uint8 |
rune | alias for int32 |
bool | come uint8 (true oppure false) |
string | allocazione a seconda della lunghezza della costante stringa assegnata |
Costanti
Le dichiarazioni di costanti sono simili alle dichiarazioni di variabili ma con la parola const al posto di var.
L'inizializzazione è obbligatoria.
Non si può riassegnare un valore ad una costante.
Esempio:
(040constants.go):
package main
import "fmt"
import "math"
// Dichiarazione di costante
const s string = "constant"
func main() {
fmt.Println(s)
// Può essere ovunque nel programma
const n = 500000000
// Può avere un valore risultato di espressione
// Internamente registrato a massima precisione
const d = 3e20 / n
fmt.Println(d)
// Non ha un tipo finchè non gli viene dato
// per esempio con un cast
fmt.Println(int64(d))
// oppure dal contesto - qui è un float64
fmt.Println(math.Sin(n))
}
Normalmente, le variabili sono mutabili:
- Sono allocate in memoria statica (stack)
- Si può riassegnare un valore
Alcune variabili sono immutabili (stringhe ed array):
- Sono allocate in memoria dinamica (heap)
- La riassegnazione causa una nuova allocazione
Una costante è immutabile.
La dichiarazione di tipo e l’assegnazione devono essere simultanee.
Una costante numerica non deve avere subito un tipo, ma allora deve subire un cast prima dell’uso.
Cast
Trasformazione di tipo:
variabile1 = tipo(variabile2)
I cast sono un cambiamento di rappresentazione interna di una variabile
- Non tutti i cast sono possibili
- Alcuni cast possono causare perdita di precisione
Il cast è necessario perchè il compilatore esige lo stesso tipo ai due lati di un'assegnazione.
Per esempio:
(types.go):
package main
import "fmt"
func main() {
x := 2.5678
y := 6.56789
var i int
i = y / x
fmt.Println("i= ", i)
}
quando compilato dà l'errore:
./types.go:9:4: cannot use y / x (type float64) as type int in assignment
Occorre invece un cast:
i = int(y / x)
con conseguente perdita di precisione.
Notare che un cast ha lo stesso formato di una funzione, ma non è una funzione.
In altre parole, se vi fossero due struct (vedi oltre, sono quasi come classi) di nome arance e mele, il codice:
var f1 mele
var f2 arance
...
f1 = mele(f2)
tenta di trasformare arance in mele, e dà un errore a runtime. Le struct sono solo quasi come classi, e non esiste il concetto di ereditarietà.
Funzioni e import
Go ha una estesissima libreria di funzioni nel core library, ed è possibile installare altre librerie.
La libreria di default è composta di packages e ogni package contiene svariate funzioni dello stesso tema.
Per poter usare una funzione occorre importare il package che la contiene, con l'istruzione, p.es.:
import "fmt"
Nel nostro caso fmt è un modulo, che possiede molte funzioni di formattazione.
La funzione Println() è una di esse, e stampa il suo argomento stringa a standard output seguito da un newline.
Tutte le funzioni di un package devono essere invocate col nome del package che le contiene, come prefisso separato da un punto.
Si deve usare fmt.Println(), non solo Println().
I packages sono una struttura gerarchica, che usa / come separatore di sottopackage. Per esempio:
import "net/http"
Importare un package non importa i sottopackages (come in Java).
Nell'invocazione delle funzioni il prefisso è solo l'ultimo sottopackage: http.Get()e non net.http.Get().
I packages possono essere non di libreria standard, p.es.
import "stormforce.ac/cryptoutils"
Il compilatore dapprima ricerca tale package nella directory di libreria standard, $GOROOT/pkg, poi cerca il file (nel nostro esempio):
$GOPATH/pkg/linux_amd64/stormforce.ac/cryptoutils.a
Si può dare un alias al nome del package, come in:
import cr "stormforce.ac/cryptoutils"
ed usare cr.Encrypt() anzichè cryptoutils.Encrypt().
Una volta definito un alias occorre usare quello, e non più il nome del package.
I packages sono tipicamente archivi statici, e le loro funzioni sono linkate staticamente all'interno del file eseguibile che le importa.
Non esiste nessuna direttiva tipo export, ma una convenzione obbligatoria:
Tutte le funzioni o variabili il cui nome inizia con una maiuscola sono pubbliche, e note nei programmi che importano il package. Se iniziano con la minuscola sono private, visibili solo nel package che le contiene.
I nomi esportati, essendo globali devono essere univoci nel package.
Le dichiarazioni di import devono essere all'inizio del file, subito dopo la dichiarazione di package. Non possono essere mescolate al codice.
Se si intende pubblicare un proprio package su Internet occorre inventarsi un nome univoco a livello mondiale. Un metodo è di usare il nome di un dominio che ci appartiene. Un altro metodo è di porlo su un sito di registry ben noto, con lo username come identificativo.
I packages si devono scaricare e installare sul computer corrente prima di poterli importare. Questo viene ottenuto col comando
go get package.
Si possono installare direttamente un package da repository in Git, come per esempio:
go get github.com/pippo/pack
Che corrisponde alle operazioni:
cd $GOPATH/src
git clone https://github.com/pippo.pack.git
cd pack
git install
Importazione di più packages
Se si devono importare più package, lo si può fare in due modi. Si può avere una dichiarazione di import per ciascun modulo, p.es.:
import "fmt"
import "mypack"
oppure con un'unica dichiarazione di import:
import (
"fmt"
"mypack"
)
La posizione delle tonde è importante e non può essere diversa da quella indicata.
Ogni modulo importato è su una linea separata.
Si può anche scrivere:
import ( "fmt"; "mypack" )
ove il punto e virgola è un separatore. Questa sintassi è deprecata in favore delle due precedenti.
E' naturalmente errore usare una variabile o funzione di un package senza aver importato tale package.
Ma è altrettanto errore importare un package e non usarlo.
Documentazione
La documentaziione completa di riferimento di tutti i package della core library e di altre librerie usate spesso dalla Community di sviluppatori è disponibile omline alla URL https://golang.org/pkg/.
E' in formato Godoc.
Costrutti di Controllo Flusso

Ciclo:
- Tipici costrutti di altri linguaggi:
while, do … while, for, foreach - Il linguaggio Go ha solo for
- Funziona in più modi e con sintassi leggermente diversa da altri linguaggi
Decisione:
- if-else
- Attenzione alla sintassi molto particolare
Decisione multipla:
- switch
- E’ diverso da altri linguaggi ed è molto usato
- Non è completamente sostituibile con una catena
if ... else if … else - Usato spesso in congiunzione con select
Costrutti di ciclo
for
L'unico costrutto di ciclo è for, che viene in tre varianti:
(050for.go):
package main
import "fmt"
func main() {
// E' l'unico costrutto di ciclo in go
// Tipo 1: for semplice == while(C)
// Non ci sono parentesi per l'argomento
// Le graffe sono obbligatorie
i := 1
for i <= 3 {
fmt.Println(i)
i = i + 1
}
// Tipo 2 == for(C)
// Argomenti separati da ;
// operazioni iniziali; condizione di continuazione;
// operazioni al termine di ciascun ciclo
// più operazioni separate da ,
for j := 7; j <= 9; j++ {
fmt.Println(j)
}
// Tipo 3: loop infinito
for {
fmt.Println("loop")
// uscita dal ciclo
break
}
}
La prima variante è l'equivalente di un while, e richiede sia una inizializzazione della variabile di controllo prima del ciclo che un incremento all'interno del ciclo.
La seconda variante equivale all'equivalente costrutto del linguaggio C, con le tre componenti, separate da punto e virgola:
- operazioni prima del ciclo
- condizione di continuazione del ciclo
- operazioni al termine di ogni ciclo
La terza variante è un loop infinito. Notare che il comando break esce dal ciclo.
Un equivalente comando continue salta le rimanenti istruzioni e rientra in ciclo.
I comandi break e continue sono solitamente governati da un if.
Notare che non si mettono parentesi tonde intorno alla condizione logica.
Notare altresì che le parentesi graffe sono sempre obbligatorie.
Costrutti di Decisione
if-else
(060if-else.go):
package main
import "fmt"
func main() {
// Simile a molti altri linguaggi
// Le graffe sono obbligatorie
if 7%2 == 0 {
fmt.Println("7 is even")
} else {
fmt.Println("7 is odd")
}
// La branca else può non esserci
if 8%4 == 0 {
fmt.Println("8 is divisible by 4")
}
// Assegnazioni possono precedere la condizione
// Variabili locali al costrutto if
if num := 9; num < 0 {
fmt.Println(num, "is negative")
} else if num < 10 {
fmt.Println(num, "has 1 digit")
} else {
fmt.Println(num, "has multiple digits")
}
}
// Note that you don't need parentheses around conditions
// in Go, but that the braces are required.
Non ci vogliono parentesi tonde intorno alla condizione logica dello if.
Le parentesi graffe sono sempre obbligatorie.
La clausola else è opzionale.
Dopo lo else può essere concatenato un ulteriore if.
Una particolarità del Go è la possibilità di porre istruzioni di definizione di variabili dopo la parola chiave if e prima della condizione logica.
Tali variabili sono locali al for.
Costrutti di Decisione Multipla
switch
Il costrutto switch è simile a quello di altri linguaggi discendenti dal C, ma fornisce più possibilità. Esempo:
(070switch):
package main
import "fmt"
import "time"
func main() {
// Costrutto switch
i := 2
fmt.Print("write ", i, " as ")
// Variabile di paragone
switch i {
// Valore con cui viene paragonata
case 1:
fmt.Println("one")
// Non c'è 'cascading' come in C
// Non c'è il break
case 2:
fmt.Println("two")
case 3:
fmt.Println("three")
}
switch time.Now().Weekday() {
// Più valori di paragone separati da ,
case time.Saturday, time.Sunday:
fmt.Println("it's the weekend")
// default soddisfa sempre
// logicamente è l'ultimo paragone
default:
fmt.Println("it's a weekday")
}
// Costrutto equivalente a if-else
t := time.Now()
fmt.Println(t)
// Manca la variabile di paragone
switch {
// Il valore è booleano
case t.Hour() < 12:
fmt.Println("it's before noon")
default:
fmt.Println("it's after noon")
}
}
Sia l'argomento dello switch che l'argomento del case non sono limitati a costanti o variabili, ma possono essere espressioni, le quali però devono avere un valore preciso.
Se lo switch non ha argomenti, allora ogni case deve avere per argomento un'espressione condizionale (booleana). Il costrutto equivale in questo caso ad un for.
case può coprire più casi, separati da una virgola
Al termine del paragrafo di un case vi è un'uscita dal costrutto switch,non è necessario un break.
Il caso default non ha argomenti, è opzionale, e va naturalmente posto per ultimo.
Strutture Dati

Il linguaggio Go possiede solo tre strutture dati primitive, simili di nome a quelle di altri linguaggi, ma in realtà con caratteristiche proprie.
Alcune compiono un'allocazione di memoria statica, nello stack, altre sono allocate in memoria dinamica, nello heap.
Le strutture dati sono:
- arrays
- slices
- maps
Il costrutto range itera su tutti gli elementi di una struttura dati, che possono esser di qualsiasi tipo.
Array
Un array è un tipo dati di lunghezza fissa contenente un blocco contiguo di elementi dello stesso tipo.
- L’accesso agli elementi è tramite un indice
- Gli elementi sono mutabili, ma la dimensione dell’array è fissa
- Gli elementi non inizializzati hanno il valore zero del loro tipo
- Gli array sono allocati sullo stack
nums := [6]int{10, 36, 4, 44}

Esempio:
(080arrays.go):
package main
import "fmt"
func main() {
// Array: sequenza numerata di elementi di lunghezza data
// lunghezza tra quadre
// tipo attaccato a quadra chiusa
// Creati nello stack
var a [5]int
// Stampa tutti gli elementi dell'array
// Ogni elemento non assegnato vale zero
fmt.Println("emp:", a)
// Assegnazione valore ad un elemento tramite indice
// Gli indici vanno da 0 a lunghezza
a[4] = 100
fmt.Println("set:", a)
fmt.Println("get:", a[4])
// Funzione di lunghezza dell'array
fmt.Println("len:", len(a))
// Assegnazione di valori alla dichiarazione
// Si possono assegnare anche solo i primi valori
b := [5]int{1, 2, 3}
fmt.Println("dcl:", b)
// Copia di un array
// poichè è nello stack viene copiato per valore
c := b
// La copia è diversa dall'originale
c[0] = 0
fmt.Println("b: ", b)
fmt.Println("c: ", c)
// Creazione di un array vuoto
// inutile perchè non estendibile
var z[0]int
fmt.Println("z: ", z)
fmt.Println("len(z): ", len(z))
// Array pluridimensionale
var twoD [2][3]int
for i := 0; i < 2; i++ {
for j := 0; j < 3; j++ {
twoD[i][j] = i + j
}
}
fmt.Println("2d: ", twoD)
}
Osservazioni
Un array è dichiarato come: var a [5]int, uve a è una variabile array di 5 elementi di tipo intero.
Se gli elementi non sono esplicitamente inizializzati, vengono implicitamente assegnati allo zero del loro tipo.
Il riferimento ad un elemento dell'array è tramite un indice intero:
a[4] = 100
Come in tutti i linguaggi derivati dal C gli indici vanno da zero a uno meno della dimensione dell'array. L'accesso ad un elemento fuori dai confini dell'array (overflow) genera un errore di compilazione o una eccezione a runtime.
Stampare un array produce una lista dei suoi elementi tra parentesi quadre e separati da spazi.
La funzione len(a) ritorna la lunghezza dell'array a.
Un array può essere inizializzato all'atto della dichiarazione, come in
b := [5]int{1, 2, 3, 4, 5}
La parola var può essere omessa.
La dimensione si può omettere se sostituita con ...
a := [...]int{1, 2, 3}
Il tipo dell'array (qui: int) deve comunque essere indicato.
Non è necessario che il tipo segua immediatamente le quadre chiuse, si possono porre spazi.
Gli array possono avere più dimensioni, come in:
var twoD [2][3]int
Tutte le dimensioni sono dello stesso tipo.
In realtà il Go, come il C, registra internamente un unico array consecutivo, anche se controlla gli indici.
Cioè non è vero che si possa usare twoD[0][3] come equivalente di twoD[1][0].
Gli array, come in C, sono allocati nello stack.
Copia di un Array
Per valore, non per riferimento. Non esiste riferimento ad un array:
a := [...]string{"Alice", "Bob", "Charlie"}
b := a // una copia di a è assegnata a b
b[0] = "Tom"
fmt.Println("a is ", a)
fmt.Println("b is ", b)
produce l’output
a is [Alice Bob Charlie]
b is [Tom Bob Charlie]
Slice
Una slice è un involucro intorno ad un array. Possiede:
reference. riferimento all’elemento iniziale dell’array- default: primo elemento
length- dimensione della slice- default: fino alla fine dell’array
capacity- capacità o spazio preallocato per la slice>= length
b := a[2, 5]
Da 2 incluso fino a 5 escluso.
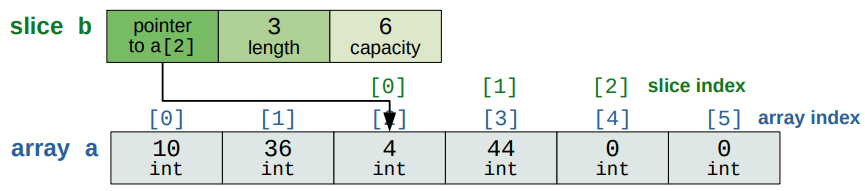
Mentre un array ha allocazione statica, una slice ha allocazione dinamica, cioè nello heap.
Le slice vengono usate, per esempio, come segue:
(090slices.go):
package main
import "fmt"
func main() {
// Creazione di slice di tre elementi iniziali
// Allocata in memoria dinamica - heap
// Gli elementi sono zero di default
s := make([]string, 3)
fmt.Println("emp:", s)
// Uso simile ad array
s[0] = "a"
s[1] = "b"
s[2] = "c"
fmt.Println("set:", s)
fmt.Println("get:", s[2])
// Funzione di lunghezza della slice
fmt.Println("len:", len(s))
// Estensione di una slice
// Può silenziosamente riallocare memoria
// pertanto è necessaria un'assegnazione alla
// nuova locazione in memoria (s è un puntatore implicito)
s = append(s, "d")
s = append(s, "e", "f")
fmt.Println("apd:", s)
// Semplice assegnazione copia solo il puntatore
// poichè sono nello heap la copia è per riferimento
p := s
// Cambiare una slice cambia anche l'altra
p[1] = "x"
fmt.Println("old: ", s)
fmt.Println("new: ", p)
// Copia di una slice
// Crea nuova slice
c := make([]string, len(s))
// copia su destinazione di sorgente
copy(c, s)
// le due slice sono ora differenti
c[1] = "y"
fmt.Println("old: ", s)
fmt.Println("copy: ", c)
// Operatore di slice - fetta
// Dal primo indicato incluso all'ultimo indicato escluso
l := s[2:5]
fmt.Println("sl1:", l)
// Dal primo assoluto incluso all'ultimo indicato escluso
l = s[:5]
fmt.Println("sl2:", l)
// Dal primo indicato incluso all'ultimo assoluto
l = s[2:]
fmt.Println("sl3:", l)
// Dichiarazione e inizializzazione simultanea di slice
// Se tra quadre non c'è dimensione è una slice
// se c'è è un array
t := []string{"g", "h", "i"}
fmt.Println("dcl:", t)
// Creazione di una slice vuota
// Le graffe sono obbligatorie
z := []string{}
// Una variabile dichiarata deve sempre essere usata
fmt.Println(">>", z, "<<")
// Slice multidimensionale
// Entrambe le dimensioni sono dinamiche:
// puntatori a puntatori
twoD := make([][]int, 3)
for i := 0; i < 3; i++ {
innerLen := i + 1
twoD[i] = make([]int, innerLen)
for j := 0; j < innerLen; j++ {
twoD[i][j] = i + j
}
}
fmt.Println("2d: ", twoD)
}
Una slice deve essere allocata in memoria dinamica, con l'operatore make, simile al new di C++ e Java:
s := make([]string, 3)
Occorre indicare il tipo degli elementi della slice e la dimensione iniziale dell'allocazione.
Una slice inizialmente è vuota, contiene elementi azzerati.
Si possono settare e accedere a elementi della slice iniziale come per un array,e la funzione len() conosce la dimensione della slice.
E' possibile estendere la slice iniziale con la funzione append() che prende almeno due argomenti: il nome della slice e gli elementi aggiunti alla fine.
Si può copiare una slice in un'altra slice che abbia almeno la dimensione della prima.
Si chiama slice perchè è possibile estrarre una fetta della slice originale in un'altra variabile, dichiarata e inizializzata dello stesso tipo. Nell'esempio:
a := s[2:5]
a contiene gli elementi di s a partire dall'elemento di indice 2 (il terzo) incluso e a terminare all'elemento di indice 5 (il sesto) escluso.
Se l'inizio della fetta - prima dei due punti - non è indicato, si intende il primo elemento incluso. Se la fine della fetta - dopo i due punti - non è indicato, si intende l'ultimo elemento incluso.
Si può avere una slice di slices. Per esempio con la dichiarazione:
twoD := make([][]int, 3)
si crea una slice di tre slices.
La dimensione esterna è di tre elementi (slices). la dimensione di ogni elemento interno (slice) non è specificata, e possono essere slice interne di dimensione differente.
Ogni slice interna deve a sua volta essere costruita con, p.es:
twoD[i] = make([]int, innerLen)
Si nota, per chi proviene dal C o C++, la presenza nascosta di puntatori a memoria allocata dinamicamente.
Esempio 1
(091slice1.go):
package main
import "fmt"
func main() {
a := [...]int{0, 10, 20, 30, 40, 50, 60, 70} // array
fmt.Println(len(a)) // 8
fmt.Println(a)
b := a[2:6] // da 2 a 6 escluso
fmt.Println(len(b), cap(b)) // 4 6
fmt.Println(b)
fmt.Println(b[1]) // indicizza una slice, non un array
c := a[5:] // da 5 alla fine
fmt.Println(c)
d := a[:5] // dall’inizio a 5 escluso
fmt.Println(d)
e := a[:] // la slice copre tutto a
fmt.Println(e)
f := a // array, non slice
fmt.Println(f)
g := d[:3] // slice di slice
fmt.Println(g)
h := []int{1, 2, 3, 4} // slice con array sottostante
fmt.Println(h)
fmt.Println(len(h), cap(h)) // 4 4
}
Esempio 2
append aggiunge elementi alla fine della slice:
- Length e capacity sono estese
- Capacity può essere maggiore di length
(092slice.app.go):
package main
import "fmt"
func main() {
sl1 := []string{"alpha", "bravo", "charlie"}
fmt.Println("old slice : ", sl1)
fmt.Println("old length : ", len(sl1))
fmt.Println("old capacity : ", cap(sl1))
sl1 = append(sl1, "delta")
fmt.Println("new slice : ", sl1)
fmt.Println("new length : ", len(sl1))
fmt.Println("new capacity : ", cap(sl1))
}
Esempio 3
Svuotare una slice. Due modi:
[092slice-del.go):
package main
import "fmt"
func main() {
a := []string{"A", "B", "C", "D", "E"}
fmt.Println(a, len(a), cap(a)) // [A B C D E] 5 5
a = nil // tootalmente ripulita
fmt.Println(a, len(a), cap(a)) // [] 0 0
b := []string{"A", "B", "C", "D", "E"}
b = b[:0] // slice con length zero, ma ha ancora capacity
fmt.Println(b, len(b), cap(b)) // [] 0 5
}
Esempio 4
Rimuovere un elemento. La slice deve essere ricostruita.
(094slice-rem.go):
package main
import "fmt"
func main() {
strSlice := []string{"Canada", "Japan", "Germany", "Italy"}
fmt.Println(strSlice)
// append di più elementi
strSlice = append(strSlice, "UK", "France", "Spain")
fmt.Println(strSlice)
// rimuove l’elemento con indice 2
strSlice = append(strSlice[:2], strSlice[3:]...)
fmt.Println(strSlice)
// rimuove il primo elemento
strSlice = strSlice[1:]
fmt.Println(strSlice)
// rimuove l’ultimo elemento
strSlice = strSlice[:len(strSlice)-1]
fmt.Println(strSlice)
}
Maps
Le maps sono simili agli array associativi di altri linguaggi come il Perl.
