Introduzione
Kubernetes è più che oggetti di base e semplici configurazione.
Vi sono molti altri oggetti e ambienti utili nello sviluppo di applicativi più complessi, e utilities per la pacchettizzazione, distribuzione e gestione dei nostri applicativi.
Vengono qui esaminati:
- un numero di oggetti Kubernetes più complessi
- aspetti più avanzati di oggetti già noti
- l'utility di pacchettizzazione Helm
Si parte dal cluster Kind con configurazione standard già usato in precedenza.
Licenza
La presente documentazione è distribuita secondo i termini della GNU Free Documentation License Versione 1.3, 3 novembre 200t8.
Ne è garantita assoluta libertà di copia, ridistribuzione e modifica, sia a scopi commerciali che non.
L'autore detiene il credito per il lavoro originale ma nè credito nè responsabilità per le modifiche.
Qualsiasi lavoro derivato deve essere conforme a questa stessa licenza.
Il testo pieno della licenza è a:
https://www.gnu.org/licenses/fdl.txt
Tecnologia Kubernetes
Preparazione cluster KinD
Questi sono i passi per la preparazione di un cluster Kubernetes basato su Kind.
Partiamo da un sistema con il seguente software installato:
- Docker - meglio se ultima versione
- Docker Compose
- come script standalone in Python
- (meglio) come componente di Docker stesso
I comandi qui illustrati useranno l'utility standalone.
Per usare invece il Docker Compose integrato in Docker, sostituire docker compose al posto di docker-compose.
NOTA
I files di configurazione del cluster Kind standard sono raccolti nel file tar cluster-kind-std.tar Scompattare tale file nella directory di login. Procedere quindi alla sezione Lancio del Cluster Kubernetes.
kubectl
Scaricare e installare kubectl:
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s \
https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
sudo chown root:root /usr/local/bin/kubectl
kind
Installiamo ora kind:
curl -Lo ./kind https://github.com/kubernetes-sigs/kind/releases/download/v0.14.0/kind-linux-amd64 && \
chmod +x ./kind && \
sudo mv ./kind /usr/local/bin/kind
Script di Attivazione del Cluster
Tutti gli esercizi utilizzeranno la versione del cluster costruito con Kind.
Editare il file di configurazione:
cd
vim std.sh
#!/bin/sh
set -o errexit
# crea il contenitore del registry se non esiste
reg_name='kind-registry'
reg_port='5000'
if [ "$(docker inspect -f '{{.State.Running}}' "${reg_name}" 2>/dev/null || true)" != 'true' ]; then
docker run \
-d --restart=always -p "127.0.0.1:${reg_port}:5000" --name "${reg_name}" \
-v $HOME/.docker/registry:/var/lib/registry registry:2
fi
# crea un cluster con il registry locale abilitato in containerd
cat <<EOF | kind create cluster --image kindest/node:v1.24.0 --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
containerdConfigPatches:
- |-
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."localhost:${reg_port}"]
endpoint = ["http://${reg_name}:5000"]
nodes:
- role: control-plane
extraMounts:
- hostPath: /data
containerPath: /data
- role: worker
extraMounts:
- hostPath: /data
containerPath: /data
- role: worker
extraMounts:
- hostPath: /data
containerPath: /data
EOF
# connette il registry alla rete del cluster se non connesso
if [ "$(docker inspect -f='{{json .NetworkSettings.Networks.kind}}' "${reg_name}")" = 'null' ]; then
docker network connect "kind" "${reg_name}"
fi
# Documenta il local registry
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: local-registry-hosting
namespace: kube-public
data:
localRegistryHosting.v1: |
host: "localhost:${reg_port}"
help: "https://kind.sigs.k8s.io/docs/user/local-registry/"
EOF
Renderla eseguibile:
chmod +x ~/std.sh
Shell Scripts per la Gestione del Cluster
setup
sudo vim ~/setup.sh
#! /bin/sh
echo "Creating cluster ..."
echo
echo "~/std.sh"
~/std.sh
echo "Cluster info follows ..."
kubectl cluster-info --context kind-kind
echo
echo "---> Loading and configuring the Metallb load balancer ..."
echo
echo "-- Namespace"
echo "kubectl apply -f scripts/metallb-ns.yml"
kubectl apply -f scripts/metallb-ns.yml
echo
echo "-- Deployment and service"
echo "kubectl apply -f scripts/metallb-svc.yml"
kubectl apply -f scripts/metallb-svc.yml
echo
echo "-- Configmap"
echo "kubectl apply -f scripts/metallb-configmap.yml"
kubectl apply -f scripts/metallb-configmap.yml
echo
echo "Wait up to 120s for Metallb controller deployment to be ready ..."