Sono quindi dei valori indicizzati da chiavi. Il tipo della chiave e quello del valore possono essere diversi.
Esempio:
(100maps.go):
package main
import "fmt"
func main() {
// Una map è un tipo associativo = hash
// Costruita in memoria dinamica
// map[chiave]valore - niente spazi
m := make(map[string]int)
// Assegnazione di valore a chiave
m["k1"] = 7
m["k2"] = 13
// Stampa dell'intera map
// Ordine casuale
fmt.Println("map:", m)
// Valore di una chiave
v1 := m["k1"]
fmt.Println("v1: ", v1)
// Dimensione della map
fmt.Println("len:", len(m))
// deallocazione di un elemento tramite chiave
delete(m, "k2")
fmt.Println("map:", m)
// Un elemento mai assegnato vale zero
// un elemento assegnato a zero vale zero
// Per distinguere c'è un secondo valore
// di ritorno, opzionale, booleano
m["k3"] = 0
x1, exists := m["k3"]
fmt.Print("k3: ")
if exists {
fmt.Println(x1)
} else {
fmt.Println("missing")
}
x2, exists := m["k4"]
fmt.Print("k4: ")
if exists {
fmt.Println(x2)
} else {
fmt.Println("missing")
}
// Dichiarazione e inizializzazione simultanea di map
n := map[string]int{"foo": 1, "bar": 2}
fmt.Println("map:", n)
}
Le mappe sono strutture in memoria dinamica e vanno quindi allocate:
m := make(map[string]int)
Tra parentesi quadre è il tipo della chiave, oltre è il tipo del valore. In questo esempio la chiave è di tipo string e il valore di tipo int.
La dimensione della mappa non è determinata in fase di dichiarazione, ma si espande automaticamente.
L'allocazione avviene con un'assegnazzione:
m["k1"] = 7
Sia la chiave che il valore vengono creati al momento dell'allocazione.
La stampa di una mappa fornisce in output tutte le coppie chiave-valore.
La rimozione di un elemento avviene con la funzione delete tramite la chiave:
delete(m, "k2")
L'accesso ad un elemento di una mappa ritorna opzionalmente un secondo valore, booleano, che indica se l'elemento di mappa è presente o no.
_, prs := m["k2"]
In questo esempio il valore viene ignorato, ma è obbligatorio indicarlo con un underscore.
L'allocazione e inizializzazione di una mappa possono essere combinate con la sintassi:
n := map[string]int{"foo": 1, "bar": 2}
La sintassi è simile a JSON.
Range
Il costrutto range è un iteratore su una struttura dati, sia essa un array, slice o map.
Equivale al comando foreach di altri linguaggi.
Esempio
(11orange.go):
package main
import "fmt"
func main() {
// range è un iteratore su collezioni = foreach
// ritorna due valori
// Sugli array il secondo è il valore dell'elemento
nums := []int{2, 3, 4}
sum := 0
// Ignoriamo il primo valore col segnaposto _
for _, num := range nums {
sum += num
}
fmt.Println("sum:", sum)
// Su array e slice il primo valore è l'indice
for i, num := range nums {
if num == 3 {
fmt.Println("index:", i)
}
}
// Sulle map il primo valore è la chiave
kvs := map[string]string{"a": "apple", "b": "banana"}
for k, v := range kvs {
fmt.Printf("%s -> %s\n", k, v)
}
// Un carattere di una stringa si chiama runa
// Con range sulle stringhe il primo è l'indice di runa
// e il secondo è il valore Unicode della runa
string1 := "golang"
fmt.Print(string1, "= ")
for i, c := range string1 {
fmt.Print(i, ": ", c, ", ")
}
fmt.Println()
// Giappone
string3 := "日本国"
fmt.Print(string3, "= ")
for i, c := range string3 {
fmt.Print(i, ": ", c, ", ")
}
fmt.Println()
// Egitto
string4 := "مَصر"
fmt.Print(string4, "= ")
for i, c := range string4 {
fmt.Print(i, ": ", c, ", ")
}
fmt.Println()
// NB Il trattamento stringhe funziona su tutto Unicode
// ma il display dipende dalla disponibilità del font
}
Esercizi

Esercizio 101
Produrre in output la tabellina pitagorica:
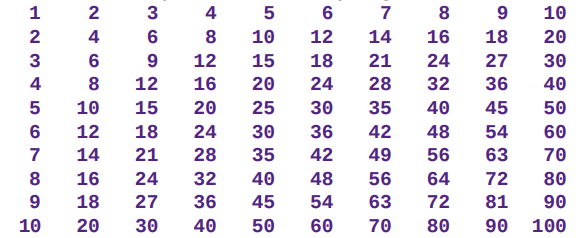
Suggerimento: per l’allineamento vedere la funzione fmt.Printf() - come in C
Rif: https://golang.org/pkg/fmt/
Esercizio 102
Una stringa può essere vista come una slice di bytes.
Data la stringa “supercalifragilisticespiralidoso”
- Stampare i primi 10 caratteri
- Provare a stampare i primi 100 caratteri
- Stampare gli ultimi 10 caratteri
- Caricare ogni byte della stringa in un array e stampare l’array
Ripetere con la stringa “Российская Федерация”
Creare un array di byte con i valori
{230, 151, 165, 230, 156, 172}
- Creare una slice di byte vuota e appendere i byte dell’array
- Visualizzarla come slice
- Visualizzarla come stringa (cast)
Esercizio 103
Caricare i numeri interi da 0 a 99 in un array di 100 interi.
- Visualizzare l’array con un ciclo di for
- Visualizzare i primi 200 elementi dell’array con un ciclo di for
- Visualizzare l’array con range
Funzioni e Closures
Le funzioni sono una componente fondamentale della sintassi del Go.
Il loro comportamento ha alcune differenze rispetto a linguaggi più tradizionali, per esempio possono tornare più valori.
Vi sono funzioni variadiche, cioè che accettano un numero variabile di parametri.
Come in altri linguaggi sono supportate funzioni ricorsive. Ogni istanza di invocazione di funzione crea un frame nuovo nello stack.
I parameri e i valori di ritorno delle funzioni possono essere gestiti sia per valore che per riferimento.
Le closure costituiscono una forma di funzioni anonime. Una funzione può ritornare come valore un'altra funzione.
Funzioni

Le funzioni sono blocchi di istruzioni.
Le funzioni possono o no ricevere parametri all'atto del lancio, e ritornano o no uno o più valori.
Una funzione ha una segnatura, determinata dalla lista dei tipi di parametri e dal tipo di ritorno.
Le funzioni sono solo definite, non dichiarate (eccezione: all'interno di interfacce).
Una funzione può essere definita ovunque nel package che la contiene, non necessariammente prima del suo uso.
Le funzioni non nel package corrente devono avere il nome prefissato dal nome del package e da un punto, come in fmt.Println, e il package deve essere importato.
Esempio
(120functions.go):
package main
import "fmt"
func main() {
// Invocazione di funzione
// con i parametri attuali
res := plus(1, 2)
fmt.Println("1+2 =", res)
res = plusPlus(1, 2, 3)
fmt.Println("1+2+3 =", res)
}
// Non possono esistere due funzioni con lo stesso
// nome nello stesso package
// Una funzione è risolta ovunque nel package
// Non occorre dichiararla prima di invocarla
// se l'intero package è compilato insieme
// Tutti i parametri hanno un tipo a seguire
// ed è indicato il tipo del valore di ritorno
// Si chiamano parametri formali e sono locali
func plus(a int, b int) int {
// Il return deve essere esplicito
return a + b
}
// Più parametri dello stesso tipo possono essere aggregati
func plusPlus(a, b, c int) int {
return a + b + c
}
I parametri sono posizionali, cioè vanno passati al momento dell'invocazione nello stesso ordine in cui sono stati definiti.
Non tutti i parametri devono essere passati all'atto dell'invocazione, gli ultimi possono esser opzionali, ma non è possibile settare parametri di default, come in:
// Codice errato
func drawline(x1, y1, x2, y2 int, thickness int = 1, dashed bool){
...
}
In questo esempio si può omettere dashed e il default è false. Si può anche omettere thickness, e il default è 0.
Se si vuole indicare dashed, occorre passare anche thickness.
Se una funzione è definita come ritornante un valore, il return con tale valore è obbligatorio.
Se una funzione non ritorna un valore, il return non deve avere valore. Se il return manca, avviene automaticamente alla fine del blocco di istruzioni.
Non si possono avere parametri formali nella definizione della funzione, che non siano poi utilizzati.
Se un parametro formale è dichiarato, deve esserci nel codice qualche invocazione della funzione che passa il relativo parameto attuale.
Valori Multipli di Ritorno
Una funzione può ritornare più valori , che sono assegnati rispettivamente alle variabili riceventi.
Esempio
(130multiple-return-values.go):
package main
import "fmt"
// Funzione che ritorna due valori interi
func vals() (int, int) {
return 3, 7
}
func main() {
// Invocazione di funzione con due valori
// di ritorno
a, b := vals()
fmt.Println(a)
fmt.Println(b)
// il primo valore, come segnaposto
_, c := vals()
fmt.Println(c)
}
// TODO: named return parameters
// TODO: naked returns
Ritorno di errore
Per convenzione l'ultimo valore ritornato è un errore. Questo da modo di affrontare situazioni non corrette senza causare un panic a runtime.
Il Go non ha gestione eccezioni, cioè non esistono segmenti try ... catch come altri linguaggi. Seguendo la buona pratica di fornire errori nei valori di ritorno delle funzioni e di testarli nel codice chiamante si impedisce il verificarsi di situazioni altrimenti fatali.
(131-error-return.go):
package main
import "fmt"
import "errors"
func main() {
res, err := divide(10, 0)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(res)
}
}
func divide(x, y int) (res int, err error) {
if y == 0 {
return 0, errors.New("divide by zero")
}
return x / y, nil
}
Notare che un error è un oggetto complesso del package errors. Come tale va creato con la funzione new.
Potevamo certo decidere in questo programma di usare una stringa o un booleano, ma è sempre meglio conformarsi a features già esistenti.
Funzioni Variadiche
Una funzione variadica accetta un numero indefinito di argomenti tutti dello stesso tipo.
Può accettare anche argomenti definiti, che devono essere dichiarati prima di quelli variadici: solo l'ultimo argomento può essere variadico, e ve ne può essere uno solo.
(140variadic-functions.go):
package main
import "fmt"
// Funzione variadica
// Un numero qualsiasi di argomenti dello stesso tipo
func sum(nums ...int) {
fmt.Print(nums, " ")
total := 0
// range scandisce gli argomenti
// Il primo parametro è l'indice
for _, num := range nums {
total += num
}
fmt.Println(total)
}
func main() {
// Invocazione di funzione variadica
sum(1, 2)
sum(1, 2, 3)
// Una funzione variadica accetta come parametro
// attuale una collezione
nums := []int{1, 2, 3, 4}
sum(nums...)
}
Molte funzioni di libreria sono variadiche, p.es. fmt.Printf().
L'argomento formale variadico ha i tre punti prima del tipo, senza spazi.
L'argomento attuale variadico ha i tre punti dopo il nome, senza spazi.
Closure
Si può definire una variabile che ha per valore una funzione, come nel segmento di codice:
func main() {
add := func(x, y int) int {
return x + y
}
fmt.Println(add(1,1))
}
Questo è un esempio di closure, ed implica che le funzioni sono oggetti primari alla stregua di variabili.
Un altro esempio di segmento di codice può essere:
func main() {
x := 0
increment := func() int {
x++
return x
}
fmt.Println(increment())
fmt.Println(increment())
}
Un'altra versione di closure è una funzione che ritorna un'altra funzione, come nel programma seguente.
(150closures.go):
package main
import "fmt"
// Una funzione può ritornare un'altra funzione
// inteSeq ritorna una funzione func che ritorna un int
// Questa è una funzione anonima
func intSeq() func() int {
i := 0
return func() int {
i += 1
return i
}
}
func main() {
// Qui nextInt è una funzione
nextInt := intSeq()
// i viene inizializzato a zero
// Esempi di invocazione
// La funzione anonima mantiene il suo stato statico
// la variabile i non viene risettata
fmt.Println(nextInt())
fmt.Println(nextInt())
fmt.Println(nextInt())
// Un'invocazione di intSeq con altra assegnazione
// crea un'altra funzione anonima diversa, col suo stato
newInts := intSeq()
fmt.Println(newInts())
}
// E' un modo per simulare l'indicazione 'static'
// di C++ e Java
Ricorsione
Ogni linguaggio basato su funzioni supporta il concetto di ricorsione.
Ogni chiamata a funzione genera un nuovo push di stack frame e ogni ritorno ne causa il pop.
Uno stack frame è un ambito (scope) locale di variabili.
All'atto dell'uso una variabile viene ricercata a partire dal frame corrente e, se non trovata, la ricerca prosegue nei frame sottostanti.
Ad ogni pop di stack frame, quando cioè una funzione ritorna, le variabili locali ivi create rimangono orfane, ma non c'è bisogno di deallocarle esplicitamente, ci pensa il garbage collector.
Esempio
(160recursion.go):
package main
import "fmt"
// Ad ogni invocazione viene creato un nuovo stack frame
// return distrugge lo stack frame corrente
func fact(n int) int {
if n == 0 {
return 1
}
return n * fact(n-1)
}
func main() {
fmt.Println(fact(7))
}
Evidentemente il numero di frame nello stack è finito, quindi una ricorsione troppo profonda ne può causare l'esaustione.
E' anche da notare che la ricorsione impone richieste di risorse notevoli. Solo alcuni problemi sono naturalmente risolvibili con ricorsione, in altri casi è conveniente pensare ad un algoritmo che usi iterazione.
Esercizi

Esercizio 201
Scrivere una funzione che ritorna il coseno di un angolo, quando l’argomento viene passato in gradi, col vincolo che i gradi devono essere tra 0 e 90.
Se i gradi passati sono fuori dall’intervallo consentito, la funzione ritorna un errore.
Creare quindi una tabella che mostra i gradi e il loro coseno da 0 a 90 gradi con intervallo di 10 gradi.
Suggerimenti:
- La funzione
math.Cos()prende il suo argomento in radianti, non in gradi. - Nella tabella, arrotondare l’output a 4 cifre decimali con
fmt.Printf()
Caratteristiche Object Oriented
Il linguaggio Go non ha tutta l'impalcatura di gestione oggetti dei linguaggi C++ o Java, manca per esempio totalmente il concetto di classe e di ereditarietà.
Nonostante ciò il Go possiede caratteristiche inerenti la gestione di oggetti, e pone particolare accento su interfacce e tipi.
Esiste il concetto di metodo, cioè di funzione che si può applicare solo ad un determinato tipo.
Puntatori
Mentre una variabile contiene un valore, un puntatore contiene un indirizzo, ovvero un riferimento ad un valore.
In Go una variabile può essere gestita o per valore, oppure per riferimento, come in C e C++.
Il simbolo che esprime l'idirizzo di una variabile è &, quello che esprime l'accesso indiretto tramite puntatore (dereferenziazione) è *.
Entrambi sono operatori prefissi e non si mettono mai spazi tra loro e la variabile operata.
In Java non esistono simboli espliciti per i puntatori, perchè le variabili o sono solo gestite per valore o solo per riferimento.
Esempio
Il seguente programma illustra l'uso di base dei puntatori.
(171-punt.go):
package main
import "fmt"
func main() {
var a int = 5
// var p *int
// var q *int
p := &a
fmt.Printf("valore di a: %d\n", a)
fmt.Printf("indirizzo di a: %d\n", &a)
fmt.Printf("valore di p: %d\n", p)
fmt.Printf("valore di *p: %d\n", *p)
// fmt.Printf("valore di *q: %d\n", *q)
}
Il codice var p *int asserisce che p è un puntatore ad interi. Il compilatore deve sapere sia che p è un puntatore, cioè un riferimento a variabile, sia di che tipo è la variabile a cui si riferisce.
Il codice p = &a inizializza il puntatore p con l'indirizzo di a. Se il membro sinistro di un'assegnazione è un puntatore, il membro destro deve essere un indirizzo.
Si può anche scrivere p := &a e il compilatore deduce il tipo di puntatore dal tipo della variabile.
Un puntatore deve essere sempre, nell'ordine:
- dichiarato
- inizializzato
- usato
Un puntatore dichiarato ma non ancora inizializzato vale nil, cioè l'idirizzo di memoria 0.
In Linux, l'indirizzo zero non è mai allocato nella mappa di segmenti di nessun processo. Il tentativo di dereferenziare l'indirizzo zero produce l'errore runtime Segment Violation con conseguente panic.
Scommentando i due commenti sopra si può vedere questo effetto.
Funzioni con puntatori
Il seguente programma illustra l'uso di funzioni che prendono un putatore come parametro.
Una funzione con parametro normale (non puntatore), che modifica il valore di tale parametro, ha modificato una copia e non il valore nel codice invocante.
Se il parametro di una funzione è un puntatore, la sua modifica è anche la modifica del valore del codice chiamante.
(170pointers.go):
package main
import "fmt"
// La funzione riceve come argomento un valore intero
// Passaggio parametri per copia o valore
func zeroval(ival int) {
ival = 0
}
// La funzione riceve come argomento un puntatore a intero
// Passaggio parametri per riferimento
func zeroptr(iptr *int) {
*iptr = 0
}
func main() {
i := 1
fmt.Println("initial:", i)
// Invocazione per valore
zeroval(i)
fmt.Println("zeroval:", i)
// Invocazione per riferimento
// '&i' è l'indirizzo di i
// Se il parametro formale è un puntatore
// il parametro attuale deve essere un indirizzo
zeroptr(&i)
fmt.Println("zeroptr:", i)
// E' possibile stampare l'indirizzo
fmt.Println("pointer:", &i)
// Gli indirizzi sono già stampati in esadecimale, come da
fmt.Printf("hex: %x\n", &i)
// se si vuole stamparli in decimale:
fmt.Printf("dec: %d\n", &i)
}
// Il comportamento è come quello del linguaggio C
// La funzione Printf è come quella equivalente del C
Le tre fasi di impiego di un puntatore qui sono:
- dichiarazione - nella dichiarazione di parametro della funzione
- inizializzazione - nel passaggio di parametri alla invocazione della funzione: se il parametro formale è un puntatore, il parametro attuale deve essere un indirizzo
- uso - nel codice della funzione
Una funzione deve ricevere un parametro formale per riferimento (un puntatore) quando è suo compito modificare (scrivere) il valore originale del corrispondente parametro attuale. Dovrebbe invece sempre ricevere un parametro formale per valore quando deve solo leggere senza modificare il corrispondente parametro attuale.
new
Una variabile gestita tramite puntatore può essere generata con la funzione built-in del linguaggio new, come nel segmento di codice:
func one(xPtr *int) {
*xPtr = 1
}
func main() {
xPtr := new(int)
one(xPtr)
fmt.Println(*xPtr) // x vale 1
}
new vuole sapere dal suo argomento quanta memoria dinamica allocare e ritorna un puntatore a tale memoria dinamica allocata. L'argomento di new può essere un tipo, nel qual caso viene allocata esattamente la memoria necessaria per lo storaggio di variabili di quel tipo.
In effetti è raro usare new con tipi semplici, ma è molto comune con struct e con slice e map.
Swap con puntatori e senza
Il metodo tradizionale di compiere lo swap di due valori è tramite una funzione che usa puntatori. Si può ancora procedere in tale modo.
Go ha un nuovo metodo molto più semplice.
(172-swap-punt.go):
package main
import "fmt"
func swap(x, y *int) {
t := *x
*x = *y
*y = t
}
func main() {
a := 10
b := 20
fmt.Println("Metodo antico")
fmt.Printf("Prima: a=%d, b=%d\n", a, b)
swap(&a, &b)
fmt.Printf("Dopo: a=%d, b=%d\n", a, b)
a = 10
b = 20
fmt.Println("Metodo nuovo")
fmt.Printf("Prima: a=%d, b=%d\n", a, b)
b, a = a, b
fmt.Printf("Dopo: a=%d, b=%d\n", a, b)
}
Fantastico! Non è nemmeno una funzione che ritorna due valori, che già è impensabile in C, C++ e Java. E' un'assegnazione multipla combinata, che nessuno dei tre citati linguaggi neanche si sogna.
Structs
Oltre ai tipi semplici predefiniti da Go è possibile aggiungere ai programmi altri tipi dati.
I tipi dati composti principali sono le struct.
La loro struttura interna è molto simile a quella del linguaggio C. Sono una lista di campi ciascuno col nome e tipo.
Va prima dichiarato il tipo, poi le variabili che sono di questo tipo. L'accesso ai campi della struct è tramite l'operatore punto.
type nome struct {
nome1 tipo
nome2 tipo
...
}
...
var1 := nome
...
var1.nome1 = valore
...
Una struct è allocata staticamente in memoria, nello stack, e può essere usata per valore o per riferimento, cioè è possibile avere puntatori ad una struct.
Esempio
(180structs.go):
package main
import "fmt"
// Una struct è un nuovo tipo composto da
// campi interni ciacuno con un tipo proprio
// Le struct devono venire dichiarati prima dell'uso
type person struct {
name string
age int
}
func main() {
// Creazione di una variabile di tipo person
// I parametri sono nell'ordine di definizione
p := person{"John", 42}
fmt.Println(p)
// Uso immediato di un person anonimo
fmt.Println(person{"Bob", 20})
// Si possono inizializzare i campi col nome
// anche in un ordine diverso
fmt.Println(person{age: 30, name: "Alice"})
// I campi omessi valgono zero
fmt.Println(person{name: "Fred"})
// Accesso ai singoli campi con l'operatore punto
s := person{name: "Sean", age: 50}
fmt.Println(s.name)
// Anche tramite puntatore si usa l'operatore punto
// sp è un puntatore a s
sp := &s
// Accesso alcampo age; in C era sp->age
fmt.Println(sp.age)
// Assegnazione di un valoread un campo
// Le struct sono mutevoli
sp.age = 51
fmt.Println(sp.age)
// Uno `&` prefisso ritorna un puntatore alla struct
a := &person{name: "Ann", age: 40}
// a viene automaticamente dereferenziato (<> C)
// ma viene indicato che è un indirizzo
fmt.Println("a: ", a)
// Per stampare l'indirizzo di a (<> C)
fmt.Println("addr(a): ", &a)
}
Le struct sono l'equivalente dei record in altri linguaggi di programmazione.
In Go non esistono classi, ma una struct si può considerare come la parte di una classe che contiene gli attributi. I suoi metodi sono dichiarati fuori dalla struct.
Non esiste ereditarietà.
Metodi

Un metodo è una funzione che si applica solo ad un determinato tipo.
La sintassi è:
func (var tipoinvocante) nomemetodo() tiporitorno { ... }
Qui var è l'identificatore formale del (pseudo)oggetto invocante, e può essere per valore o riferimento.
Un esempio (segmento di codice invocante - pseudocodice) può essere:
var x tipoinvocante
var y tiporitorno
y = x.nomemetodo()
L'oggetto x invoca il nomemetodo con l'operatore punto, come in altri linguaggi propriamente Object Oriented.
Un programma più completo è il seguente.
(19methods.go):
package main
import "fmt"
type rect struct {
width, height int
}
// Questa funzione prende come argomento
// un puntatore a struct rect
func (r *rect) area() int {
return r.width * r.height
}
// Questa funzione prende come argomento
// una struct rect passata per valore
func (r rect) perim() int {
return 2*r.width + 2*r.height
}
// Le funzioni sopra diventano effettivamente 'metodi'
// della struct rect - come se fosse una classe
// NB: i metodi sono dichiarati esterni, non interni
// alla struct (<> C++ e Java)
func main() {
r := rect{width: 10, height: 5}
// Non vi è differenza di comportamento all'invocazione
// (completamente diverso dal C)
// Il comportamento interno è diverso ma la
// forma sintattica è uguale - dereferenziazione automatica
fmt.Println("area: ", r.area())
fmt.Println("perim:", r.perim())
// Se rp è un puntatore a r il comportamento non cambia
rp := &r
fmt.Println("area: ", rp.area())
fmt.Println("perim:", rp.perim())
// Si usa il puntatore per
// 1. evitare la copia di tutta la struct
// 2. far si che il metodo cambi la struct originale
}
Nel codice
func (r rect) perim() int {
si indica che solo una variabile var di tiporect, che è una struct, può invocare la funzione perim qui definita, con var.perim()e tale variabile sarà nota formalmente e localmente col nome r.
Non è necessario che l'oggetto invocante (attuale) si chiami r, solo conveniente.
Nel codice
func (r *rect) area() int {
si indica che solo un puntatore a struct di tipo rect può invocare la funzione area.
Se fossimo in linguaggio C++ parleremmo di funzione membro della struct (che però sarebbe una classe), e in Java di metodo.
In Go non esistono classi, solo struct. I metodi sono definiti fuori dalle struct.
Del resto in C++ una classe altro non è che una struct con funzioni membro oltre che variabili membro.
Concetto di Object Oriented: Incapsulamento
In linguaggi tradizionali (C++/Java) viene ritenuto vantaggioso l'incapsulamento dei dati, per ridurre l'accoppiamento di dipendenza tra classi.
Ciò si ottiene
- rendendo gli attributi private
- costruendo dei metodi public per l'accesso e il cambiamento degli attributi (getters e setters)
Questo si può fare anche in Go, con un po' di organizzazione
- ponendo la struct in un package separato
- dando nomi ai campi che iniziano con la minuscola (non sono esportati dal package)
- creando delle funzioni accessorie e mutatorie con nomi che iniziano con la maiuscola (sono automaticamene esportati dal package)
Per esempio:
1. Creare la directory figures e andarvi dentro
mkdir figures
cd figures
2. Editare il file figures.go come segue:
package figures
type Rect struct {
width, height int
}
func (r Rect) GetWidth() int {
return r.width
}
func (r *Rect) SetWidth(w int) {
r.width = w
}
func (r Rect) GetHeight() int {
return r.height
}
func (r *Rect) SetHeight(w int) {
r.height = w
}
3. Installarlo:
go install
Nel nostro caso il suo percorso di package diventa core/figures
4. In un'altra directory del workspace scrivere il programma che lo usa:
(19a-use-figures.go):
package main
import "fmt"
// import del package con alias
import fig "core/figures"
func main() {
// Dichiarazione di variabile
var rec fig.Rect
// Le seguenti non funzionano:
// rec.width = 10
// fmt.Println("Direct: ", rec.width)
// Questo è il modo corretto
rec.SetWidth(10)
fmt.Println("Width: ", rec.GetWidth())
rec.SetHeight(5)
fmt.Println("Height: ", rec.GetHeight())
}
Notare che il getter può operare su una struct passata per copia, mentre il setter deve operare su una struct passata tramite puntatore, perchè deve modificare un campo dell'originale e non della copia.
Interfacce
Un'interfaccia è un concetto molto potente che sta alla base del concetto di astrazione e dell'effetto di polimorfismo di metodo.
Un'interfaccia è un tipo che lista una serie di dichiarazioni di funzioni, ciascuna con il nome e il/i tipo/i di ritorno.
Le interfacce vengono implementate da una struct scrivendo la serie di metodi dichiarati nell'interfaccia.
Come al solito Go è molto più pratico e meno formale, p.es. di Java. Non esiste la parola chiave implements, ne tanto meno extends con eredità di interfacce.
Esempio
(200interfaces.go):
package main
import "fmt"
import "math"
// Un'interface è come una struct ma tutti
// gli elementi sono metodi dichiarati
type geometry interface {
area() float64
perim() float64
}
// Due struct su cui implementare l'interface
type rect struct {
width, height float64
}
type circle struct {
radius float64
}
// I metodi dichiarati in un'interface devono essere implementati
// per tutte le struct a cui si appliacano
// Per rect
func (r rect) area() float64 {
return r.width * r.height
}
func (r rect) perim() float64 {
return 2*r.width + 2*r.height
}
// Per circle
func (c circle) area() float64 {
return math.Pi * c.radius * c.radius
}
func (c circle) perim() float64 {
return 2 * math.Pi * c.radius
}
// Se una funzione ha un parametro di tipo interface
// possiamo richiamare tutti i metodi dell'interface
// NB: qui non è definito se measure si applica a rect o circle
// La funzione è richiamabile per tutte le struct
// che implementano l'interface geometry
func measure(t string, g geometry) {
fmt.Print(t, g,": ")
fmt.Printf("area: %8.2f\n", g.area())
fmt.Printf("perimeter: %8.2f\n", g.perim())
fmt.Println()
}
func main() {
r := rect{width: 3, height: 4}
c := circle{radius: 5}
// Dato che sia rect che circle implementano geometry
// si può invocare measure su r e su c
measure("rect", r)
measure("circle", c)
}
// La separazione tra interfaccia e implementazione
// è un pattern molto usato
Separazione di package
Vogliamo che le struct e l'interfaccia siano in un package e che i campi delle struct siano privati.
1. Creare la directory figs e andarvi dentro
mkdir figs
cd figs
2. Editare il file figs.go:
package figs
import (
"fmt"
"math"
)
// Dichiarazione dell'interfaccia
type Geometry interface {
area() float64
perim() float64
}
// Rettangolo
type Rect struct {
width, height float64
}
// Getters e setters per il rettangolo
func (r Rect) GetWidth() float64 {
return r.width
}
func (r *Rect) SetWidth(w float64) {
r.width = w
}
func (r Rect) GetHeight() float64 {
return r.height
}
func (r *Rect) SetHeight(w float64) {
r.height = w
}
// Implementazione dell'interfaccia
func (r Rect) area() float64 {
return r.width * r.height
}
func (r Rect) perim() float64 {
return 2*r.width + 2*r.height
}
// Cerchio
type Circle struct {
radius float64
}
// Getters e setters per il cerchio
func (c Circle) GetRadius() float64 {
return c.radius
}
func (c *Circle) SetRadius(rad float64) {
c.radius = rad
}
// Implementazione dell'interfaccia
func (c Circle) area() float64 {
return math.Pi * c.radius * c.radius
}
func (c Circle) perim() float64 {
return 2 * math.Pi * c.radius
}
// E' opportuno che ogni funzione esportata
// abbia un commento a precedere
func Measure(t string, g Geometry) {
fmt.Print(t, g, ": ")
fmt.Printf("area: %8.2f\n", g.area())
fmt.Printf("perimeter: %8.2f\n", g.perim())
fmt.Println()
}
3. Installare il package
go install
Nel nostro caso il suo percorso di package diventa
core/figs
4. In un'altra directory del workspace scrivere il programma che lo usa:
(202-interface-package.go):
package main
import (
fig "core/figs"
"fmt"
)
func main() {
// Le seguenti istruzioni non funzionano
// perchè gli attributi non sono esportati
// r := fig.Rect{width: 3, height: 4}
// c := fig.Circle{radius: 5}
var r fig.Rect
r.SetWidth(10.0)
r.SetHeight(5.0)
fmt.Println("Rectangle: width= ", r.GetWidth(),
" height= ", r.GetHeight())
var c fig.Circle
c.SetRadius(5.0)
fmt.Println("Circle: radius= ", c.GetRadius())
// Dato che sia rect che circle implementano geometry
// si può invocare measure su r e su c
fig.Measure("rect", r)
fig.Measure("circle", c)
}
Costruttori
Go non possiede costruttori, ma si possono emulare con una convenzione: per una struct Rect inserire la funzione
func NewRect(w, h float64) *Rect {
return &Rect{w, h}
}
Notare che ritorna un puntatore a Rect, che viene silenziosamente allocato in memoria dinamica.
Tutti i metodi che agiscono sulla struct devono ora prendere un argomento puntatore.
Il programma di package diventa core/figure/figure.go:
package figure
import (
"fmt"
"math"
)
// Dichiarazione dell'interfaccia
type Geometry interface {
area() float64
perim() float64
}
// Rettangolo
type Rect struct {
width, height float64
}
// Pseudocostruttore
func NewRect(w, h float64) *Rect {
return &Rect{w, h}
}
// Getters e setters per il rettangolo
func (r *Rect) GetWidth() float64 {
return r.width
}
func (r *Rect) SetWidth(w float64) {
r.width = w
}
func (r *Rect) GetHeight() float64 {
return r.height
}
func (r *Rect) SetHeight(w float64) {
r.height = w
}
// Implementazione dell'interfaccia
func (r *Rect) area() float64 {
return r.width * r.height
}
func (r *Rect) perim() float64 {
return 2*r.width + 2*r.height
}
// Cerchio
type Circle struct {
radius float64
}
// Pseudocostruttore
func NewCircle(r float64) *Circle {
return &Circle{r}
}
// Getters e setters per il cerchio
func (c *Circle) GetRadius() float64 {
return c.radius
}
func (c *Circle) SetRadius(rad float64) {
c.radius = rad
}
// Implementazione dell'interfaccia
func (c *Circle) area() float64 {
return math.Pi * c.radius * c.radius
}
func (c *Circle) perim() float64 {
return 2 * math.Pi * c.radius
}
// E' opportuno che ogni funzione esportata
// abbia un commento a precedere
func Measure(t string, g Geometry) {
fmt.Print(t, g, ": ")
fmt.Printf("area: %8.2f\n", g.area())
fmt.Printf("perimeter: %8.2f\n", g.perim())
fmt.Println()
}
E il programma principale è:
(204-interface-constructor.go):
package main
import (
fig "core/figure"
"fmt"
)
func main() {
// r e c sono puntatori, ma non si nota
r := fig.NewRect(10, 5)
c := fig.NewCircle(5)
// Il resto del programma non cambia
fmt.Println("Rectangle: width= ", r.GetWidth(),
" height= ", r.GetHeight())
fmt.Println("Circle: radius= ", c.GetRadius())
fig.Measure("rect", r)
fig.Measure("circle", c)
}
Le convenzioni sono quindi:
- Le struct sono gestite per riferimento
- Il costruttore di
struct PippoèNewPippo - Se un attributo si chiama
attr
- Il suo getter è
GetAttr - Il suo setter è
SetAttr
Commento
Abbiamo riprodotto la sitazione di Java, in cui tutti gli oggetti sono silenziosamente gestiti per riferimento.
Gestione Errori
Go non ha eccezioni runtime. La sua filosofia è che gli eventuali errori devono essere verificati e gestiti ad ogni passo.
Sappiamo che molte funzioni di libreria ritornano un errore come ultimo valore. E' opportuno che anche le nostre funzioni si comportino in modo simile.
Esempio
(210errors.go):
package main
// Modulo per la gestione errori
// 'error' è un'interfaccia
import "errors"
import "fmt"
// E' convenzione ritornare un errore come ultimo valore
func f1(arg int) (int, error) {
if arg == 42 {
// `errors.New` costruisce un nuovo messaggio d'errore
return -1, errors.New("can't work with 42")
}
// 'nil' indica l'assenza d'errore
return arg + 3, nil
}
// E' possibile definire un tipo custom per gli errori
type argError struct {
arg int
prob string
}
// Per soddisfare l'interfaccia 'error' occorre
// implementare il metodo Error
func (e *argError) Error() string {
return fmt.Sprintf("%d - %s", e.arg, e.prob)
}
func f2(arg int) (int, error) {
if arg == 42 {
// Occorre costruire una struct &argError
return -1, &argError{arg, "can't work with it"}
}
return arg + 3, nil
}
func main() {
// Test con 'error' standard
for _, i := range []int{7, 42} {
// Notare l'assegnazione e if combinati
if r, e := f1(i); e != nil {
fmt.Println("f1 failed:", e)
} else {
fmt.Println("f1 worked:", r)
}
}
// Test con 'argError'
for _, i := range []int{7, 42} {
if r, e := f2(i); e != nil {
fmt.Println("f2 failed:", e)
} else {
fmt.Println("f2 worked:", r)
}
}
// Per usare i dati in un gestore custom
_, e := f2(42)
// Occorre un puntatore *argError perche il nostro f2
// genera un indirizzo &argError
if ae, ok := e.(*argError); ok {
fmt.Println(ae.arg)
fmt.Println(ae.prob)
}
}
Esercizi

Esercizio 301
Si parta da una struct chiamata person che contiene nome, cognome, anni.
Scrivere un metodo ident() su tale struct che ritorna una stringa con, concatenate:
- le prime 5 lettere del nome
- le prime 5 lettere del cognome
- gli anni troncati ai 10 inferiori, p.es. per 46 torna 40, per 18 torna 10, ...
Se nome o cognome sono più corti di 5 caratteri, completa a 5 caratteri con delle ‘X’, p.es. ‘Joe’, ‘Baldwin’, ‘53’ diventa ‘JoeXXBaldw50’
Come test nel main(), scrivere un array di 5 struct e passarle al metodo.
Scrivere un secondo metodo matricola() su tale struct, che ritorna un numero intero sequenziale, a partire da 100 e aumentato di 1 ad ogni invocazione.
- Visualizzare i risultati
- Si modifichi person aggiungendo il campo
id, inizialmente vuoto. Si modifichiquindiident()in modo che riempia tale campo nella struct person.
Esercizio 302
Si scriva un’interfaccia process con le funzioni:
runelen()- che ritorna il numero di rune in una stringabytelen()- che ritorna il numero di bytes in una stringa
Si scrivano i due metodi implementativi di tale interfaccia.
Come test passargli le stringhe:
- Italia
- Россия
- 日本
e visualizzare i risultati.
Goroutines e Channels

Il linguaggio Go è organizzato per fornire routines di esecuzione concorrenti, le goroutines, che comunicano tra loro tramite channels.
Questo fornisce un meccanismo molto potente di costruzione di applicativi complessi, ma presenta naturalmente una serie di problemi di sincronizzazione e accesso esclusivo a risorse.
Goroutines
Una goroutine è un'unità di esecuzione indipendente all'interno del processo corrente.
Generazione di goroutines
Quando un eseguibile Go viene lanciato, un primo processo di bootstrap inizializza l'ambiente di esecuzione del processo, creando le regioni di memoria necessarie e lanciando alcuni threads di esecuzione del sistema operativo:
- Il gestore di memoria
- Il garbage collector
- Lo schedulatore
Lo schedulatore genera la routine principale, il main.
Dall'interno del main possono venir lanciate routines aggiuntive, le goroutines col comando
go funzione
Ogni goroutine è gestita dallo schedulatore che la esegue a intervalli regolari e per una fetta di tempo.
Le goroutines non sono threads per se. Possono però essere allocate in threads di sistema diversi su diverse CPU. Di default vengono utilizzate tutte le CPU disponibili.
Comunicazione tra goroutines
Una goroutine può ricevere parametri iniziali dal main tramite la funzione di lancio, pio diventaindipendente e il main non le può più passare parametridirettamente.
La comunicazione tra goroutines e main (che è formalmente un'altra routine) e tra le routines stesse avviene tramite canali detti channels.
I channel sono primitive di bufferizzazione e sincronizzazione dati simili alle pipes di Unix, ma in ambiente concorrente.
I channel sono in memoria dinamica e vanno creati, gestiti e chiusi. Possono essere monodirezionali o bidirezionali, possono avere una capacità determinata di dati. Vi sono operatori di lettura e scrittura dei channel.
Terminazione di goroutines
Una goroutine può decidere di terminare col comando return.
Quando è il main che compie un return, l'intero processo termina:
- sono distrutte tutte le goroutines
- sono eseguite eventuali funzioni differite
- viene disallocata tutta la memoria e tutte le risorse usate dal processo
- il processo termina nel sistema operativo
Una goroutine non può comandare ad un'altra goroutine di terminare, solo indicarne l'intenzione tramite channel.
Esempio
Il programma seguente illustra la differenza tra l'invocazione di una funzione direttamente dal main e tramite una goroutine
(220goroutines.go):
package main
import "fmt"
// Funzione che stampa una stringa 3 volte
func f(from string) {
for i := 0; i < 3; i++ {
fmt.Println(from, ":", i)
}
}
// Una goroutine è un thread eseguibile
func main() {
// Normale richiamo diretto di una funzione sincrona
// nello stesso thread del main
// E' sincrona
f("direct")
// Invocazione di una goroutine in un thread
// diverso dal main
// E' asincrona
go f("goroutine")
// Il thread viene generato, eseguito
// e distrutto al termine dell'esecuzione
// Goriutine come funzione anonima
// Notare il passaggio immediato dell'argomento
go func(msg string) {
fmt.Println(msg)
}("going")
// L'esecuzione arriva qui
var input string
// Acquisizione di un Return da input
// La stringa di input viene ignorata
// Notare che l'argomento è un indirizzo (= C)
fmt.Scanln(&input)
fmt.Println("done")
}
Le goroutines hanno sempre associata una funzione.
Questa può essere:
- già definita con nome altrove nel codice
- definita all'istante del lancio della goroutine e in tal caso non è necessario che abbia un nome, è anonima
Dato che goroutine diverse eseguono concorrentemente, non è definibile quale di loro è schedulata per prima.
Eventuale loro output non avviene necessariamente nella sequenza di lancio, e può differire tra invocazioni diverse del processo.
Wait Group
Prima di terminare il main deve dare tempo alle goroutines di terminare il proprio lavoro.
Questo si ottiene con una variabile di sincronizzazione di gruppo:
var wg sync.WaitGroup
Prima di lanciare una goroutine il main aggiunge una entry al gruppo:
wg.Add(1)
Una goroutine prima di terminare lo comunica al gruppo:
wg.Done()
e il main decrementa il numero delle goroutines attive.
Il main attende che tutte le goroutines abbiano terminato con:
wg.Wait()
poi può terminare a sua volta.
(221no-wg.go):
package main
import "fmt"
func main() {
fmt.Println("start")
go doSomething()
// Quando il programma termina
// tutte le goroutines sono terminate
fmt.Println("end")
}
func doSomething() {
fmt.Println("do something")
}
// Qualche volta lo scrive, qualche volta no
// Occorre che il main attenda la terminazione
// della goroutine
(222waitgroup.go):
package main
import (
"fmt"
"sync"
)
// Variabile di sincronizzazione di gruppo
var wg sync.WaitGroup
func main() {
fmt.Println("start")
wg.Add(1) // indica che apetteremo un programma
go doSomething()
fmt.Println("end")
wg.Wait() // attesa del completamento dei programmi
// uscita globale
}
func doSomething() {
fmt.Println("do something")
wg.Done() // segnala il completamento
}
Efficacia delle Goroutines
Quando determinate operazioni si possono parallelizzare, può essere molto conveniente usare goroutines.
Questo è tanto più vero quando vi siano più core computazionali
Non tutti i problemi possono però aumentare di efficienza con l’uso di goroutines.
Lo schedulatore ha uno overhead
- nella generazione di goroutines
- nello switch tra goroutines
(223mult-simple.go):
// Moltiplicazione con singolo thread
package main
import (
"fmt"
"time" )
func main() {
for n := 2; n <= 12; n++ {
timestable(n)
}
}
func timestable(x int) {
for i := 1; i <= 12; i++ {
fmt.Printf("%d x %d = %d\n", i, x, x*i)
// Introduce un ritardo voluto
time.Sleep(100 * time.Millisecond)
}
}
// Provare con:
// time go run 223mult-simple.go
(224mult-goroutines.go):
// moltiplicazione con più goroutines
package main
import "fmt"
import "sync"
import "time"
var wg sync.WaitGroup
func main() {
for n := 2; n <= 12; n++ {
wg.Add(1)
go timestable(n) // Calcola la tabellina dell’n
}
wg.Wait()
}
func timestable(x int) {
for i := 1; i <= 12; i++ {
fmt.Printf("%d x %d = %d\n", i, x, x*i)
time.Sleep(100 * time.Millisecond)
}
wg.Done()
}
// testarne la velocità
Channel
Un channel è una struttura del Go per permettere a routine diverse di comunicare tra loro.
Un channel è una risorsa in memoria dinamica e pertanto va allocato con la funzione make.
Un channel ha un tipo dei dati che può trasmettere.
La lettura e scrittura avvengono con l'operatore <-, da vedersi come una freccia indicante la direzione di flusso dei dati.

Esempio
(230channels.go):
package main
import "fmt"
func main() {
// Un channel è una primitiva di connessione fra goroutines
messages := make(chan string)
// Invio di un messaggio al channel
go func() { messages <- "ping" }()
// Recupero di un messaggio dal channel
msg := <-messages
fmt.Println(msg)
}
La lettura da un channel è bloccante. La routine non può proseguire finchè non vi sono dati da legger dal channel, ciè finchè un'altra routine non scriva qualcosa nel channel.