kubectl wait deployment -n metallb-system controller --for condition=Available=True --timeout=120s
echo
echo " CLUSTER NOW READY"
echo " ===> All resources in namespace 'default'"
kubectl get all
echo
echo " ===> All resources in namespace 'metallb-system'"
kubectl get all -n metallb-system
Renderla eseguibile:
sudo chmod +x ~/setup.sh
teardown
sudo vim ~/teardown.sh
echo "About to delete cluster 'kind'"
echo "Press Control-C within 10 seconds to interrupt"
sleep 10
kind delete cluster
echo "Cluster deleted"
Renderla eseguibile:
sudo chmod +x ~/teardown.sh
Manifests di Gestione del Cluster
Metallb Load Balancer
Scarico dei manifest necessari dalla rete e trasferimento al contenitore kub:
mkdir -p ~/scripts
wget https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/namespace.yaml
sudo mv namespace.yaml ~/scripts/metallb-ns.yml
wget https://raw.githubusercontent.com/metallb/metallb/v0.12.1/manifests/metallb.yaml
sudo mv metallb.yaml ~/scripts/metallb-svc.yml
Configmap per Metallb
sudo vim ~/scripts/metallb-configmap.yml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 172.18.255.200-172.18.255.250
Lancio del Cluster Kubernetes
Scaricare l'immagine del cluster:
docker pull kindest/node:v1.24.0
Partenza del cluster:
~/setup.sh
Impiegherà un po' di tempo aggiuntivo, poichè scaricherà la sua immagine di default del cluster.
Il File Kubeconfig
Kubeconfig è un file Yaml con tutti i dettagli del cluster Kubernetes, i certificati, i token segreti.
Può essere autogenerato dall'utility di costruzione cluster o ricevuto dal cloud provider.
La sua locazione tipica ès $HOME/.kube/config.
Si può usare un altro file, ma occorre indicarlo con la variabile d'ambiente KUBECONFIG.
Per esempio:
export KUBECONFIG=$HOME/.kube/dev_cluster_config
oppure:
kubectl get nodes --kubeconfig=$HOME/.kube/dev_cluster_config
KUBECONFIG=$HOME/.kube/dev_cluster_config kubectl get nodes
Per esaminare il nostro, generato da Kind:
less ~/.kube/config
Una struttura più generica può essere:
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: <ca-data-here>
server: https://your-k8s-cluster.com
name: <cluster-name>
contexts:
- context:
cluster: <cluster-name>
user: <cluster-name-user>
name: <cluster-name>
current-context: <cluster-name>
kind: Config
preferences: {}
users:
- name: <cluster-name-user>
user:
token: <secret-token-here>
Qualora vi fossero più files di configurazione di cluster, si può compiere il merge coi comandi, per esempio:
KUBECONFIG=config:dev_config:test_config kubectl config view --merge --flatten > config.new
mv $HOME/.kube/config $HOME/.kube/config.old
mv $HOME/.kube/config.new $HOME/.kube/config
Vi sono tre configurazioni principali:
- clusters - con il nome, la URL del server e il certificato
- contexts - con il nome, il cluster a cui si riferisce e l'utente con cui accede
- users - con il nome e le credenziali d'accesso, spesso un Client Certificate
Sono degli arrays, e possono avere più elementi.
Contesto di kubectl
kubectl invia le sue richieste al Server API di un determinato cluster, il contesto.
Listare i contesti disponibili:
kubectl config get-contexts
Cambiare contesto:
kubectl config use-context <context-name>
Si può anche cancellare un contesto, ma non è consigliabile, meglio usare l'utility specifica per la gestione del cluster, p.es. kind.
kubectl config delete-context <context-name>
Aspetti Avanzati I
Un particolare cluster Kubernetes ha un numero di oggetti, o risorse, disponibili.
Per listarli usare il comando:
kubectl api-resources
Daemonset
Un DaemonSet si assicura che ogni nodo del cluster abbia un pod dell'immagine specificata.
Si può restringere il numero di nodi coinvolti con le direttive nodeSelector, nodeAffinity, Taints, e Tolerations.
Usi di DaemonSet:
- Raccolta di Log - p.es. fluentd , logstash, fluentbit
- Monitoraggio di Cluster - p.es. Prometheus
- Benchmark - p.es. kube-bench
- Sicurezza - sistemi di detezione intrusioni o scansori di vulnerabilità
- Storaggio - p.es. un plugin di storaggio su ogni nodo
- Gestione di Rete - p.es. il plugin Calico per CNI
Esempio di DaemonSet
vim ~/scripts/fluentd.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd
template:
metadata:
labels:
name: fluentd
spec:
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /data/varlog
E' opportuno che ogni DaemonSet sia specificato entro il suo namespace esclusivo.