Questo è il fondamento del meccanismo di sincronizzazione.
Channel non inizializzato
(232-uninitialized-channel.go):
package main
import "fmt"
// I Channel devono essere inizializzati con make
// Un channel globale non inizializzato
var str chan string
// Sostituirlo col seguente per farlo funzionare
// var str = make(chan string)
func main() {
// Goroutine invia un messaggio al channel
go func() {
str <- "hello"
}()
// Recupero di un messaggio dal channel
msg := <-str
fmt.Println(msg)
}
// Un channel non inizializzato vale 'nil'
// Regole:
// 1. receive da channel nil si blocca
// 2. send a channel nil si blocca
// 3. send a un canale chiuso va in panic
// 4. receive da un canale chiuso ritorna uno zero
Regole
Un channel non inizializzato vale 'nil'. Regole:
- receive da channel nil si blocca
- send a channel nil si blocca
- send a un channel chiuso va in panic
- receive da un channel chiuso ritorna uno zero
Occorre compiere molta attenzione ad inizializzare sempre i channel.
Bufferizzazione
Un channel normale contiene esattamente un valore. E' possibile creare channel che contengono più di un valore, dando il loro numero come secondo argomento all'atto della creazione.
Si ottiene un channel bufferizzato, con lunghezza del buffer indicata.

Esempio
(240channel-buffering.go):
package main
import "fmt"
func main() {
// Di default i channel non sono bufferizzati
// e accettano un send solo se il receive è attivo
// Di seguito è creato un canale bufferizzato
// con fino a 2 valori
messages := make(chan string, 2)
// Si possono bufferizzare i valori senza
// che vi sia ancora il receive
messages <- "buffered"
messages <- "channel"
// Il receive avviene più tardi
fmt.Println(<-messages)
fmt.Println(<-messages)
// Se si toglie il commento si genera un blocco
// fmt.Println(<-messages)
}
Regole
Le regole sono:
- ogni read toglie un valore dal channel
- se il channel è vuoto in read la routine si blocca
- se il channel è pieno in write la routine si blocca
Nell'esempio corrente il channel è scritto e letto dal main. Questa non è una buona idea.
Un channel non dovrebbe mai essere sia letto che scritto dalla stessa routine.
Se il main si blocca e non vi è nessun'altra routine attiva che lo sblocchi si causa un Deadlock, con conseguente panic.
Il Go ha un modulo di detezione dei Deadlock a runtime, purtroppo però non durante la compilazione.
Sincronizzazione
Quando si hanno più routines concorrenti e in comunicazione tra loro, sorge subito il problema della sincronizzazione delle operazioni.
Il programma emula una goroutine che lavora per cinque secondi, poi comunica la sua terminazione al main col channel done.
Il main è bloccato finchè non riceve tale notifica dalla goroutine.
Questo è uno schema molto comune.
Esempio
(250channel-synchronization.go):
package main
import "fmt"
import "time"
// I channel si usano per sincronizzare le goroutine
// Funzione da eseguire in una goroutine
// done è il channel di sincronizzazione
func worker(done chan bool) {
fmt.Print("working...")
// Attende 5 secondi
time.Sleep(5*time.Second)
fmt.Println("done")
// Notifica della fine del lavoro
done <- true
}
func main() {
// Creazione del channel bufferizzato
done := make(chan bool, 1)
// E' invocata la goroutine
fmt.Println("Blocking in main")
go worker(done)
// Si blocca fino alla ricezione del messaggio
<-done
fmt.Println("Unblocked main")
}
In questo paericolare caso, se anzichè un channel bufferizzato di un elemento si fosse usato un channel normale, il funzionamento sarebbe stato lo stesso:
done := make(chan bool)
Direzione
Conviene sempre che le funzioni che prendono channel come parametri indichino se il channel è gestito in sola lettura o solo scrittura.
Questo evita la situazione pericolosa di lettura e scrittura sullo stesso channel - il compilatore se ne accorge.
Esempio
(260channel-directions.go):
package main
import "fmt"
// Funzione che accetta un channel solo per invio
// I parametri formali hanno un nome indipendente
// dai parametri attuali
func ping(in chan<- string, msg string) {
in <- msg
}
// Funzione che accetta un channel solo in ricezione
// e un secondo channel solo in invio
func pong(in <-chan string, out chan<- string) {
// attende un ping
msg := <-in
// invia subito un pong
out <- msg
}
func main() {
// I channel devono essere bufferizzati
pings := make(chan string, 1)
pongs := make(chan string, 1)
go pong(pings, pongs)
go ping(pings, "passed message")
// Se si arriva qui il messaggio è tornato
fmt.Println(<-pongs)
}
ping riceve una stringa dal main sul cahannel di input.
pong legge dal channel di input e invial il dato al channel di output
Il main poi legge dal channel di output.
Notare che i nomi attuali dei channel sono diversi nel main dai nomi formali dei parametri delle funzioni. In generale le funzioni potrebbero trovarsi in un altro package e il main non avrebbe idea del nome dei channel in tali funzioni.
Le due funzioni potrebbero essere anche in package diversi e avere nomi dei parametri formali diversi.
In questo programma tutto avviene in un'unica routine, il main. Non è una buona idea.
I channel servono a comunicare tra goroutines diverse, o tra loro e il main. Nel mondo reale e non didattico, la comunicazione tramite channel di una routine con se stessa è un invito a problemi.
Select
Il costrutto select serve ad evitare il blocco quando un channel in lettura è vuoto.
Il costrutto select è come switch ma concepito apposta per operare su channel.
Il primo dei case alternativi che si verifica soddisfa il select.
Esempio
(270select.go):
package main
import "time"
import "fmt"
func main() {
// Due channel
c1 := make(chan string)
c2 := make(chan string)
// Ogni channel riceve un valore dopo un ritardo
// generato da due goroutines diverse
go func() {
time.Sleep(time.Second * 2)
c1 <- "one"
}()
go func() {
time.Sleep(time.Second * 1)
c2 <- "two"
}()
// select ascolta su entrambi i channel
// Come ricezione eventi
for i := 0; i < 2; i++ {
// select esce col primo case verificato
// Perciò il for
select {
case msg1 := <-c1:
fmt.Println("received", msg1)
case msg2 := <-c2:
fmt.Println("received", msg2)
}
}
}
Nell'esempio sopra il for cicla esattamente due volte sul select, perchè sappiamo che vi sono due messaggi in arrivo. La situazione reale sarebbe più complessa.
Fibonacci con goroutine e channels
Nel caso seguente deleghiamo una goroutine al calcolo dei numeri di Fibonacci.
Oltre al channel ch che contiene i numeri cacolati si usa il channel done per indicare alla goroutine la terminazione del lavoro.
(271-fibonacci.go):
package main
import "fmt"
func main() {
// ch : channel per i dati
// quit: channel per indicare terminazione
ch, quit := make(chan int), make(chan int)
// lancio della goroutine
go fibs(ch, quit)
// raccolta di 20 dati
for i := 0; i < 20; i++ {
fmt.Println(<-ch)
}
// segnala terminazione
quit <- 0
}
func fibs(ch, quit chan int) {
i, j := 0, 1
for {
select {
// se c'è qualcuno che riceve
// invia il prossimo valore
case ch <- j:
i, j = j, i+j
// se si riceve terminazione esce
case <-quit:
return
}
}
}
La goroutine fibs pone il numero corrente su ch.
Se qualcuno legge il channel ch allora viene calcolato il prossimo numero di Fibonacci e si torna in ciclo.
Se non vi fosse il ciclo la goroutine terminerebbe dopo il primo numero di Fibonacci e il main si bloccherebbe per sempre tentando di leggere il secondo.
Se invece vi è un valore sul channel quit, la goroutine termina.
Il main legge 20 volte dal channel ch poi pone un valore sul channel done.
In questo caso se non l'avesse fatto il programma sarebbe terminato lo stesso. Ma questa procedura è buona norma perchè il programma potrebbe essere successivamente modificato e ci potremmo trovare con una goroutine spinning all'infinito senza fornire lavoro produttivo.
Il fatto che i parametri formali e attuali - i nomi dei channel - siano gli stessi, non è necessario: la funzione di goroutine poteva benissimo essere in un altro package e usare nomi diversi per i propri parametri formali.
Timeouts
Per evitare lo spinning all'infinito o il blocco nel main si può usare un timeout.
Questo è prodotto dalla funzione After del package time che prende come argomento un intervallo di tempo e pone un valore su un suo channel predefinito allo scadere dell'intervallo.
Il programma seguente illustra i timeout con due esempi.
Nel primo esempio arriva prima il timeout della goroutine, nel secondo caso prima la goroutine del timeout.
Esempio
(280timeouts.go):
package main
import "time"
import "fmt"
func main() {
// Goroutine che comunica su channel dopo 2s
c1 := make(chan string, 1)
go func() {
time.Sleep(time.Second * 2)
c1 <- "result 1"
}()
select {
case res := <-c1:
fmt.Println(res)
// timeout dopo un secondo
case <-time.After(time.Second * 1):
fmt.Println("timeout 1")
}
// Goroutine che comunica su channel dopo 2s
c2 := make(chan string, 1)
go func() {
time.Sleep(time.Second * 2)
c2 <- "result 2"
}()
select {
case res := <-c2:
fmt.Println(res)
// timeout dopo 3 secondi
case <-time.After(time.Second * 3):
fmt.Println("timeout 2")
}
fmt.Println("Terminated")
}
Break ad etichetta
Supponiamo di sostituire l'ultimo select del secondo esempio con:
for {
select {
case res := <-c2:
fmt.Println(res)
// timeout dopo 3 secondi
case <-time.After(time.Second * 3):
fmt.Println("timeout 2")
}
}
Il programma segnala correttamente result 2 ma poi torna in loop infinito a dire timeout 2 ogni 3 secondi. Occorre uscire dal for dopo l'uno o l'altro case, ma non si può usare return poichè uscirebbe dall'intero programma e non stamperebbe Terminated.
Se si usa il break come nel frammento seguente:
for {
select {
case res := <-c2:
fmt.Println(res)
break
// timeout dopo 3 secondi
case <-time.After(time.Second * 3):
fmt.Println("timeout 2")
break
}
}
fmt.Println("Terminated")
Il risultato non cambia perchè break esce solo dal costrutto corrente, che è il select, non il for.
La soluzione è un break a label:
loop:
for {
select {
case res := <-c2:
fmt.Println(res)
break loop
// timeout dopo 3 secondi
case <-time.After(time.Second * 3):
fmt.Println("timeout 2")
break loop
}
}
fmt.Println("Terminated")
loop: è un'etichetta (una stringa seguita da due punti), che marca il costrutto seguente.
break loop causa l'uscita dal costrutto marcato con l'etichetta loop.
Notare che non si tratta di un goto come in linguaggio C, ma di qualcosa di più complesso.
Un costrutto molto simile esiste anche in Java.
Operazioni non Bloccanti
Quando si opera con i channels bisogna sempre porre molta attenzione alle situazioni di blocco.
Esempio
(290non-blockng-channel-operations.go):
package main
import "fmt"
//import "time"
func main() {
// I channel non bufferizzati sono bloccanti
messages := make(chan string)
signals := make(chan bool)
// Attenzione il seguente codice produce
// un deadlock
// messages <- "hello"
// Il seguente codice invece non blocca
// perchè in un thread differente
// go func() {
// messages <- "hello"
// }()
go func() {
messages <- "hello"
}()
// ma se è ricevuto o no è aleatorio
// a meno di attendere che la goroutine operi
// scommentando il codice seguente
// (scommentare anche lo import necessari
// time.Sleep(time.Second)
// Implementazione di un receive non bloccante
select {
case msg := <-messages:
fmt.Println("received message", msg)
// Se non c'è subito un messaggio scatta il default
default:
fmt.Println("no message received")
}
// Un send non bloccante
msg := "hi"
select {
case messages <- msg:
fmt.Println("sent message", msg)
default:
fmt.Println("no message sent")
}
// Select multiplo non bloccante
select {
case msg := <-messages:
fmt.Println("received message", msg)
case sig := <-signals:
fmt.Println("received signal", sig)
default:
fmt.Println("no activity")
}
}
Come si nota una select, come uno switch, può avere un case di default, che è sempre soddisfatto a meno che non sia stato soddisfatto uno dei case precedenti.
Nel nostro esempio quasi sicuramente interviene sempre la situazione di default perchè la goroutine che emette il messaggio probabilmente non ha avuto ancora tempo di operare, Quando il main esegue il select.
In una situazione vera o vi sarebbe qualche tipo di ritardo prima del select, oppure vi sarebbe un loop per iterare sul select più volte.
Chiusura
Questo è un altro esempio dell'uso di due channels tra il main e la goroutine, jos per l'invio di lavoro vero, e done per la segnalazione della goroutine ùal main che ha finito di lavorare.
Questo esempio usa un channel dei jobs di capienza bufferizzata superiore all'uso attuale, ed una segnalazione esplicita di terminazione di invio con il comando close.
Esempio
(300closing-channels.go):
package main
import "fmt"
// Il channel jobs comunica il lavoro da fare
// alla goroutine finchè non viene chiuso
func main() {
// Il comportamento è più verosimile
// se il channel è bloccante, sostituendo
// jobs := make(chan int)
// al seguente
jobs := make(chan int, 5)
done := make(chan bool)
// La goroutine di consumo dei jobs
go func() {
// Loop infinito - spinning
for {
// j è il job, more è un error
// se falso, il channel è stato chiuso
j, more := <-jobs
if more {
fmt.Println("received job", j)
} else {
fmt.Println("received all jobs")
// segnala la fine del lavoro
done <- true
return
}
}
}()
// Invia tre job sul channel jobs
for j := 1; j <= 3; j++ {
jobs <- j
fmt.Println("sent job", j)
}
// Chiude il channel jobs
close(jobs)
fmt.Println("sent all jobs")
// Attende la segnalazione di fine lavoro
<-done
}
Il comando close(jobs) pone sul channel un segnalino esplicito di terminazione.
La goroutine ad ogni giro del loop legge dal channel un job che ritorna un valore ed un errore, che scatta se viene trovato il segnalino di terminazione.
Dopo un close la routine scrivente non può più scrivere nel channel.
Range sui Channel
Per automatizzare la detezione della chiusura del channel si usa il costrutto range che opera su un channel. Questo costrutto ascolta in continuazione sul channel ma si accorge della presenza del segnale di chiusura ed esce.
Se il channel non fosse stato chiuso si sarebbe andati ad un blocco.
Esempio
(310range-over-channels.go):
package main
import "fmt"
func main() {
// Due valori in un channel
queue := make(chan string, 2)
// Il channel bufferizzato deve avere capacità
// per tutti i valori che riceve
// Il seguente codice produce un blocco
// queue := make(chan string, 1)
queue <- "one"
queue <- "two"
// Il channel viene esplicitamente chiuso
close(queue)
// Scandisce tutti gli elementi del channel
// Se non venisse chiuso vi sarebbe un blocco
for elem := range queue {
fmt.Println(elem)
}
}
// In generale i channel sono concepiti per comunicazione
// fra thread diversi. Comunque occorre sempre
// preoccuparsi di evitare i deadlock
range richiede che il channel abbia avuto un close.
Esempio 2
(311chrange.go):
package main
import "fmt"
// funzione di goroutine che comunica tramite un channel
func FibonacciProducer(ch chan int, count int) {
n2, n1 := 0, 1
for count >= 0 {
// un elemento per volta nel channel
ch <- n2
count--
n2, n1 = n1, n2+n1
}
// è indispensaabile chiudere il channel
// o si verifica un deadlock
close(ch)
}
func main() {
// non è necessario un channel bufferizzato
ch := make(chan int)
go FibonacciProducer(ch, 10)
idx := 0
// range si ferma quando incontra il
// marker di chiusura del channel
for num := range ch {
fmt.Printf("F(%d): \t%d\n", idx, num)
idx++
}
}
Si può usare range anche su un channel unbuffered.
Questo codice non è consentito:
ch := make(chan int)
go FibonacciProducer(ch, 10)
for idx, num := range ch {
fmt.Printf("idx: %d F(%d): \t%d\n", idx, num)
}
Se l’espressione del range è un channel si può avere al massimo una variabile di iterazione, altrimenti fino a due.
Esempio 3
(312norange.go);:
package main
import (
"fmt"
"time"
)
func readMessages(messenger <-chan string) {
// contatore, scopo didattico
i := 0
for {
select {
case msg := <-messenger:
fmt.Println(msg)
default:
// stampa e incrementa il contatore
fmt.Println(i, ": no message")
i++
}
}
}
func main() {
mess := make(chan string)
go readMessages(mess)
mess <- "hello"
close(mess)
// simula altro lavoro
time.Sleep(time.Millisecond)
}
Esempio 4
(313withrange.go):
package main
import (
"fmt"
"time"
)
func readMessages(messenger <-chan string) {
// legge solo se c’è un valore nel channel
// si ferma quando il channel è chiuso
for msg := range messenger {
fmt.Println(msg)
}
}
func main() {
mess := make(chan string)
go readMessages(mess)
mess <- "hello"
close(mess)
// simula altro lavoro
time.Sleep(time.Millisecond)
}
Esercizi

Esercizio 401
Generare tre goroutines, one, two e three, ciascuna delle quali conta fino a 100, e ad ogni nuovo numero lo stampa insieme ad un proprio identificatore.
Cosa succede se il main esce subito dopo il lancio delle tre goroutines?
Inserire un temporizzatore di 1 secondo alla fine del main
Inserire un temporizzatore di 1 millisecondo in ciascuna goroutine
Esercizio 402
Una funzione slowcount conta da 0 al numero massimo fornitole come
parametro. Tra un numero e l’altro attende 1 millisecondo. Al termine ritorna su un channel, fornitole come parametro, l’indicazione che ha finito, e stampa un messaggio a video.
Il main genera 4 goroutines su tale funzione, ciascuna su un channel diverso, passando loro i numeri massimi 4567, 7687, 1985, 6678. Quindi ascolta per vedere quando hanno finito. Infine segnala la terminazione del lavoro ed esce.
Si possono eliminare i channels?
Estensione: il main genera 100 goroutines passando loro, come numero massimo, un numero casuale tra 0 e 20000.
Suggerimento: esplorare la funzione Intn() del package math/rand
Esercizio 403
Una goroutine scrive a video ‘Premere INVIO per continuare’. Quindi attende l’input da tastiera. Quando arriva lo segnala al main su un channel.
Il main rimane in ascolto o finchè arriva il segnale dal channel oppure per un timeout di 5 secondi.
Suggerimento: investigare la funzione fmt.Scanln()
Operazioni Avanzate

La presenza tipica di più goroutines simultanee in un programma richiede la loro armonizzazione ed organizzazione cooperante.
Si possono schedulare operazioni da compiere una tantum nel futuro,oppure a intervalli regolari.
Può inoltre essere necessario mantenere lo stato associato alle goroutines.
Timers
Un timer è una struct complessa, comprendente un campo channel C.
Il timer viene creato con la funzione NewTimer del package time, che lo alloca in memoria dinamica.
Il parametro di creazione è un tempo, allo scadere del quale viene posto un valore sul channel C del timer.
Anche la funzione After del package time si comporta in modo simile, ma sottilmente diverso. After è un channel che viene riempito allo scadere del suo argomento.
Mentre un timer è interrompibile, il canale After non lo è. After serve per un ritardo temporale locale, un timer è una sveglia assoluta.
Esempio
(320timers.go):
package main
import "time"
import "fmt"
func main() {
// Un timer è un evento a scadenza temporale futura
// Un timer ha un channel C che ha un elemento
// allo scadere del timer
timer1 := time.NewTimer(time.Second)
fmt.Println("main: timer 1 set to 1 second")
// La seguente è bloccante
<-timer1.C
fmt.Println("main: timer 1 expired")
// Un timer può essere fermato prima dello scadere
// a differenza di time.Sleep
timer2 := time.NewTimer(10 * time.Second)
fmt.Println("main: timer 2 set to 10 seconds")
// La goroutine attende il timer2 e
// segnala ogni secondo che passa
go func() {
i := 0
for {
select {
case <-timer2.C:
fmt.Println("go: timer 2 expired")
return
case <-time.After(time.Second):
i++
fmt.Printf("go: still here after %d sec\n", i)
}
}
}()
//Attende 3 secondi prima di fermare il timer
fmt.Println("main: waiting 5 seconds before stopping timer2")
<-time.After(5 * time.Second)
// Ferma timer2
stop2 := timer2.Stop()
// timer2.Stop ritorna un booleano indicante successo
if stop2 {
fmt.Println("main: timer 2 stopped")
}
// Quando un timer è fermato le goroutine bloccate
// sul timer non vengono terminate
// E' possibile risettare un timer
timer2.Reset(3 * time.Second)
fmt.Println("main: timer 2 reset to 3 second")
fmt.Println("main: waiting 5 seconds before exiting")
<-time.After(5 * time.Second)
fmt.Println("main: exiting now")
}
Ad un timer si può applicare la funzione Stop: il timer continua ad esistere, ma il suo tempo di scatto è ora infinito.
Con la funzione Reset il timer può essere fatto ripartire con un tempo diverso di scatto.
Tutto il codice che attendeva in lettura sul canale Cdel timer si comporta di conseguenza.
Distruzione di timer
Un timer viene automaticamente distrutto dopo lo scatto e quindi il primo codice che lo legge vince.
Questo è dimostrato dal seguente programma:
(321-timer-two.go):
package main
import (
"fmt"
"time"
)
func main() {
tim := time.NewTimer(3 * time.Second)
go func() {
i := 0
for {
select {
case <-tim.C:
fmt.Println("go1: timer expired")
return
case <-time.After(time.Second):
i++
fmt.Printf("go1: still here after %d sec\n", i)
}
}
}()
go func() {
i := 0
for {
select {
case <-tim.C:
fmt.Println("go2: timer expired")
return
case <-time.After(time.Second):
i++
fmt.Printf("go2: still here after %d sec\n", i)
}
}
}()
<-time.After(10 * time.Second)
fmt.Println("main: exiting now")
}
E' aleatorio se sia prima go1 o go2 a ricevere il segnale dal timer.
Evidentemente o non più di una goroutine deve attendere lo stesso timer, oppure abbiamo bisogno di informare le altre goroutines dello scatto avvenuto.
Tickers
Un tickerè simile ad un timer, in quanto allo scatto invia un elemento al suo channel C.
Ma un ticker continua all'infinito a scattare a intervalli regolari.
E' una differenza simile a quella di at e cronin Linux.
Un ticker si crea in memoria dinamica con la funzione NewTicker.
Un ticker è fermabile con la funzione Stop, ma non è più ristartabile.
L'elemento posto sul channel C è un timestamp.
Esempio
(330tickers.go):
package main
import "time"
import "fmt"
func main() {
// Un ticker ha un channel che riceve un elemento
// a intervalli regolari
fmt.Println("main: ticker set every 500 ms")
ticker := time.NewTicker(time.Millisecond * 500)
// Goroutine che legge il ticker se pieno
// oppure conta i secondi
go func() {
i := 0
for {
select {
case t := <-ticker.C:
fmt.Println("go: tick at", t)
case <- time.After(time.Second):
i++
fmt.Printf("go: still here after %d sec\n", i)
}
}
}()
// I ticker si possono fermare come i timer
fmt.Println("main: sleeping for 5600 ms")
time.Sleep(time.Millisecond * 5600)
ticker.Stop()
fmt.Println("main: ticker stopped")
// Fermare un ticker non termina i thread che lo ascoltano
// Un ticker non si può risettare
fmt.Println("main: waiting 5 seconds before exiting")
<-time.After(5 * time.Second)
fmt.Println("main: exiting now")
}
Anche qui allo stop del ticker tutte le routine che lo leggono continuano ad attendere se non sono informate.
Due goroutine in lettura
Se due goroutine leggono dallo stesso ticker, la prima che arriva legge, l'altra no e perde il turno.
Questo è dimostrato dal programma:
(331-tickers-two.go):
package main
import (
"fmt"
"time"
)
func main() {
ticker := time.NewTicker(time.Second)
go func() {
i := 0
for {
select {
case t := <-ticker.C:
fmt.Println("go1: tick at", t)
case <-time.After(time.Millisecond * 500):
i++
fmt.Printf("go1: still here after %d millisec\n", i*500)
}
}
}()
go func() {
i := 0
for {
select {
case t := <-ticker.C:
fmt.Println("go2: tick at", t)
case <-time.After(time.Millisecond * 800):
i++
fmt.Printf("go2: still here after %d millisec\n", i*800)
}
}
}()
<-time.After(10 * time.Second)
fmt.Println("main: exiting now")
}
Workers
Quando si ha una situazione di molti jobs indipendenti da compiere, il lavoro può essere suddiviso su un numero di goroutines, ciascuna delle quali esegue lo stesso codice.
Tali goroutines si chiamano workers.
Ogni worker ha un channel per ricever i jobs ed un altro per inviare i risultati.
Il channel dei jobs viene scritto in questo esempio da un unico produttore, ma letto da molti consumatori: deve essere bufferizzato o si verificano ritardi.
Il channel dei risultati ha molti produttori ma un unico consumatore e il suo svuotamento è determinato dalla velocità del consumatore. Se è bufferizzato si può causare un burst di lavoro, se non lo è diventa rate-limited. Va pianificato.
Esempio
(340worker-pools.go):
package main
import "fmt"
import "time"
// Funzione worker che riceve dati e comunica
// su due channel monodirezionali
func worker(id int, jobs <-chan int, results chan<- int) {
// range consuma i job dal channel
// bloccandosi se non ne trova
for j := range jobs {
fmt.Println("wk", id, ": processing job", j)
// Attesa di un secondo
time.Sleep(time.Second)
// Risultato è il doppio nel numero del job
results <- j * 2
}
}
func main() {
// Creazione di channel per i job e i risultati
// Quello dei job deve essere bufferizzato con
// sufficienti elementi o si rischia il blocco
jobs := make(chan int, 100)
// Quello dei risultati può anche non essere
// bufferizzato poichè ha un solo consumatore
// results := make(chan int)
results := make(chan int, 100)
// Un pool di 3 worker
// inizialmente bloccati perchè non hanno ancora jobs
for w := 1; w <= 3; w++ {
go worker(w, jobs, results)
}
// Invio di 9 jobs
for j := 1; j <= 9; j++ {
jobs <- j
}
// Chiusura del channel, termina i worker
close(jobs)
// Raccolta dei risultati
for a := 1; a <= 9; a++ {
res := <-results
fmt.Println("main: result ", res)
}
// Sappiamo esattamente quanti sono i risultati
// Se invece usiamo il codice seguente si blocca
// for {
// res := <-results
// fmt.Println("main: result ", res)
// }
}
Se non sappiamo a priori quanti sono i job da leggere, occorre un loop infinito e un meccanismo per informare il main di smettere di ascoltare il channel dei risultati.
Channel di compimento lavoro
Come al solito la soluzione è un channel extra in cui ogni worker che termina segnala il fatto con il proprio id.
Il main attende la terminazione di tutti i worker prima di finire.
(341-worker-stop.go):
package main
import (
"fmt"
"time"
)
func worker(id int, jobs <-chan int, results chan<- int, done chan<- int) {
for j := range jobs {
fmt.Println("wk", id, ": processing job", j)
time.Sleep(time.Second)
results <- j * 2
}
done <- id
fmt.Printf("worker %d exiting\n", id)
}
func main() {
const numworkers int = 3
jobs := make(chan int, 100)
results := make(chan int, 100)
done := make(chan int, numworkers)
for w := 1; w <= numworkers; w++ {
go worker(w, jobs, results, done)
}
for j := 1; j <= 9; j++ {
jobs <- j
}
close(jobs)
finished := 0
loop:
for {
select {
case res := <-results:
fmt.Println("main: result ", res)
case n := <-done:
fmt.Printf("worker %d has finished\n", n)
finished++
if finished >= numworkers {
break loop
}
}
}
fmt.Println("main exiting")
}
Limiti di Tempo
Tramite i ticker è possibile rallentare l'utilizzo della risorsa CPU.
Esempio
(350rate-limiting.go):
// Rallentatore di utilizzo risorse
// Usa goroutines, channels e tickers
package main
import "time"
import "fmt"
func main() {
// Primo semplice esempio
fmt.Println("First 5 every 2seconds")
// Un channel che contiene tutte le richieste
requests := make(chan int, 5)
// Le richieste partono veloci e vengono bufferizzate
for i := 1; i <= 5; i++ {
requests <- i
}
// E' importante la chiusura per segnalare
// la terminazione di richieste
close(requests)
// limiter riceve un valore ogni 2 secondi
// E' il regolatore di velocità
limiter := time.Tick(time.Millisecond * 2000)
// Una richiesta ogni 2 secondi
// finchè il canale non viene chiuso
for req := range requests {
// attende il tick
<-limiter
fmt.Println("request", req, time.Now())
}
// Secondo esempio: burst limiter
fmt.Println("Second")
// Channel bufferizzato abbastanza capiente
burstyLimiter := make(chan time.Time, 3)
// Un burst di 3 richieste quasi con la stessa ora
for i := 0; i < 3; i++ {
burstyLimiter <- time.Now()
}
// Va avanti per sempre a scandire 3 secondi
go func() {
// Ogni tick mette l'ora nel channel
for t := range time.Tick(time.Millisecond * 3000) {
burstyLimiter <- t
}
}()
// Channel di 10 elementi subito riempito
burstyRequests := make(chan int, 10)
for i := 1; i <= 10; i++ {
burstyRequests <- i
}
close(burstyRequests)
// Scandisce il channel
fmt.Println("The first 3 all at once emptying the channel")
fmt.Println("Then every 3 seconds")
for req := range burstyRequests {
// I primi tre hanno quasi la stessa ora
// e arrivano subito
// Gli altri arrivanodopo 3 secondi
<-burstyLimiter
fmt.Println("request", req, time.Now())
}
}
Contatori Atomici
Se più goroutine tentano di accedere in scrittura alla stessa variabile, si ha una condizione di corsa.
E' necessario che tale variabile sia gestita atomicamente, cioè con accesso garantito singolo.
Nell'esempio è un contatore che viene incrementato da molte goroutines in esecuzione simultanea.
Un certo numero di funzioni del packagesync/atomic permettono le operazioni atomiche, tra cui:
LoadUint64- letturaAddUint64- incremento
Tali funzioni operano sulla variabile per riferimento.
Esempio
(360atomic-counters.go):
package main
import "fmt"
import "time"
import "sync/atomic"
import "runtime"
func main() {
// Un unico contatore
var ops uint64 = 0
// 50 goroutine che simultaneamente incrementano il
// singolo contatore
for i := 0; i < 50; i++ {
go func() {
for {
// Incrementa il contatore
// L'operazione è atomica cioè
// garantisce l'accesso esclusivo
atomic.AddUint64(&ops, 1)
// Passa il controllo allo schedulatore
// per permettere il run delle
// altre goroutine
runtime.Gosched()
}
}()
}
// Attende un secondo per dare tempo
// a tutte le goroutine di partire
time.Sleep(time.Second)
// Non è possibile un semplice Println del contatore
// Occorre copiarlo atomicamente in una variabile
opsNow := atomic.LoadUint64(&ops)
fmt.Println("ops:", opsNow)
// Attene ancora un secondo e stampa di nuovo
time.Sleep(time.Second)
// Notare che la variabile ha già un tipo
// quindi si usa = non :=
opsNow = atomic.LoadUint64(&ops)
fmt.Println("ops:", opsNow)
}
E' opportuno che subito dopo le operazioni atomiche il controllo passi allo schedulatore, con la funzione Gosched del package runtime, per permettere ad altre goroutines di essere attivate.
Se tale funzione non è invocata in questo esempio il programma rimane appeso.
Senza contatore atomico
E' possibile non usare il contatore atomico come nel seguente programma:
(361-non-atomic-counters.go):
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
var ops uint64 = 0
for i := 0; i < 1; i++ {
go func() {
for {
ops++
runtime.Gosched()
}
}()
}
time.Sleep(time.Second)
opsNow := ops
fmt.Println("ops:", opsNow)
time.Sleep(time.Second)
opsNow = ops
fmt.Println("ops:", opsNow)
}
Il programma sembra funzionare correttamente, ma in realtà avvengono dei problemi sottostanti non segnalati.
Provare a lanciarlo con:
go run -race 36a-non-atomic-counters.go
Viene segnalata la condizione di corsa. Con -race viene caricato il modulo di gestione appropriato.
Notare che anche se riduciamo il numero di goroutines create a 1 sola, viene segnalata la condizione di corsa.
Attenzione
Ogni volta che una goroutine accede ad una variabile non locale in modo diretto, cioè non tramite un channel, c'è la possibilità di condizioni di corsa.
Mutex
Mentre la gestione atomica serve per accedere in modo esclusivo a variabili, un mutex (mutual exclusion lock) serve a garantire che il codice delimitato dalle funzioni Lock e Unlock sia eseguito da una sola goroutine.
Tale codice delimitato si chiama sezione critica ed è opportuno che sia la più breve possibile.
Un mutex è una struttura sync.Mutexgestita per riferimento.
Il codice &sync.Mutex{} la crea e ne restituisce l'indirizzo.
Esempio
(370mutexes.go):
package main
import (
"fmt"
"math/rand"
"runtime"
"sync"
"sync/atomic"
"time"
)
func main() {
// Rappresentiamo lo stato con una map
var state = make(map[int]int)
// Variabile per la sincronizzazione dell'accesso
var mutex = &sync.Mutex{}
// Variabile per contare le operazioni eseguite
var ops int64 = 0
// 100 goroutine simultanee per leggere lo stato
for r := 0; r < 100; r++ {
go func() {
// Una variabile per il totale
total := 0
for {
// Scelta di una chiave a caso
key := rand.Intn(5)
// Blocco col mutex
mutex.Lock()
// Incremento del totale col valore
// dell'elemento della mappa
total += state[key]
// Sblocco col mutex
mutex.Unlock()
// Incremento del contatore
atomic.AddInt64(&ops, 1)
// Ripassa il controllo allo schedulatore
runtime.Gosched()
}
}()
}
// 10 goroutine che scrivono valori casuali nella mappa
for w := 0; w < 10; w++ {
go func() {
for {
// Selezione casuale della chiave
key := rand.Intn(5)
// Selezione casuale del valore da scriverci
val := rand.Intn(100)
// Blocco col mutex
mutex.Lock()
// Scrittura del valore
state[key] = val
// Sblocco col mutex
mutex.Unlock()
// Incremento atomico delle operazioni
atomic.AddInt64(&ops, 1)
// Ripassa il controllo allo schedulatore
runtime.Gosched()
}
}()
}
// Lascia lavorare per un secondo
time.Sleep(time.Second)
// Copia atomica del valore di ops e stampa
opsFinal := atomic.LoadInt64(&ops)
fmt.Println("ops:", opsFinal)
// Stampa dell'intera mappa con blocco col mutex
mutex.Lock()
fmt.Println("state:", state)
mutex.Unlock()
}
E' molto comune che lo stato di un programma sia rappresentato tramite una map.
Senza mutex
Per vedere qual'è il comportamento senza l'uso del mutex commentiamo le linee che lo usano.
(371-no-mutex.go):
package main
import (
"fmt"
"math/rand"
"runtime"
// "sync"
"sync/atomic"
"time"
)
func main() {
// Rappresentiamo lo stato con una map
var state = make(map[int]int)
// Variabile per la sincronizzazione dell'accesso
// var mutex = &sync.Mutex{}
// Variabile per contare le operazioni eseguite
var ops int64 = 0
// 2 goroutine simultanee per leggere lo stato
for r := 0; r < 2; r++ {
go func() {
// Una variabile per il totale
total := 0
for {
// Scelta di una chiave a caso
key := rand.Intn(5)
// Blocco col mutex
// mutex.Lock()
// Incremento del totale col valore
// dell'elemento della mappa
total += state[key]
// Sblocco col mutex
// mutex.Unlock()
// Incremento del contatore
atomic.AddInt64(&ops, 1)
// Ripassa il controllo allo schedulatore
runtime.Gosched()
}
}()
}
// 2 goroutine che scrivono valori casuali nella mappa
for w := 0; w < 2; w++ {
go func() {
for {
// Selezione casuale della chiave
key := rand.Intn(5)
// Selezione casuale del valore da scriverci
val := rand.Intn(100)
// Blocco col mutex
// mutex.Lock()
// Scrittura del valore
state[key] = val
// Sblocco col mutex
// mutex.Unlock()
// Incremento atomico delle operazioni
atomic.AddInt64(&ops, 1)
// Ripassa il controllo allo schedulatore
runtime.Gosched()
}
}()
}
// Lascia lavorare per un secondo
time.Sleep(time.Second)
// Copia atomica del valore di ops e stampa
opsFinal := atomic.LoadInt64(&ops)
fmt.Println("ops:", opsFinal)
// Stampa dell'intera mappa con blocco col mutex
// mutex.Lock()
fmt.Println("state:", state)
// mutex.Unlock()
}
Go ha un modulo runtime di detezione di condizioni di corsa, che impedisce la scrittura simultanea di una variabile da parte di due goroutines. Viene caricato con l'opzione -race.
Goroutines Stateful
Il problema di garantire l'integrità dei dati si può anche risolvere incaricando una sola goroutine della responsabilità di accedervi.
Tutte le altre goroutine che vogliono leggere e/o scrivere dati lo chiedono alla goroutine preposta tramite operazioni su channels.
Esempio
(380stateful-goroutines.go):
// I channels sono già primitive di sincronizzazione
package main
import (
"fmt"
"math/rand"
"sync/atomic"
"time"
)
// Lo stato sarà possesso esclusivo di una goroutine
// Le altre goroutine chiedono letture e scritture
// tramite dei chan
// Struct per la lettura
type readOp struct {
key int // chiave
resp chan int // responso
}
// Struct per la scrittura
type writeOp struct {
key int // chiave
val int // valore
resp chan bool // conferma
}
func main() {
// Contatore delle operazioni compiute\
var ops int64 = 0
// Channels usati dalle altre goroutines
// Channel di lettura
// Notare che sono puntatori alle struct
// così sono modificabili gli originali
reads := make(chan *readOp)
// Channel di scrittura
writes := make(chan *writeOp)
// Goroutine che controlla lo stato
go func() {
// Mappa che rappresenta lo stato
var state = make(map[int]int)
for {
// Scandisce i canali di comunicazione
select {
case read := <-reads:
// Fornisce il valore richiesto
read.resp <- state[read.key]
case write := <-writes:
// Scrive il valore fornito
state[write.key] = write.val
// Conferma l'avvenuta scrittura
write.resp <- true
}
}
}()
// 100 goroutine che leggono
for r := 0; r < 100; r++ {
go func() {
for {
// Costruisce una struct readOp
// e ne ottiene l'indirizzo
read := &readOp{
key: rand.Intn(5),
resp: make(chan int)}
// La pone nel canale di lettura
reads <- read
// Legge il responso
<-read.resp
// Aumenta atomicamente il conto
// delle opeazioni eseguite
atomic.AddInt64(&ops, 1)
}
}()
}
// 10 goroutines che scrivono
for w := 0; w < 10; w++ {
go func() {
for {
// Costruisce la struct writeOp
// e ne ottiene l'indirizzo
write := &writeOp{
key: rand.Intn(5),
val: rand.Intn(100),
resp: make(chan bool)}
// La manda al canale di scrittura
writes <- write
// Attende il responso di avvenuto
<-write.resp
// Incrementa il contatore operazioi
atomic.AddInt64(&ops, 1)
}
}()
}
// Attendiamo un secondo
time.Sleep(time.Second)
// Vediamo il numero di operazioni eseguite
opsFinal := atomic.LoadInt64(&ops)
fmt.Println("ops:", opsFinal)
// Per stampare la mappa bisogna chiedere
// ogni valore alla goroutine responsabile
fmt.Print("[ ")
for c := 0; c < 5; c++ {
read := &readOp{
key: c,
resp: make(chan int)}
reads <- read
cval := <-read.resp
fmt.Printf("%d:%d ", c, cval)
}
fmt.Println("]")
}
Notare che i channel di comunicazione sono delle struct, e sono gestite per riferimento perchè è necessario cambiare il valore dei campi.
La struct di lettura ha i campi:
key- chiave della mappa da leggereresp- responso: valore trovato a quella chiave. E' un channel del tipo dei valori della map
La struct di scrittura ha i campi:
key- chiave della mappa da scrivereval- valore da scrivere a quella chiaveresp- canale di responso, booleano, per confermare che la scrittura è avvenuta
Notare che anche il main per accedere alla mappa di stato deve seguire il protocollo corretto, chiedendo alla goroutine preposta.
Esercizi
Esercizio 501
Una goroutine ogni 5 secondi scrive quanto manca allo scadere del minuto, p.es:
Mancano 60 secondi
Mancano 55 secondi
...
Implementarla con un timer
Implementarla con un ticker
Fare in modo che si possa interrompere premendo INVIO
Esercizio 502
Inventarsi un array di 20 numeri interi.
Scrivere due goroutines:
- una ne calcola il massimo
- l’altra ne calcola il minimo
Le goroutines passano il loro risultato al main, senza stamparo a video. Quando entrambe hanno finito, il main stampa i risultati.
Esercizio 503
Un conto A ha un saldo di 7000, un conto B ha un saldo di 3000.
Una goroutine esegue un bonifico da A a B di un numero casuale tra -200 e +200
- La goroutine non esegue il bonifico se i fondi del conto sorgente sono insufficienti.
Incrementare il numero di goroutines:
- 3 goroutines simultanee eseguono un tale bonifico
- 100 goroutines simultanee eseguono il bonifico
Al termine il main stampa i saldi e verifica che la somma sia 10000.
Aumentare il bonifico all’intervallo -2000 e +2000.
Utilities
Vi sono moltissime funzioni nella libreria core per la gestione di aspetti disparati della programmazione.
Di nota:
- gestione stringhe
- sorting
- gestione del tempo
- espressioni regolari
- interfaccia con JSON
- trascodifica in Base64
- algoritmi di hash e di crittografazione
Sort
Le funzioni di sortizzazione sono offerte dal package sort.
Vi sono molte funzioni e dipendono dal tipo del dato trattato.
Sorting di slice di interi e stringhe
(390sorting.go):
package main
import "fmt"
import "sort"
func main() {
// I metodi di sort sono specifici di tipo
// Il sorting di una slice modifica la stessa slice
// non crea una copia
strs := []string{"c", "a", "b"}
sort.Strings(strs)
fmt.Println("Strings:", strs)
// Sort di interi
ints := []int{7, 2, 4}
sort.Ints(ints)
fmt.Println("Ints: ", ints)
// Verifica se una slice è già sortizzata
s := sort.IntsAreSorted(ints)
fmt.Println("Sorted: ", s)
}
Una slice è mutevole, e le funzioni di sort su slice modificano la slice stessa, non una copia.
Sorting di array di interi
Non è possibile sortizzare un array direttamente bisogna prima trasformarlo in slice.
(391-sort-array.go):
package main
import (
"fmt"
"sort"
)
func main() {
fmt.Println("--- sorting a slice ---")
// La seguente è una slice
slice := []int{7, 4, 5, 10, 1, 9, 3, 6, 8, 2}
slice1 := slice
fmt.Println("original slice: ", slice)
fmt.Println("copy of slice: ", slice1)
// Le slice si possono sortizzare direttamente\
sort.Ints(slice)
fmt.Println("sorted slice: ", slice)
fmt.Println("copy of slice: ", slice1)
fmt.Println("--- sorting an array ---")
// Questo è un array
// [...] dice di dedurne la dimensione
array := [...]int{7, 4, 5, 10, 1, 9, 3, 6, 8, 2}
array1 := array
fmt.Println("original array: ", array)
fmt.Println("copy of array: ", array1)
// Per sortizzare un array bisogna
// trasformarlo in una slice
sort.Ints(array[:])
// Il codice seguente non funziona
// sort.Ints(array)
fmt.Println("sorted array: ", array)
fmt.Println("copy of array: ", array1)
}
Come si nota una slice è gestita per riferimento, mentre un array è gestito per valore.
La stessa tecnica è da adottare anche per arrays di altri tipi dati.
Sort con Funzioni
Esistono funzioni di libreria di sorting già redatte, ma solo in numerp limitato.