Creare il namespace ed applicare il manifest:
kubectl create ns logging
kubectl apply -f scripts/fluentd.yml
Verifica con:
kubectl get daemonset -n logging
kubectl get pods -n logging -o wide
kubectl describe daemonset -n logging
Editazione Istantanea
Cambiamento istantaneo dei parametri di configurazione con:
kubectl edit daemonset fluentd -n logging
L'editor invocato è quello di sistema o quello indicato dalla variabile d'ambiente EDITOR.
Si può editare soltanto la sezione spec, non ststus.
In caso di errore l'editazione viene rilanciata.
Dopo il salvataggio di un'editazione corretta, avviene un rolling update.
Taints
Un Taint si applica ai nodi.
Il Taint ha la sintassi:
kubectl taint nodes <nodo> <chiave>=<valore>:<effetto>
L'effetto si applica sul nodo indicato a tutti i pod degli oggetti che hanno la chiave e il valore indicato.
L'effetto può essere:
- NoSchedule
- PreferNoSchedule
- NoExecute
Esempio:
kubectl taint node kind-worker2 app=fluentd-logging:NoExecute
Lista di tutti i taints associati ai nodi:
kubectl get node -o custom-columns=NAME:.metadata.name,TAINT:.spec.taints[*]
Rimuovere un taint:
kubectl taint node kind-worker2 app-
Notare alla fine del comando il nome dell'etichetta seguito dal segno meno.
Tolerations
Modificare il file di specifiche del DaemonSet:
vim ~/scripts/fluentd.yml
...
tolerations:
- key: app
value: fluentd-logging
operator: Equal
effect: NoExecute
containers:
...
E riapplicare:
kubectl apply -f ~/scripts/fluentd.yml
Questo genera una eccezione al Taint.
Rimuovere il DaemonSet dell'esercizio:
kubectl delete -f ~/scripts/fluentd.yml
nodeSelector
Si può usare nodeSelector per avere i pod solo su alcuni nodi specifici. Il controller DaemonSet creai i pod sui nodi che hanno la chiave e il valore del selector.
Per esempio:
kubectl label node kind-worker2 type=platform-tools
E modificare le specifiche inserendo:
...
spec:
nodeSelector:
type: platform-tools
containers:
...
Ricreare il Daemonset e verificare:
kubectl apply -f ~/scripts/fluentd.yml
kubectl get pods -n logging -o wide
Per visualizzare i labels di un nodo:
kubectl get node kind-worker2 -o custom-columns=LABELS:.metadata.labels
Per rimuovere un label di nome type:
kubectl label node kind-worker2 type-
Rimuovere il DaemonSet dell'esercizio:
kubectl delete -f ~/scripts/fluentd.yml
nodeAffinity
Il controller DaemonSet crea i pod sui nodi che hanno il corrispondente nodeAffinity.
Vi sono due tipi di nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution- il pod non è schedulato se non si applica la regolapreferredDuringSchedulingIgnoredDuringExecution- lo scheduler prova a trovare un nodo conforme con la regola. Se non vi sono nodi che corrispondono, il pod viene schedulato ugualmente
Nel seguente DaemonSet vengono usate entrambe le regole di affinity:
- required che i nodi abbiano una certa etichetta
- preferred i nodi che abbiano l'etichetta di tipo
t2.large
Modificare il file di specifiche con il seguente.
vim ~/scripts/fluentd.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: logging
labels:
app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd
template:
metadata:
labels:
name: fluentd
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: type
operator: In
values:
- platform-tools
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: instance-type
operator: In
values:
- t2.large
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /data/varlog
Ricreare il Daemonset e verificare:
kubectl apply -f ~/scripts/fluentd.yml
kubectl get pods -n logging -o wide
E' meglio usare preferredDuringSchedulingIgnoredDuringExecution invece di requiredDuringSchedulingIgnoredDuringExecution poichè è impossibile lanciare nuovi pod se il numero di nodi richiesto è maggiore del numero di nodi disponibile.
Priorità dei Pod
Determina l'importanza relativa di un pod.
E' utile settare una più alta PriorityClass ad un DaemonSet se questo ha componenti critici, per evitare che i suoi pod vengano sfavoriti da altri pod in caso di competizione di risorse.
PriorityClass definisce la priorità del pod. Valore limite 1 milione. Numeri più alti con priorità più alta.