Chiunque può implementare il sorting solo implementando l'interfaccia sort.Interfaceche richiede la definizione delle funzioni:
Len- lunghezza dell'oggetto da sortizzareSwap- come invertire nell'ordine due oggetti da sortizzareLess- quale dei due oggetti paragonati è minore, secondo i nostri criteri di Sortizzazione
Dati due record, infatti, dipende dal modello del dominio dell'applicazione decidere in quale ordine debbano essere organizzati i record, e con quale criterio.
L'esempio seguente ordina stringhe per lunghezza.
(400sorting-by-functions.go):
// Per sortizzare stringhe per lunghezza occorre
// fornire funzioni custom
package main
import "sort"
import "fmt"
// Per compiere un sort con funzioni custom occorre un tipo
// che può essere un alias di un tipo corrente
// Una slice di stringhe
type ByLength []string
// Occorre implementare l'interfaccia sort.Interface
// per poter usare la funzione Sort
// Questa richiede la definizione delle funzioni
// Len, Swap e Less
// Len ritorna la lunghezza della stringa
func (s ByLength) Len() int {
return len(s)
}
// Swap inverte due stringhe della slice
// i e j sono gli indici
func (s ByLength) Swap(i, j int) {
// Fantastico! Il primo swap senza
// variabili d'appoggio intermedie
s[i], s[j] = s[j], s[i]
}
// Less contiene la logica
// Determina quale stringa è 'minore' ovvero viene
// prima dell'altra secondo il nostro criterio
func (s ByLength) Less(i, j int) bool {
return len(s[i]) < len(s[j])
}
func main() {
// Slice originale
fruits := []string{"peach", "banana", "kiwi"}
// Sortizzazione
sort.Sort(ByLength(fruits))
// Stampa del risultato
fmt.Println(fruits)
}
Panic
La funzione panic causa un'uscita immediata dal processo, con stampa dello stack trace su standard error.
(410panic.go):
package main
import "os"
func main() {
// La funzione panic termina immediatamente
// il programma con un messaggio d'errore
// e uno stack trace
// Il seguente codice causerebbe un panic
// panic("a problem")
// Si usa comunemente per abortire il programma
// in caso di errore non recuperabile
_, err := os.Create("/file")
if err != nil {
panic(err)
}
}
La funzione panic non appartiene ad un package, ma è una funzione primitiva del linguaggio Go stesso.
Recupero da panic
E' possibile uscire da un panic prima che venga eseguito.
Il panic prima di uscire esegue tutte le funzioni differite in ordine inverso dalla loro registrazione.
Una di queste può cancellare il panic con la funzione recover.
(411-panic-recover.go):
package main
import "fmt"
func panicRecover() {
// defer: funzione eseguita all'uscita
// dalla funzione corrente
defer fmt.Println("Deferred call - 1")
defer func() {
fmt.Println("Deferred call - 2")
// E' possibile cancellare un panic
if e := recover(); e != nil {
// e è il valore passato a panic
fmt.Println("Recover with: ", e)
}
}()
panic("Just panicking")
// Tutti i defer vengono eseguiti, poi termina
// defer eseguite in ordine inverso dalla registrazione
fmt.Println("This will never be called")
}
func main() {
fmt.Println("Starting to panic")
panicRecover()
fmt.Println("Program regains control")
}
Notare che la funzione che invoca il panic non viene ripresa dopo il recover. Il controllo ritorna al main che l'ha invocata.
Defer
Il comando defer registra una funzione che viene eseguita al termine della goroutine corrente o del main.
Se sono registrate più funzioni in defer, esse vengono eseguite in ordine inverso di registrazione.
Le funzioni in defer sono sempre eseguite, anche in caso di panic.
(420defer.go):
package main
import "fmt"
import "os"
func main() {
// Crea un file
f := createFile("/tmp/defer.txt")
// Deferisce la chiusura al termine della funzione main
defer closeFile(f)
// Scrive il file
writeFile(f)
}
func createFile(p string) *os.File {
fmt.Println("creating")
f, err := os.Create(p)
if err != nil {
panic(err)
}
return f
}
func writeFile(f *os.File) {
fmt.Println("writing")
fmt.Fprintln(f, "data")
}
func closeFile(f *os.File) {
fmt.Println("closing")
f.Close()
}
E' buona norma, quando si ottiene una risorsa (file descriptor, connessione a database o rete, ecc), registrare subito in defer la funzione che rilascia la risorsa. Questo è particolarmente importante nel caso di goroutine. Se una goroutine termina e non rilascia una risorsa, le altre routine attive e il main potrebbero non essere più in grado di accedere a tale risorsa.
Funzioni per Collezioni
Le collezioni in Go sono essenzialmente mappe, slice e array (e gli array sono poco usati).
Una collezione è di qualcosa. Go non ha un meccanismo nativo per parametrizzare tale qualcosa, cioè non ha generics come Java.
Qualsiasi funzione operi su una collezione deve essere esplicitamente definita per ogni caso specifico di collezione.
Non esistono definizioni parametriche, come in Java o C++.
(430collection-functions.go):
// Go non supporta 'generics' come Java o C++
// Le funzioni che operano su collezioni devono
// essere scritte quando servono
package main
import "strings"
import "fmt"
// Ritorna il primo indice della stringa t
// o -1 se non trovata
func Index(vs []string, t string) int {
// i è l'indice, v una stringa della slice
for i, v := range vs {
if v == t {
return i
}
}
return -1
}
// Ritorna true se la stringa t è nella slice
func Include(vs []string, t string) bool {
return Index(vs, t) >= 0
}
// Ritorna true se una delle stringhe nella slice
// soddisfa il predicato f
// Il predicato è una funzione di filtro che deve
// essere fornita come parametro attuale
func Any(vs []string, f func(string) bool) bool {
for _, v := range vs {
if f(v) {
return true
}
}
return false
}
// Ritorna true se tutte le stringhe nella slice
// soddisfano il predicato f
func All(vs []string, f func(string) bool) bool {
for _, v := range vs {
if !f(v) {
return false
}
}
return true
}
// Ritorna una nuova slice contenente tutte le stringhe
// che soddisfano il predicato f
func Filter(vs []string, f func(string) bool) []string {
vsf := make([]string, 0)
for _, v := range vs {
if f(v) {
vsf = append(vsf, v)
}
}
return vsf
}
// Ritorna una nuova slice contenente i risultati
// dell'applicare la funzione f ad ogni stringa della
// slice originale
func Map(vs []string, f func(string) string) []string {
vsm := make([]string, len(vs))
for i, v := range vs {
vsm[i] = f(v)
}
return vsm
}
func main() {
// Prova delle varie funzioni su collezioni
var strs = []string{"peach", "apple", "pear", "plum"}
fmt.Println(Index(strs, "pear"))
fmt.Println(Include(strs, "grape"))
// HasPrefix - libreria
fmt.Println(Any(strs, func(v string) bool {
return strings.HasPrefix(v, "p")
}))
fmt.Println(All(strs, func(v string) bool {
return strings.HasPrefix(v, "p")
}))
// Contains - libreria
fmt.Println(Filter(strs, func(v string) bool {
return strings.Contains(v, "e")
}))
// Sono state usate funzioni anonime, ma si possono
// anche usare funzioni col nome del tipo corretto
// ToUpper converte a maiuscole - libreria
fmt.Println(Map(strs, strings.ToUpper))
}
Una segnatura molto comune delle funzioni di gestione collezioni ha come lista parametri:
- la collezione da trattare passata per riferimento
- una funzione di trattamento da applicare alla collezione
e ritorna un valore di qualche tipo.
Se la funzione di trattamento ritorna un booleano, viene detta funzione predicato.
Funzioni Stringa
Esiste un numero notevole di funzioni di trattamento stringhe già inserite nellalibreria standard, nel package strings.
(440string-functions.go):
package main
import s "strings"
import "fmt"
// Alias della funzione per accorciare il codice
var p = fmt.Println
func main() {
// Esempi di funzioni stringa
p("Count: ", s.Count("test", "t"))
p("HasPrefix: ", s.HasPrefix("test", "te"))
p("HasSuffix: ", s.HasSuffix("test", "st"))
p("Index: ", s.Index("test", "e"))
p("Join: ", s.Join([]string{"a", "b"}, "-"))
p("Repeat: ", s.Repeat("a", 5))
p("Replace: ", s.Replace("foo", "o", "0", -1))
p("Replace: ", s.Replace("foo", "o", "0", 1))
p("Split: ", s.Split("a-b-c-d-e", "-"))
p("ToLower: ", s.ToLower("TEST"))
p("ToUpper: ", s.ToUpper("test"))
p()
// Altre funzioni sulle stringhe che non sono
// parte del modulo strings
p("Len: ", len("hello"))
p("Char:", "hello"[1])
}
Notare che l'istruzione var p = fmt.Println è effettivamente una macro, cioè una sostituzione lessicale.
Anche la definizione di s come alias di string è una macro lessicale.
Formattazione Stringhe
La funzione Printf() del package fmt produce stringhe formattate con un meccanismo molto simile a quello del C, C++ e Java.
Attenzione però che i segnalini posizionali disponibili sono leggermente diversi e propri di Go.
(450string-formatting.go):
package main
import "fmt"
import "os"
type point struct {
x, y int
}
func main() {
// Valori di oggetto composto
p := point{1, 2}
fmt.Printf("%v\n", p)
// Chiavi e valori di una struct
fmt.Printf("%+v\n", p)
// Rappresentazione in sintassi Go
fmt.Printf("%#v\n", p)
// Tipo di un valore
fmt.Printf("%T\n", p)
// Valore booleano
fmt.Printf("%t\n", true)
// Intero decimale
fmt.Printf("%d\n", 123)
// Intero in rappresentazione binaria
fmt.Printf("%b\n", 14)
// Carattere corrispondente a un valore Unicode
fmt.Printf("%c\n", 33)
// Intero in esadecimale
fmt.Printf("%x\n", 456)
// Float
fmt.Printf("%f\n", 78.9)
// Float in rappresentazione scientifica
fmt.Printf("%e\n", 123400000.0)
fmt.Printf("%E\n", 123400000.0)
// Stringa
fmt.Printf("%s\n", "\"string\"")
// Stringhe con doppio quoting
fmt.Printf("%q\n", "\"string\"")
// Stringhe in base-16 due caratteri per byte
fmt.Printf("%x\n", "hex this")
// Puntatore
fmt.Printf("%p\n", &p)
// Intero con larghezza di campo, a destra
fmt.Printf("|%6d|%6d|\n", 12, 345)
// Float con larghezza di campo e numero decimali
fmt.Printf("|%6.2f|%6.2f|\n", 1.2, 3.45)
// Allineato a sinistra
fmt.Printf("|%-6.2f|%-6.2f|\n", 1.2, 3.45)
// Larghezza di campo per stringhe, a destra
fmt.Printf("|%6s|%6s|\n", "foo", "b")
// Larghezza di campo per stringhe, a sinistra
fmt.Printf("|%-6s|%-6s|\n", "foo", "b")
// Stampa dentro una stringa
s := fmt.Sprintf("a %s", "string")
fmt.Println(s)
// Stampa ad altro 'file' qui standard error
fmt.Fprintf(os.Stderr, "an %s\n", "error")
}
La funzione Fprintf() è interessante: prende come ulteriore primo argomento il file descriptor a cui inviare la stampa.
La funzione Printf() invia la stampa a standard output.
I tre file descriptor di default dei processi Unix sono in Go rappresentati con os.Stdin, os.Stdout e os.Stderr.
Ma dato che in Unix un file è un file e può essere qualsiasi cosa sia leggibile o scrivibile, il primo argomanto può essere anche:
- un file descriptor di file aperto
- una connessione a database
- una connessione di rete
- un identificativo di web server
- ...
Espressioni Regolari
Il package regexp contiene le funzioni per la gestione di espressioni regolari.
La sintassi particolare delle espressioni regolari in uso è la PCRE (Perl Compatible Regular Expressions).
Ogni funzione di questo package ritorna come ultimo risultato un errore.
(460regular-expressions.go):
package main
import "bytes"
import "fmt"
import "regexp"
func main() {
// Il primo argomento è un booleano
// Il secondo argomento è un errore
match, _ := regexp.MatchString("p([a-z]+)ch", "peach")
fmt.Println(match)
// Compila l'espressione regolare nell'oggetto r
r, _ := regexp.Compile("p([a-z]+)ch")
// Match di stringa con l'oggetto r - booleano
fmt.Println(r.MatchString("peach"))
// Prima occorrenza del patter
fmt.Println(r.FindString("peach punch"))
// Indice di inizio e fine della prima occorrenza
fmt.Println(r.FindStringIndex("peach punch"))
// Sia l'intero pattern che i submatch
// sia `p([a-z]+)ch` che `([a-z]+)`.
fmt.Println(r.FindStringSubmatch("peach punch"))
// Indici dei match e dei submatch
fmt.Println(r.FindStringSubmatchIndex("peach punch"))
// Tutti i match, non solo il primo
fmt.Println(r.FindAllString("peach punch pinch", -1))
// Indici dei match e submatch di tutte le stringhe
fmt.Println(r.FindAllStringSubmatchIndex(
"peach punch pinch", -1))
// Limite ai primi 2 match
fmt.Println(r.FindAllString("peach punch pinch", 2))
// Match su un array di byte
fmt.Println(r.Match([]byte("peach")))
// Crea una costante contenente un'espressione regolare
// 'Compile' avrebbe ritornato due valori
r = regexp.MustCompile("p([a-z]+)ch")
fmt.Println(r)
// Rimpiazzo di stringa
fmt.Println(r.ReplaceAllString("a peach", "<fruit>"))
// Applicazione di funzione al match
in := []byte("a peach")
out := r.ReplaceAllFunc(in, bytes.ToUpper)
fmt.Println(string(out))
}
Le funzioni regexp nude hanno due o più argomenti:
- l'espressione regolare
- il parametro d'azione sull'espressione regolare
- eventuali opzioni
Go permette un metodo particolare di trattamento, la compilazione dell'espressione regolare in un oggetto con la funzione Compile.
Ora tutte le funzioni regexp diventano metodi dell'oggetto, e hanno un parametro in meno.
JSON
Vi sono molte funzioni per il trattamento di dati JSON (JavScript Object Notation), poichè è un formato molto usato nella comunicazione dati tra un server web e un browser.
Le due funzioni principali sono:
Marshal- codifica da Go a JSONUnmarshal- codifica da JSON a Go
E' possibile codificare dati singoli, collezioni (arrays, slices, maps) e structs.
Nel marshalling di struct i nomi dei campi diventano di default i tag dei dati JSON.
Ma è possibile commentare ogni campo di struct indicando il tag JSON che deve avere.
(470json.go):
package main
import "encoding/json"
import "fmt"
import "os"
// Strutture per l'esercizio
type Response1 struct {
Page int
Fruits []string
}
// I tag forniscono la rappresentazione JSON
// minuscole anzichè maiuscole
type Response2 struct {
Page int `json:"page"`
Fruits []string `json:"fruits"`
}
func main() {
// Codifica di valori singoli
bolB, _ := json.Marshal(true)
fmt.Println(string(bolB))
intB, _ := json.Marshal(1)
fmt.Println(string(intB))
fltB, _ := json.Marshal(2.34)
fmt.Println(string(fltB))
strB, _ := json.Marshal("gopher")
fmt.Println(string(strB))
// Codifica di slice
slcD := []string{"apple", "peach", "pear"}
slcB, _ := json.Marshal(slcD)
fmt.Println(string(slcB))
// Codifica di mappa
mapD := map[string]int{"apple": 5, "lettuce": 7}
mapB, _ := json.Marshal(mapD)
fmt.Println(string(mapB))
// Codifica di struct
// Notare che Marsal vuole un indirizzo
res1D := &Response1{
Page: 1,
Fruits: []string{"apple", "peach", "pear"}}
res1B, _ := json.Marshal(res1D)
fmt.Println(string(res1B))
// Codifica JSON usando i tag della struct
res2D := &Response2{
Page: 1,
Fruits: []string{"apple", "peach", "pear"}}
res2B, _ := json.Marshal(res2D)
fmt.Println(string(res2B))
// Struttura dati generica in formato JSON
byt := []byte(`{"num":6.13,"strs":["a","b"]}`)
// Map che conterrà i dati decodificati
var dat map[string]interface{}
// Decodifica con controllo errori
if err := json.Unmarshal(byt, &dat); err != nil {
panic(err)
}
fmt.Println(dat)
// Occorre compiere il cast dei valori della map
// Il campo num è un float
num := dat["num"].(float64)
fmt.Println(num)
// I dati innestati richiedono una serie di cast
strs := dat["strs"].([]interface{})
str1 := strs[0].(string)
fmt.Println(str1)
// I dati JSON possono essere decodificati in
// un'interfaccia fornita
str := `{"page": 1, "fruits": ["apple", "peach"]}`
// Una struct è un'interfaccia
res := Response2{}
json.Unmarshal([]byte(str), &res)
fmt.Println(res)
fmt.Println(res.Fruits[0])
// Si può mandare la codifica JSON direttamente a stdout
// Occorre generare un codificatore apposito
enc := json.NewEncoder(os.Stdout)
d := map[string]int{"apple": 5, "lettuce": 7}
enc.Encode(d)
}
Lo unmarshalling si compie con due argomenti:
- una slice di byte, che è il formato JSON
- l'indirizzo della destinazione Go, che può essere:
- una map
- una struct
Nel caso di una map ogni dato recuperato deve subire un cast al tipo appropriato, ponendo particolare attenzione a compiere il cast anche dei dati innestati.
Nel caso di una struct, i tipi sono automaticamente convertiti nei tipi dei campi della struct riceventi.
Gestione del Tempo
Le funzioni di gestione del tempo sono offerte dal package time.
Un tempo è rappresentato come timestamp ISO.
Esistono funzioni di estrazione dei vari componenti del timestamp.
Esistono anche funzioni per il paragone di timestamps e per la loro modifica in aggiunta o in differenza.
La funzione Now estrae il timestamp corrente.
(480time.go):
package main
import "fmt"
import "time"
func main() {
// Alias per la funzione
p := fmt.Println
// Il timestamp del momento corrente
now := time.Now()
p(now)
// Costruzione di una struct con una data
then := time.Date(
2009, 11, 17, 20, 34, 58, 651387237, time.UTC)
p(then)
// Estrazione dei campi della struct
p(then.Year())
p(then.Month())
p(then.Day())
p(then.Hour())
p(then.Minute())
p(then.Second())
p(then.Nanosecond())
p(then.Location())
// Esiste anche il giorno della settimana
p(then.Weekday())
// Funzioni booleane per il paragone di date
p(then.Before(now))
p(then.After(now))
p(then.Equal(now))
// Differenza tra due date
diff := now.Sub(then)
p(diff)
// Estrazione dei componenti della differenza
p(diff.Hours())
p(diff.Minutes())
p(diff.Seconds())
p(diff.Nanoseconds())
// Modifica di data con una differenza
p(then.Add(diff))
p(then.Add(-diff))
}
Tempo Assoluto
Unix e Linux rappresentano i tempi come nanosecondi e millisecondi trascorsi da un'epoca di riferimento,che è la mezzanotte del primo gennaio, per Unix del 1970 e per Linux del 1980.
(490epoch.go):
package main
import "fmt"
import "time"
func main() {
// L'ora è tenuta internamente dai computer come tempo
// passato dalle ore 00:00:00 GMT del 1/1/70
// E' convenzione Unix che tutti gli orologi interni
// tengano GMT e la conversione avvenga con 'zoneinfo'
// Display in formato ISO
now := time.Now()
// Display in secondi
secs := now.Unix()
// Display in nanosecondi
nanos := now.UnixNano()
fmt.Println(now)
// I millisecondi devono essere calcolati
millis := nanos / 1000000
fmt.Println(secs)
fmt.Println(millis)
fmt.Println(nanos)
// Convertire un numero di secondi a formato ISO
fmt.Println(time.Unix(secs, 0))
// Con precisione Unix al nanosecondo
fmt.Println(time.Unix(0, nanos))
// I nanosecondi non sono mai precisi del tutto
// nemmeno per calcoli interni di differenze
// Lo schedulatore Unix ha risoluzione 1 millisecondo
// Non è detto che i valori siano accurati a meno
// che sia attivo il Network Time Protocol
}
Il fatto che un timestamp sia rappresentabile al nanosecondo (o anche al millisecondo) non è nessuna garanzia di verità.
Se il sistema riceve i tempi da un server NTP (Network Time Protocol), si può assumere al massimo un'accuratezza di un secondo.
Questa è una considerazione importante tenendo conto che si possono avere programmi in comunicazione remota a distanze globali (a livello del nanosecondo interverrebbero anche effetti relativistici).
Inoltre lo schedulatore Unix/Linux ha un Time Slice dell'ordine dei 10 millisecondi, e a questo livello quale sia la routine attiva diventa aleatorio.
Formattazione del Tempo
Per formattare i timestamp esistono principalmente le funzioni Parse() e Format().
(500time-formatting-parsing.go):
package main
import "fmt"
import "time"
func main() {
// Alias di Println
p := fmt.Println
// Formattazione secondo RFC 3399
t := time.Now()
p(t.Format(time.RFC3339))
// Parse di una stringa corretta per ottenere un tempo t1
t1, e := time.Parse(
time.RFC3339,
"2012-11-01T22:08:41+00:00")
p(t1)
// Il parse accetta varie stringhe, ma devono essere corrette
p(t.Format("3:04PM"))
p(t.Format("Mon Jan _2 15:04:05 2006"))
p(t.Format("2006-01-02T15:04:05.999999-07:00"))
form := "3 04 PM"
t2, e := time.Parse(form, "8 41 PM")
p(t2)
// Si può usare una stringa formattata ad hoc
fmt.Printf("%d-%02d-%02dT%02d:%02d:%02d-00:00\n",
t.Year(), t.Month(), t.Day(),
t.Hour(), t.Minute(), t.Second())
// Se la stringa non è corretta, segnala errore
ansic := "Mon Jan _2 15:04:05 2006"
_, e = time.Parse(ansic, "8:41PM")
p(e)
}
Numeri Casuali
I numeri casuali compaiono in molti ambiti applicativi e il package math/rand ne fornisce le funzioni.
I numeri in realtà sono pseudocasuali e vengono generatida un algoritmo deterministico a partire da un seme iniziale.
Il seme può essere iniettato, per esempio prendendolo dal timestamp corrente.
(519random-numbers.go):
package main
import "time"
import "fmt"
import "math/rand"
func main() {
// Numeri casuali interi 0<= n < 100
fmt.Print(rand.Intn(100), ", ")
fmt.Print(rand.Intn(100))
fmt.Println()
// Numero casuale float 0.0 <= f < 1
fmt.Println(rand.Float64())
// Con scala e shift: 5.0 <= f < 10
fmt.Print((rand.Float64()*5)+5, ", ")
fmt.Print((rand.Float64() * 5) + 5)
fmt.Println()
// Dato che l'algoritmo dei numeri casuali è deterministico
// è meglio generare una sorgente di 'seed'
// per esempio col tempo in nanosecondi
s1 := rand.NewSource(time.Now().UnixNano())
// E' generato r1 che usa il seed s1
r1 := rand.New(s1)
// E' r1 che genera i numeri casuali
fmt.Print(r1.Intn(100), ", ")
fmt.Print(r1.Intn(100))
fmt.Println()
// A parità di seed la sequenza di random è la stessa
s2 := rand.NewSource(42)
r2 := rand.New(s2)
fmt.Print(r2.Intn(100), ", ")
fmt.Print(r2.Intn(100))
fmt.Println()
s3 := rand.NewSource(42)
r3 := rand.New(s3)
fmt.Print(r3.Intn(100), ", ")
fmt.Print(r3.Intn(100))
fmt.Println()
}
La funzione NewSource genera un seed per i numeri casuali, con argomento un Numero intero. Questo viene spesso preso dal timestamp corrente espresso in nanosecondi.
Dopo la generazione del seed occore creare un oggetto generatore di numeri random basato sul seed.
Parsing dei Numeri
Una stringa viene convertita a numero di un tipo dato con funzioni del package strconv.
(520number-parsing.go):
package main
// Conversione di stringhe a numeri
import "strconv"
import "fmt"
func main() {
// Conversione a float con bits di precisione
f, _ := strconv.ParseFloat("1.234", 64)
fmt.Println(f)
// 0 dice di dedurre la base dalla stringa
i, _ := strconv.ParseInt("123", 0, 64)
fmt.Println(i)
// Numero esadecimale
d, _ := strconv.ParseInt("0x1c8", 0, 64)
fmt.Println(d)
// Numero ottale
o, _ := strconv.ParseInt("0123", 0, 64)
fmt.Println(o)
// Parse di intero senza segno
u, _ := strconv.ParseUint("789", 0, 64)
fmt.Println(u)
// Copia del vecchio 'atoi' del C
// In realtà è un alias per ParseInt
k, _ := strconv.Atoi("135")
fmt.Println(k)
// Errore se la stringa è malformata
_, e := strconv.Atoi("wat")
fmt.Println(e)
}
Parsing di URL
Una URL è composta da svariati elementi, che possono venire estratti con funzioni del package net/url.
(530url-parsing.go):
package main
import "fmt"
import "net"
import "net/url"
func main() {
// Questa URL include lo schema, autrnticazione, informazione
// host, porta, percorso, parametri e frammenti
s := "postgres://user:pass@host.com:5432/path?k=v#f"
// Parse di una URL e controllo errori
// u è una struct con campi e metodi
u, err := url.Parse(s)
if err != nil {
panic(err)
}
// Accesso allo schema
fmt.Println(u.Scheme)
// Accesso al campo autenticazione e suoi componenti
fmt.Println(u.User)
fmt.Println(u.User.Username())
p, _ := u.User.Password()
fmt.Println(p)
// Accesso a host e porta combinati
fmt.Println(u.Host)
// Accesso a host e porta separati
host, port, _ := net.SplitHostPort(u.Host)
fmt.Println(host)
fmt.Println(port)
// Componente percorso
fmt.Println(u.Path)
// Componente frammenti
fmt.Println(u.Fragment)
// Parametri come singola stringa
fmt.Println(u.RawQuery)
// Parametri in una map
m, _ := url.ParseQuery(u.RawQuery)
fmt.Println(m)
fmt.Println(m["k"][0])
}
Tutte queste funzioni ritornano come ultimo valore un errore.
Hash SHA1
Lo Secure Hash Algorithm 1 è uno degli algoritmi di hash crittografici disponibili in Go.
Lo si può gestire tramite funzioni del package crypto/sha1.
(540sha1-hashes.go):
package main
// Uno dei tanti package crittografici
import "crypto/sha1"
import "fmt"
func main() {
// Stringa di prova
s := "sha1 this string"
// Nuovo oggetto per il parsing
h := sha1.New()
// Deve operare su array di byte
h.Write([]byte(s))
// L'argomento permette l'append a una slice esistente
// Indicare 'nil' se non si usa
bs := h.Sum(nil)
fmt.Println(s)
// Stampa come stringa esadecimale
fmt.Printf("%x\n", bs)
}
Oltre al package sha1, crypto ha numerosi altri packages per altri algoritmi di crittografazione.
Codifica Base64
L'algoritmo di trascodifica Base64 permette di esprimere sequenze di byte con codifica a 8 bitper byte in una sequenza stampabile a 7 bit per byte. E' usatissimo in tanti servizi internet, per esempio per gli allegati di posta elettronica.
E' chiamato anche trascodifica MIME.
Per la gestione si usano due encoder in alternativa:
StdEncoding- encoder standard senza ulteriore trattamento delle stringhe Base64URLEncoding- che gestisce inoltre l'uso di caratteri speciali (tipo %nn) nelle stringhe URL
Ciascuno dei due encoder ha le funzioni:
EncodeToString- per la codifica da slice di byte 8 bit/char a stringa Base64DecodeString- per la decodifica da stringa Base64 a slice di byte 8 bit/char
(550base64-encoding.go):
package main
// Uno dei tanti package di codifica, con alias
import b64 "encoding/base64"
import "fmt"
func main() {
// Stringa di prova
data := "abc123!?$*&()'-=@~"
// L'argomento deve essere un array di byte
// Codifica con lo encoder standard
sEnc := b64.StdEncoding.EncodeToString([]byte(data))
fmt.Println(sEnc)
// Decodifica ritorna un array di byte e un errore
sDec, _ := b64.StdEncoding.DecodeString(sEnc)
// Stampa come stringa
fmt.Println(string(sDec))
fmt.Println()
// Encode compatibile con URL, ritorna stringa
uEnc := b64.URLEncoding.EncodeToString([]byte(data))
fmt.Println(uEnc)
// Decoder URL, ritorna stringa ed errore
uDec, _ := b64.URLEncoding.DecodeString(uEnc)
fmt.Println(string(uDec))
}
Molti altri metodi di codifica sono supportati da encode.
Interfaccia al Sistema Operativo
Un programma Go richiede naturalmente servizi dal sistema operativo sottostante e deve conformarsi ai suoi requisiti.
E' il caso di:
- lettura e scrittura di files
- gestione della linea di comando, con argomenti ed opzioni
- lancio di processi
- gestione dei segnali
Lettura File
Per la gestione dei file vi sono vari package:
io- funzioni primarie a basso livelloioutil- funzioni di utility a basso livellobufio- funzioni di I/O bufferizzatoos- funzioni ad alto livello
Ecco un esempio dell'uso di questi package per la lettura da file.
(560reading-files.go):
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"os"
)
// Funzione che controlla se c'è stato un errore
func check(e error) {
if e != nil {
panic(e)
}
}
func main() {
// Legge l'intero file in memoria in un colpo solo
dat, err := ioutil.ReadFile("/tmp/dat")
// Controlla l'errore
check(err)
// Lo stampa in un colpo solo
// assicurandosi che sia una stringa
fmt.Print(string(dat))
// Solo apertura del file
// non specifica se in lettura o scrittura
f, err := os.Open("/tmp/dat")
check(err)
// f è una struct che contiene l'indirizzo del file
fmt.Printf("%+v\n", *f)
// Un file può essere aperto più volte
g, err := os.Open("/tmp/dat")
defer g.Close()
// Lettura di 5 byte dal file
b1 := make([]byte, 5)
// Ritorna quanti byte sono stati letti e un errore
n1, err := f.Read(b1)
check(err)
fmt.Printf("%d bytes: %s\n", n1, string(b1))
// Salto al sesto byte a partire dalla posizione 0 (inizio)
o2, err := f.Seek(6, 0)
check(err)
// Lettura di 2 byte
b2 := make([]byte, 2)
n2, err := f.Read(b2)
check(err)
fmt.Printf("%d bytes @ %d: %s\n", n2, o2, string(b2))
// Ritorna al sesto byte dall'inizio
o3, err := f.Seek(6, 0)
check(err)
// Legge 'almeno' 2 byte
// Notare il package 'io'
b3 := make([]byte, 2)
n3, err := io.ReadAtLeast(f, b3, 2)
check(err)
fmt.Printf("%d bytes @ %d: %s\n", n3, o3, string(b3))
// Opera dall'inizio del file
// se il secondo argomento è zero
// Qui ritorna all'inizio del file
_, err = f.Seek(0, 0)
check(err)
// E' possibile leggere dalla fine del file
// se il secondo argomento è 2
// Naturalmente il primo argomento è negativo
_, err = f.Seek(-50, 2)
check(err)
bz := make([]byte, 50)
nz, err := f.Read(bz)
check(err)
fmt.Printf("%d bytes: %s\n", nz, string(bz))
// Per un seek dalla posizione corrente il
// secondo argomento è 1
// Uso di un reader bufferizzato
// Ricordarsi di risettare il file all'inizio
// Il tentativo di leggere oltre EOF da panic
_, err = f.Seek(0, 0)
check(err)
// Costruisce il buffer
r4 := bufio.NewReader(f)
// Acquisisce dal puntatore al 50 carattere
b4, err := r4.Peek(50)
check(err)
// Non sposta il puntatore, questo è dall'inizio
fmt.Printf("5 bytes: %s\n", string(b4))
// Al termine chiudere il file
// Di solito compiuto con un defer
f.Close()
}
Scrittura File
Un esempio che usa vari package per la scrittura su file.
(570writing-files.go):
package main
import (
"bufio"
"fmt"
"io/ioutil"
"os"
)
// Funzione di controllo errori
func check(e error) {
if e != nil {
panic(e)
}
}
func main() {
// Si può scrivere un array di byte
d1 := []byte("hello\ngo\n")
err := ioutil.WriteFile("/tmp/dat1", d1, 0777)
check(err)
// WriteFile compie l'apertura o creazione e la chiusura
// Se il file c'è viene troncato (se abbiamo i permessi)
// Se non c'è viene creato coi permessi dati
// Per scrivere una stringa trasformarla in byte
s1 := "One ring to rule them all\n"
err1 := ioutil.WriteFile("/tmp/dat0", []byte(s1), 0644)
check(err1)
// Creare un file
f, err := os.Create("/tmp/dat2")
check(err)
// Prevederne la chiusura alla fine
defer f.Close()
// Scrivere un'array di byte
d2 := []byte{115, 111, 109, 101, 10}
n2, err := f.Write(d2)
check(err)
fmt.Printf("wrote %d bytes\n", n2)
// Scrivere una stringa
n3, err := f.WriteString("writes\n")
fmt.Printf("wrote %d bytes\n", n3)
// Le scritture sono asincrone, per sincronizzare
f.Sync()
// Scrittura bufferizzata
// Crea un buffer in scrittura
w := bufio.NewWriter(f)
// Scrive una stringa al buffer
n4, err := w.WriteString("buffered\n")
fmt.Printf("wrote %d bytes\n", n4)
// Sincronizza il buffer su disco
w.Flush()
// Scrittura in append
a, erra := os.OpenFile("/tmp/dat0",
os.O_RDWR|os.O_APPEND|os.O_CREATE, 0660)
check(erra)
na, err := a.WriteString("One ring to find them\n")
fmt.Printf("wrote %d bytes\n", na)
a.Close()
}
Filtri di Linea
Un programma filtro in Unix legge da standard input, processa i dati letti e scrive il risultato a standard output.
Sono moltissime le utility Unix/Linux che si comportano in questo modo.
(580line-filters.go):
// Legge stdin, lo processa e scrive stdout
// Esempio che trasforma in maiuscole
package main
import ("bufio"; "fmt"; "os"; "strings")
func main() {
// Input bufferizzato fino a fine linea
scanner := bufio.NewScanner(os.Stdin)
for scanner.Scan() {
// Text ritorna il token corrente
// che qui è l'intere linea
ucl := strings.ToUpper(scanner.Text())
fmt.Println(ucl)
}
// Controllo errori. EOF non è un errore
if err := scanner.Err(); err != nil {
fmt.Fprintln(os.Stderr, "error:", err)
os.Exit(1)
}
}
L'oggetto che legge da standard input è uno scanner bufferizzato.
La funzione Scan legge finchè non trova lo End Of File (EOF - di solito Ctrl-D), bufferizzando ogni linea, delimitata da newline ('\n').
La funzione Text ritorna l'intera linea.
La funzione Err verifica se vi sono stati errori di scansione.
Argomenti di Comando
Per ogni processo Go è automaticamente usabile, senza dichiararlo come in linguaggio C, il vettore di lancio del processo, cioè il
comando e tutti gli argomenti.
Questo è disponibile come slice Args.
Il separatore di argomenti è una combinazione qualsiasi degli IFS di Unix (Inter Field Separator - spazi, tabs e newline).
Il primo argomento, Args[0] è il comando stesso.
(590command-line-arguments.go):
package main
import "os"
import "fmt"
func main() {
// os.Args è il vettore di lancio
// una slice di stringhe
// os.Args[0] è il percorso del comando
// os.Args[1:] sono gli altri argomenti
argsWithProg := os.Args
argsWithoutProg := os.Args[1:]
// Numero degli argomenti
argCount := len(os.Args[1:])
fmt.Println(argCount, " arguments")
// Non tentare di accedere se non c'è
arg := ""
if argCount > 2 {
arg = string(os.Args[3])
}
fmt.Println(argsWithProg)
fmt.Println(argsWithoutProg)
fmt.Println(arg)
}
Opzioni ai Comandi
E' possibile riconoscere opzioni del comando, con una certa variabilità di formati.
Le opzioni possono essere stringhe, numeri o booleani.
Per ciascuna di loro occore predefinire il nome, il valore di default e una descrizione, tramite varie funzioni del package flag a seconda del tipo di opzione.
La funzione Parse quindi scandisce e interpreta la linea di comando.
(600command-line-flags.go):
// I flag servono a definire opzioni
package main
import "flag"
import "fmt"
func main() {
// Opzione stringa con nome, valore default, descrizione
// Ritorna un puntatore
wordPtr := flag.String("word", "foo", "a string")
// Opzione intero
numbPtr := flag.Int("numb", 42, "an int")
// Opzione booleana
boolPtr := flag.Bool("fork", false, "a bool")
// Opzione che usa una variabile già esistente
var svar string
flag.StringVar(&svar, "svar", "bar", "a string var")
// Fa il parse della linea di comando
flag.Parse()
// Stampa delle opzioni acquisite o i loro default
// con accesso tramite puntatore
fmt.Println("word:", *wordPtr)
fmt.Println("numb:", *numbPtr)
fmt.Println("fork:", *boolPtr)
// Notare che la sottostante variabile
// svar riceve un valore dalle opzioni
fmt.Println("svar:", svar)
fmt.Println("tail:", flag.Args())
}
// Provare il comportamento con:
// eseguibile -word=sam
// eseguibile --word=sam
// eseguibile --word=sam --word=sam --numb=88 --fork=true john smith
// eseguibile --word=sam --word=sam --numb=88 john smith --fork
// eseguibile --word=sam --word=sam --numb=88 john smith --fork
// eseguibile --help
// eseguibile --fred=33
Un vantaggio è la possibilità di acquisire da opzione il valore di una variabile dichiarata all'interno del programma, con la funzione StringVar. Occorre passare come primo argomento l'indirizzo della variabile di appoggio.
Variabili d'Ambiente
Il package os contiene anche funzioni per il trattamento di variabili d'ambiente.
(610environment-variables.go):
package main
import "os"
import "strings"
import "fmt"
func main() {
// Settare e stampare variabili d'ambiente
os.Setenv("FOO", "1")
fmt.Println("FOO:", os.Getenv("FOO"))
fmt.Println("BAR:", os.Getenv("BAR"))
// Stampa di tutte le variabili d'ambiente
fmt.Println()
// Slice di stringhe nel formato KEY=value
for _, e := range os.Environ() {
// Split con separatore dato
pair := strings.Split(e, "=")
fmt.Println(pair[0] + "-->" + pair[1])
}
}
La funzione Setenv() pone una variabile nell'ambiente. La funzione Getenv() ottiene il valore di una variabile d'ambiente.
La funzione Environ() ritora una slice di stringhe contenente tutte le variabili d'ambiente,di cui ogni elemento ha il formato CHIAVE=valore.
La funzione stringa Split() genera un'altra slice con come elementi i token separati dal separatore indicato.
Nuovi Processi
Il package exec permette l'esecuzione di comandi di sistema operativo da dentro i programmi Go.
La funzione Command() registra il comando in un oggetto comando.
La funzione Output() lo esegue e ritornare lo standard output del comando ed un errore.
Prima dell'esecuzione del comando è possibile la ridirezione dello standard input e output da e in pipes.
Il comando viene poi lanciato con la funzione Start() dell'oggetto comando.
(620spawning-processes.go):
package main
import "fmt"
import "io/ioutil"
import "os/exec"
func main() {
// Esecuzione di comando senza argomenti
dateCmd := exec.Command("date")
// Output ed errore del comando
dateOut, err := dateCmd.Output()
if err != nil {
panic(err)
}
fmt.Println("> date")
fmt.Println(string(dateOut))
// Comando con argomento
grepCmd := exec.Command("grep", "hello")
// Input del comando da stdin
grepIn, _ := grepCmd.StdinPipe()
// Output a stdout
grepOut, _ := grepCmd.StdoutPipe()
// Lancio del comando
grepCmd.Start()
// Fornire l'input
grepIn.Write([]byte("hello grep\ngoodbye grep"))
// Chiudere l'input - importante
grepIn.Close()
// Lettura dell'output risultante
grepBytes, _ := ioutil.ReadAll(grepOut)
// Attesa della terminazione del processo - importante
grepCmd.Wait()
// Ognuno dei comandi sopra può ritornare un errore
// Controllo omesso in questo esempio
// Stampa del risultato
fmt.Println("> grep hello")
fmt.Println(string(grepBytes))
// Invocazione di shell e passaggio di argomenti
// alla shell - argomenti: un'unica stringa
lsCmd := exec.Command("bash", "-c", "ls -a -l -h")
lsOut, err := lsCmd.Output()
if err != nil {
panic(err)
}
fmt.Println("(through shell)> ls -a -l -h")
fmt.Println(string(lsOut))
// Invocazione diretta: ogni opzione o argomento
// è una stringa separata
lsCmd = exec.Command("ls", "-a", "-l", "-h")
lsOut, err = lsCmd.Output()
if err != nil {
panic(err)
}
fmt.Println("(standalone)> ls -a -l -h")
fmt.Println(string(lsOut))
}
Una pipe è composta da un oggetto di input ed un oggetto di output.
Quando l'input è da una pipe è importante chiuderlo esplicitamente con la funzione Close() dell'oggetto di input che invia un End Of File (EOF).
La funzione ReadAll() dell'oggetto di output legge l'output finale di una pipe.
Dato che una pipe è una serie di processi Linux indipendenti e sincronizzati, è importante attendere la terminazione di tutti questi processi con la funzione Wait() dell'oggetto comando.
Exec di Processi
I comandi eseguiti da un programma Go ereditano l'ambiente del processo Go in esecuzione.
La funzione LookPath() ricerca nel PATH un comando non qualificato.
Se lo trova lo registra in un oggetto, altrimenti torna un errore.
E' l'equivalente del comando Unix which.
(630execing-processes.go):
package main
import "syscall"
import "os"
import "os/exec"
func main() {
// Registrazione del comando con ricerca
// nel $PATH se necessario
binary, lookErr := exec.LookPath("ls")
if lookErr != nil {
panic(lookErr)
}
// Vettore di esecuzione
args := []string{"ls", "-a", "-l", "-h"}
// Ambiente
env := os.Environ()
// System call che esegue il comando
execErr := syscall.Exec(binary, args, env)
if execErr != nil {
panic(execErr)
}
}
Si può eseguire un comando anche con una System call a basso livello tramite il package syscall, con la funzione Exec().
Invoca la system call execve() del linguaggio C, e il suo comportamento è uguale.
Questa ha bisogno di tre argomenti:
- il comando
- la lista degli argomenti
- l'ambiente
Il comando è un oggetto.
La lista degli argomenti è una slice di stringhe, i token del vettore di lancio, ed include il comando stesso.
L'ambiente è una slice di stringhe, come visto in precedenza.
Segnali
Un segnale è una notifica semantica dal sistema operativo, o generata dal sistema
stesso o generata da un altro processo Linux, oppure anche inviata dall'utente tramite il terminale di controllo.
Per esempio Ctrl-C invia il segnale SIGINT (interruzione) al processo in foreground.
Vi sono approssimativamente 35 segnali diversi in Linux.
I segnali si possono gestire col package os/signal.
(640signals.go):
package main
import ("fmt"; "os"; "os/signal"; "syscall")
func main() {
// Channel che riceve le notifiche di segnali
sigs := make(chan os.Signal, 1)
// Channel che riceve notifica di uscita
done := make(chan bool, 1)
// Registrazione dei segnal accettati sul channel
signal.Notify(sigs, syscall.SIGINT, syscall.SIGTERM)
// Goroutine che si blocca in attesa di un segnale.
go func() {
sig := <-sigs
fmt.Println()
fmt.Println(sig)
// Indica al main che può uscire
done <- true
}()
// Main: attesa di segnale ed uscita
fmt.Println("awaiting signal")
<-done
fmt.Println("exiting")
}
I segnali vengono ricevuti su un channel apposito.
Tranne il segnale SIGKILL, tutti gli altri segnali si possono ignorare o gestire. Un segnale non esplicitamente ignorato o gestito ha un comportamento di default, che di solito è la terminazione del processo.
La funzione Notify indica quali segnali sono accettati e gestiti. La funzione Ignore indicherebbe quali segnali sono ignorati.
La ricezione di un segnale non ignorato e non gestito, causa in Go una terminazione immediata con stack trace e dump dello stato dei registri di CPU.
E' buona norma gestire sempre il segnale SIGTERM, che è una richiesta educata di terminazione e da l'opportunità al programma di chiudere ogni risorsa e salvare il suo stato se lo desidera.
Exit
La funzione Exit() termina immediatamente il programma corrente, senza eseguire funzioni differite e ritorna il suo argomento alla shell come stato di ritorno.
(650exit.go):
package main
import "fmt"
import "os"
func main() {
// Le funzioni defer non vengono eseguite
// con Exit. La seguente non viene stampata
defer fmt.Println("!")
// Uscita con stato 3
os.Exit(0)
}
// Go non ha uno stato di ritorno per la funzione return
// La funzione Exit è l'unica con stato di ritorno
// per la shell
Un programma che ha eseguito normalmente, senza Panic() o Exit() ritorna la stato 0 alla shell, successo.
Ogni altro stato di ritorno indica fallimento.
Lo stato di ritorno è limitato al range 0-255.
La Realtà
Il codice di ritorno alla shell è inviato correttamente solo se il programma è stato compilato con go build e lanciato da eseguibile, non se viene lanciato con go run. Quest'ultimo genera un programma di inviluppo per il nostro programma finale.
Proviamo l'esempio:
(651-return-code.go):
package main
import "os"
func main() {
os.Exit(0)
}
Lanciamolo con:
go run 65a-return-code.go
Non da alcun output, naturalmente, nè nessun messaggio, e il suo stato di ritorno, testato col comando shell echo $? è 0.
Ora proviamo il programma:
(652-return-code.go):
package main
import "os"
func main() {
os.Exit(100)
}
Lanciamolo con:
go run 65b-return-code.go
Produce il messaggio:
exit status 100
che è inviato a standard error.
Il suo stato di ritorno, testato con echo $? è 1.
Ma se entrambi i programmi vengono compilati col comando go build il comportamento è quello documentato nel manuale.
Il motivo è che go run programmanon lancia il programma direttamente ma fa partire un programma di gestione front end, che compila il programma in una directory temporanea e lo esegue.
Il programma vero passa lo stato di ritorno al gestore, che lo stampa come messaggio. Il programma vero non è figlio della shell, ma del gestore.
Il gestore, che è figlio della shell, passa un generico stato alla shell che è sempre 0 per successo e 1 per fallimento.
Programmazione in Pratica
Non è sufficiente conoscere la sintassi di un linguaggi di programmazione per scrivere programmi che funzionano.
Occorre anche acquisire l'arte pratica che va dalla progettazione di un applicativo, alla sua codifica, testing, build, debug, deploy, documentazione e manutenzione.
Questi sono tutti aspetti che in notevole misura dipendono dal linguaggio di programmazione, e Go ha i suoi dettagli specifici.
Lo si può chiamare l'ecosistema di programmazione Go.
In particolare in questo capitolo ci vogliamo preoccupare delle domande:
- Come deve essere strutturato un applicativo Go?
- Come usare le librerie del Go, nostre e di terze parti?
- Come si compie la generazione di un eseguibile e la sua installazione ed uso?
- Come integrare lo sviluppo in un ambiente di controllo versioni?
- Quali sono le Best Practices da adottare, e gli errori da evitare nella redazione di un applicativo Go?
Struttura di un Applicativo
Go ha il concetto di workspace che è la directory di testa dell'albero di sviluppo applicativi.
Il workspace ha tre directory principali:
src- sorgenti di tutti i progetti Gobin- esguibili compilati dai sorgenti: sono linkati staticamentepkg- packages compilati e installati: sono librerie statiche linkate agli eseguibili
bin contiene gli eseguibili che sono stati installati.
Il fatto che gli eseguibili siano statici e non abbiano bisogno di librerie dinamiche o di un ambiente runtime li rende estremamente portatili, anche se di dimensione notevole.
src, quando è organizzato bene, è composto di alberi di sottodirectories, a profonditàvariabile ma non eccessiva, con la Struttura informale repository/autore/artefatto.
E' la stessa struttura che viene usata, per esempio, da GitHub.
- repository è lo URL (solo sito web, senza protocollo, porta, ecc.) che indica il repository remote di appoggio del progetto
- autore è l'identificativo univoco del singolo o del gruppo responsabile per la creazione di uno o più progetti
- artefatto è la directory contenente i sorgenti del programma col main o del package che è il progetto singolo di un autore o gruppo
pkg contiene i package dopo la loro installazione, in sottodirectories che hanno la stessa struttura dei corrispondenti sorgenti, repository/autore/artefatto.
Quando un programma importa un package deve usare
import repository/autore/artefatto
e riferirsi internamente alle funzioni o simboli esportati dal package con artefatto.Funzione() o artefatto.Simbolo.
Variabili d'ambiente
Per sviluppare in Go occorre settare alcune variabili d'ambiente:
GOPATHdeve puntare al workspaceGOBINdeve puntare alla sottodirectorybindel workspaceGOROOTdeve puntare alla directory di sistema dove è stato installato Go
E' anche opportuno modificare la variabile d'ambiente PATH di sistema:
export PATH=$GOBIN:$PATH
Si possono avere più workspace, modificando di volta in volta le variabili d'ambiente sopra. Ma durante la compilazione il riferimanto a packages avviene solo nel GOPATH corrente. (Una volta compilati gli eseguibili possono essere messi ovunque, dato che sono statici)
Per iniziare
Supponiamo di aver installato Go in /opt/go e di volere un workspace sotto la directory di login, sottodirectory go:
cd
mkdir -p go/src
mkdir -p go/bin
La directory go/pkg verrà automaticamente creata la prima volta che installiamo un package.
Ora modifichiamo il .profile aggiungendo alla fine:
export GOROOT=/opt/go
export GOPATH=$HOME/go
export GOBIN=$GOPATH/bin
export PATH=$GOBIN:$PATH
Per essere sicuri che queste variabili d'ambiente siano riconosciute da tutti i programmi e utilities di sistema, è necessario un relogin.
Files sorgente multipli
Il package main non deve essere necessariamente in un unico file
L’unico requisito è che la func main() sia nel package main
Tutti i file che dichiarano package main devono essere compilati e costruiti in un unico comando go
Proviamo un esempio in una directory dedicata:
mkdir 72multiple
cd 72multiple
In questa directory creiamo due file
main.go– con la funzione mainutils.go– con funzioni di utilità
Entrambi i file appartengono al package main
(main.go):
package main
func main() {
// Se usata spesso p è meglio di fmt.Println
p("Version: ", version)
}
(utils.go):
package main
import "fmt"
// Definizione di p
func p(a ...interface{}) {
fmt.Println(a)
}
var version = "unknown"
Per il run:
go run main.go util.go
Per il build:
go build main.go util.go
L’eseguibile è main, come il file che ha func main()
Se I file che dichiarano package main sono molti si può usare un po’ di magia shell:
go build `grep -H "package main" *| cut -d: -f1`
(attenzione agli apici rovesciati)
Per più flessibilità si può scrivere un Makefile.
(Makefile):
# Basta cambiare le tre linee seguenti
PROGS = main.go utils.go
MAIN = main
EXEC = printver
# ----- in qualsiasi progetto
help:
@echo "usage: make target"
@echo "\trun - run immediately"
@echo "\tbuild - compile and link the executable"
@echo "\tclobber - clean up the project"
run:
go run $(PROGS)
build:
go build $(PROGS)
mv $(MAIN) $(EXEC)
clobber:
rm -f $(EXEC)
Non è veramente parte della filosofia Go scrivere un Makefile. Può tornare però utile quando si mescola la tecnologia Go con altre e diverse utilities di Linux.
Attenzione
Col ‘copia-e-incolla’ i TAB del Makefile diventano spazi.
Il Makefile richiede che le linee siano indentate da un TAB
Usare il comando vi di sostituzione globale
:g/^ */s//^I/
Qui ^ indica l’inizio riga, poi vi sono due spazi e un *
Almeno uno spazio seguito da un numero qualsiasi di spazi (anche zero)
Il ^I rappresenta il TAB e si ottiene battendo Ctrl-V seguito dal TAB.
Ctrl-V toglie il significato al carattere che segue e lo rappresenta letteralmente
Interfaccia con git
Il nostro programma sopra stampa
[Version: unknown]
che è proprio quello che dice utils.go.
Di solito però i nostri progetti, che si evolvono nel tempo, sono sottoposti al controllo versione con l'utility git.
Facciamolo:
git init
git add .
git commit -m "Prima versione"
Ora aggiungiamo un tag di versione:
git tag -a 0.1 -m "Versione 0.1"
La compilazione del programma avviene ora con un flag passato al linker:
go build -i -v -ldflags="-X main.version=\
$(git describe --always --long --dirty)" \
main.go utils.go
Il \ rappresenta che in realtà il comando sopra deve occupare un'unica linea logica ma qui è spezzato su più linee fisiche per
convenienza visiva. (Si può compiere il copia e incolla anche con i \ e la shell riconoscerà lo spezzamento fisico).
Se ora lanciamo il programma verrà qualcosa tipo:
[Version: 0.1-0-g1cf7ed9]
Nel comando sopra:
-ldflagspassa i flag al linker-Xdice di compiere una sostituzionemain.versionè il simbolo version del package main$( ... )è un costrutto shell che esegue il comando racchiuso tra tonde e interpola localmente l'output del comandogit describe --always --long --dirtyè il comando git per recuperare l'ultimo tag--alwaysanche se il tag è light e non annotato--longformato lungo--dirtyanche se non vi è stato ancora un commit dopo l'attribuzione del tag
Si può modificare il Makefile per inglobare questo comando:
(Makefile):
# Basta cambiare le tre linee seguenti
PROGS = main.go utils.go
MAIN = main
EXEC = printver
# ----- in qualsiasi progetto
# $$ diventa $ quando a sua volta interpolato
LDFLAGS = "-X main.version=$$(git describe \
--always --long --dirty)"
help:
@echo "usage: make target"
@echo "\trun - run immediately"
@echo "\tbuild - compile and link the executable"
@echo "\tclobber - clean up the project"
run:
go run $(PROGS)
build:
go build -i -v -ldflags=$(LDFLAGS) $(PROGS)
mv $(MAIN) $(EXEC)
clobber:
rm -f $(EXEC)
Gestione Package
Creazione di un Package
Decisioni:
- il repository di appoggio sarà
masha.kan - L'autore sarà
mich - Il package (artefatto) sarà
customer
Preparazione delle directory:
cd $GOPATH/src
mkdir -p masha.kan/mich/customer
Redazione del programma per il package:
cd masha.kan/mich/customer
vi customer.go
(customer.go):
package customer
import "fmt"
// Tutte le struct e i loro metodi sono in questo package
// I nomi con iniziale maiuscola sono esportati
type Address struct {
Street, City, State, Zip string
IsShippingAddress bool
}
type Customer struct {
FirstName, LastName, Email, Phone string
Addresses []Address
}
func (c Customer) ToString() string {
return fmt.Sprintf("Customer: %s %s, Email:%s",
c.FirstName, c.LastName, c.Email)
}
func (c Customer) ShippingAddress() string {
for _, v := range c.Addresses {
if v.IsShippingAddress == true {
return fmt.Sprintf("%s, %s, %s, Zip -%s",
v.Street, v.City, v.State, v.Zip)
}
}
return ""
}
func Getcustomer() Customer {
// In realtà sarebbe ottenuto da un DB
c := Customer{
FirstName: "Alex",
LastName: "John",
Email: "alex@email.com",
Phone: "732-757-2923",
Addresses: []Address{
Address{
Street: "1 Mission Street",
City: "San Francisco",
State: "CA",
Zip: "94105",
IsShippingAddress: true,
},
Address{
Street: "49 Stevenson Street",
City: "San Francisco",
State: "CA",
Zip: "94105",
},
},
}
return c
}
L'albero al di sotto del workspace è al momento:
.
├── bin
└── src
└── masha.kan
└── mich
└── customer
└── customer.go
Andare nella directory customer.
Installare il package:
go install
L'albero al di sotto del workspace è diventato:
.
├── bin
├── pkg
│ └── linux_amd64
│ └── masha.kan
│ └── mich
│ └── customer.a
└── src
└── masha.kan
└── mich
└── customer
└── customer.go
Notare che pkg è stato creato perchè ancora non esisteva, e che al di sotto ha una directory che specifica l'architettura.
Essendo i package delle librerie statiche, composte di moduli oggetto, sono dipendenti dall'architettura per cui sono state prodotte.
E' possibile in Go la cross-compilazione, ovvero la produzione di oggetti ed eseguibili destinati ad architetture diverse da quella della piattaforma di sviluppo.
Creazione di un programma che usa il package
Decisioni:
- Sarà nella directory sorgente
masha.kan/mich/custe questo saraà anche automaticamente il nome dell'eseguibile - Il file sorgente si chiamerà
listcust.go
Notare che il fatto che un eseguibile o un package si chiami come la directory che lo contiene, ci permette di suddividerlo
in molti file con nomi diversi, e il build saprà come fare.
Naturalmente tutti i file devono appartenere allo stesso package, qui main, e nel nostro caso ci deve essere una sola func main().
Quindi creare la directory, andarvi dentro ed editare il programma:
cd $GOPATH
mkdir -p src/masha.kan/mich/cust
cd src/masha.kan/mich/cust
vi listcust.go
(listcust.go):
package main
import "fmt"
// cus è un alias a customer
import cus "masha.kan/mich/customer"
func main() {
c := cus.Getcustomer()
fmt.Println(c.ToString())
fmt.Println(c.ShippingAddress())
}
Provarlo con:
go run listcust.go
Compilarlo a eseguibile locale:
go build
Provarlo da eseguibile:
./cust
Per installarlo:
go install
L'albero sotto il workspace è diventato:
.
├── bin
│ └── cust
├── pkg
│ └── linux_amd64
│ └── masha.kan
│ └── mich
│ └── customer.a
└── src
└── masha.kan
└── mich
├── cust
│ └── listcust.go
└── customer
└── customer.go
Ora possiamo eseguirlo da ovunque nel filestore semplicemente col comando cust non qualificato.
Tools

Controllo degli errori
Molte funzioni ritornano un valore che non è usato o un errore che spesso non è controllato.
Il compilatore rifiuta di compilare un programma in cui una variabile è dichiarata ma non usata, ma non ha alcun problema con la variabile finale di errore.
Per non andare incontro a errori futuri, il programmatore dovrebbe essere conscio di ogni funzione che ritorna un errore e, se sceglie di ignorarlo, dovrebbe farlo esplicitamente.
L'utility errcheck controlla che i valori ritornati siano gestiti o ignorati esplicitamente e opzionalmente tutti gli errori siano gestiti e non ignorati.
Installare con:
go get github.com/kisielk/errcheck
(831-errcheck.go):
package main
import "os"
func main() {
f, _ := os.Open("foo")
f.Write([]byte("Hello, world."))
f.Close()
}
Dovrebbe scrivere "Hello, world." dentro il file foo. Compila, esegue, non scrive il file. Perchè? Passiamo alla fase di debugging.
Usiamo errcheck 83a-errcheck.go.
Tutte e tre le funzioni usate ritornano errori, ma lo menzioniamo esplicitamente e ignoriamo con la prima, non lo trattiamo con le altre due.
Notare inoltre che con l'aggiunta di un'opzione errcheck -blank 83a-errcheck.Gosegnala anche la prima funzione, cioè la menzione esplicita, ma il mancato trattamento, dell'errore.
Possiamo riscrivere il codice in modo che errcheck non si lamenti:
(832-errcheck.go):
package main
import "os"
func main() {
f, _ := os.Open("foo")
_, _ = f.Write([]byte("Hello, world.\n"))
_ = f.Close()
}
Notare che errcheck -blank si lamenta lo stesso.
Lo scopo del Controllo Qualità non è di assicurarsi che il programma superi i controlli di qualità compiuti dai tools, ma di usare i tools per aumentare la qualità del programma.
Debugging ad alto livello
Riscriviamo il codice in modo che ogni errore venga usato:
(833-errcheck.go):
package main
import "os"
func main() {
f, err := os.Open("foo")
if err != nil {
panic("Cannot open file")
}
_, err = f.Write([]byte("Hello, world.\n"))
if err != nil {
panic("Cannot write to file")
}
err = f.Close()
if err != nil {
panic("Cannot close file")
}
}
Ora passa entrambe le varianti di errchecke quando lo lanciamo scopriamo dov'è che fallisce: non riesce ad aprire il file.
Qui sono i controlli errori che forzano i panic, se non lo facciamo, al programma va benissimo lo stesso: non compie le azioni richieste e prosegue.
Un panic significa che non si deve proseguire, perchè non si perseguirebbe lo scopo primario del programma.
OK, ma perchè non apre il file? E' giunto il momento di un sano RTFM sulla documentazione.
Soluzione
La funzione Open() apre un file che già esiste, e nel nostro caso tale file non c'è.
Se Open() fallisce per tale motivo, allora il file bisogna crearlo con Create():
(834-errcheck.go):
package main
import "fmt"
import "os"
func main() {
f, err := os.Open("foo")
if err != nil {
f, err = os.Create("foo")
if err != nil {
panic("Cannot create file\n")
}
}
fmt.Println("Open succeeded")
_, err = f.Write([]byte("Hello, world.\n"))
if err != nil {
panic("Cannot write to file")
}
fmt.Println("Write succeeded")
err = f.Close()
if err != nil {
panic("Cannot close file")
}
fmt.Println("Close succeeded")
}
Funziona. Passa errcheck in entrambe le versioni. Passa anche il vetting e il linting. Siamo contenti? No.
Provare, dopo la prima volta che si è eseguito, a dare il comando chmod -w foo e rieseguire il programma.
Evidentemente va in panic in fase di scrittura, e notiamo che non sa dirci perchè a questo livello, poteva essere l'assenza di permessi come in questo caso, ma poteva essere che il disco era pieno, o che mancava temporaneamente la rete in un accesso a disco remoto.
Quello che è importante è che non chiude il file.
Ora in questo caso il programma termina subito e disalloca tutte le risorse. Ma se vi fosse stato un loop, o eravamo in presenza di più goroutines, oppure si trattava di una connessione ad un database o a un socket?
Miglioramento della soluzione
Tutte le risorse devono essere garantite chiuse in caso di panic. Occorre usare defer.
(835-errcheck.go):
package main
import "fmt"
import "os"
func main() {
f, err := os.Open("foo")
if err != nil {
f, err = os.Create("foo")
if err != nil {
panic("Cannot create file\n")
}
}
fmt.Println("Open succeeded")
defer func() {
err = f.Close()
if err != nil {
panic("Cannot close file")
}
fmt.Println("Close succeeded")
}()
_, err = f.Write([]byte("Hello, world.\n"))
if err != nil {
panic("Cannot write to file")
}
fmt.Println("Write succeeded")
}
Da questo programma si nota che un fallimento della write, nel nostro caso per mancanza di permessi, causa comunque una chiusura del file.
Panic e Defer innestati
Alla domanda se si possano innestare dei defer e dei panic e se si possano cancellare i panic, risponde il seguente programma:
(836-multiple-panic):
package main
import "fmt"
func spoiler() {
if e := recover(); e != nil {
// e è il valore passato a panic
fmt.Println("recovered from ", e)
}
}
func later() {
defer spoiler()
panic("later panic")
}
func main() {
fmt.Println("main about to panic")
defer func() {
panic("first defer panic")
}()
defer func() {
defer later()
panic("second defer panic")
}()
panic("main panic")
fmt.Println("DON'T PANIC")
}
Dalla sua esecuzione si nota che:
- una funzione defer può dichiarare un'altr funzione defer; all'esecuzione vengono sempre invocate in ordine inverso di registrazione
- una funzione defer può invocare un
panicanche se vi è già un altro panic attivo - vi possono essere molti panic attivi, ciascuno diverso
- il recover di un panic non cancella gli altri
- basta un solo panic ancora attivo e il programma esce
- viene generato una stack trace per ciascun panic
Vetting
Il verbo inglese vet implica un controllo esaustivo e approfondito di qualcosa.
Go ha lo strumento go tool vet per tale tipo di controllo sul nostro codice.
Il seguenteè un programma che funziona, ma contiene molti errori che potrebbero rivelarsi fatali in condizioni future.
(837unvetted.go):
package main
import (
"crypto/tls"
"fmt"
"sync"
"sync/atomic"
"unsafe"
)
// +build this,is,too,late
type T struct {
A int `not a canonical tag`
}
// These fields should be keyed
_ = tls.Certificate{nil, nil, nil, nil, nil}
// We meant to check foo() != nil
if foo != nil {
}
x := uintptr(0)
_ = unsafe.Pointer(x) // Misuse of unsafe.Pointer
for _, x := range []int{1, 2, 3} {
go func() {
fmt.Println(x) // Closing over xwrong
}()
}
var b int32
b = atomic.AddInt32(&b, 1) // We shouldn't assign to b
var c bool
if c == false && c == true { // Always false
}
if c || c { // Redundant
}
fmt.Println("Got here")
return
fmt.Println("unreachable") // Unreachable code
}
Per verificarlo, lanciare
go tool vet 837unvetted.go
e notare la quantità di rapporti prodotti.
Linting
Lint sono in inglese le palle di polvere che si formano sul pavimento o sui vestiti. Linting è il toglierle.
Il programma lint è sempre esistito per gli sviluppatori in linguaggio C fino dagli anni '80. La versione moderna per Linux è splint.
In Go è disponibile golint come package contribuito.
Per installarlo:
go get github.com/golang/lint/golint
Per testarlo usiamo un programma:
(838unlinted.go):
package lint
import (
"errors"
. "fmt"
)
var SomeError = errors.New("Capitalised error message")
type unexported int
type Exported int
func (this unexported) Foo() {}
func (oneName Exported) Foo() {
}
func (anotherName Exported) Bar() {
Println("Hi")
}
Verifichiamolo con:
golint 838unlinted.go
Conclusione
Il presente documento ha coperto i fondamenti della sintassi del linguaggio Go per programmi standalone.
Rimangono da considerare altre notevoli possibilità del Go, per esempio:
- la programmazione di rete
- l'interfacciamento a database
- l'uso di Go come server di applicativo Web
- l'interfacciamento con altri linguaggi
- l'aggiunta di moduli
Si lasciano questi argomenti a manuali futuri.