Creazione di un oggetto priority class:
vim ~/scripts/prioclass.yml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 100000
globalDefault: false
description: "daemonset priority class"
kubectl apply -f ~/scripts/prioclass.yml
kubectl get priorityClass
Aggiungere al nostro DaemonSet modificando il file di specifiche:
...
spec:
priorityClassName: high-priority
containers:
...
terminationGracePeriodSeconds: 30
volumes:
...
Ricreare il Daemonset e verificare:
kubectl apply -f ~/scripts/fluentd.yml
kubectl get pods -n logging -o wide
StatefulSet
Applicativi stateful gestiscono dati e hanno bisogno di tracciarli continuamente, per esempio MySQL, Oracle e PostgreSQL.
Uno StatefulSet è il controller appropriato per un applicativo stateful.
Ad ogni pod gestito viene assegnato un numero identificativo ordinale anzichè casuale e i pod vengono creati in ordine e cancellati in ordine inverso. Un nuovo pod è creato clonando il pod precedente solo quando è nello stato Running.
Le richieste di lettura da un volume associato vengono inviate a tutti i pod dello StatefulSet. Le richieste di scrittura sul volume associato vengono inviate solo al primo pod, e i dati modificati sono sincronizzati agli altri pod.
Cancellare un pod di uno StatefulSet non rimuove i volumi associati con l'applicativo.
Per l'esercizio che segue occorrono due Persistent Volumes, che i pod dello Stateful Set useranno. Normalmente un Provisioner creerebbe volumi dinamici all'occorrenza.
Il manifest che segue combina la definizione dei due persistent volumes con quella dello StatefulSet:
vim ~/scripts/stateful.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: www-volume-1
spec:
storageClassName: standard
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /data/www/
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: www-volume-2
spec:
storageClassName: standard
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /data/www/
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: registry.k8s.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
Aprire due finestre di terminale.
Nella prima digitare:
kubectl get pods --watch -l app=nginx
Nella seconda digitare:
kubectl apply -f ~/scripts/stateful.yml
Mentre nella seconda viene generato l'applicativo, il rapporto nella prima finestra è:
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 1s
web-0 0/1 ContainerCreating 0 1s
web-0 1/1 Running 0 5s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 2s
web-1 0/1 ContainerCreating 0 3s
web-1 1/1 Running 0 9s
I pod sono generati in sequenza.
Il pod web-1 viene generato solo quando il pod web-0 è nello stato di Running.
Il servizio è dato da:
kubectl get service nginx
Lo StatefulSet è dato da:
kubectl get statefulset web
I pod dell'applicativo si possono vedere con:
kubectl get pods -l app=nginx
Ogni pod ha uno hostname basato sul suo numero ordinale. Si possono vedere con:
for i in 0 1; do kubectl exec "web-$i" -- sh -c 'hostname'; done
Il loro nome è risolto al DNS di cluster. Si può compire un'interrogazione lanciando un pod aggiuntivo nel cluster:
kubectl run -i --tty --image busybox:1.28 dns-test --restart=Never --rm
E al pronto risultante dare:
nslookup web-0.nginx
Proviamo a cancellare esplicitamente i pod dello StatefulSet.
In una finestra digitare:
kubectl get pod --watch -l app=nginx
E nell'altra finestra digitare:
kubectl delete pod -l app=nginx
I pod vengono cancellati, ma subito ricreati, in ordine.
Scalare uno StatefulSet
In una finestra dare:
kubectl get pods --watch -l app=nginx
E nell'altra finestra:
kubectl scale sts web --replicas=5
Si nota che la creazione di nuovi pod procede per gradi, il nuovo pod sequenziale non viene creato finchè il precedente non è nello ststo di Running.
Si può anche scalare a decrescere, applicando una patch:
kubectl patch sts web -p '{"spec":{"replicas":3}}'
E' da notare che i Persistent Volume Claims sono ancora 5:
kubectl get pvc -l app=nginx
I PVC creati da uno StatefulSet non vengono cancellati anche quando sono cancellati i pod che li usano.
E' da notare che durante l'operazione di scale sono stati costruiti tre ulteriori Persistent Volumes, ma con una policy di Delete, anzichè Retain.
Cancellazione di uno StatefulSet
Tramite il manifest:
kubectl delete -f ~/scripts/stateful.yml
I PVC e i loro PV non vengono cancellati. I PV creati da manifest entrano in stato Terminating ma non sono rimossi finchè i corrispondenti PVC non vengono cancellati.
Cancellare a mano i PVC:
kubectl delete pvc www-web-0 www-web-1 www-web-2 www-web-3 www-web-4
I rimanenti PV sono temporaneamente visibili, ma vengono presto cancellati.
Gestione di Deployment e Rollout
Un Deployment, specificato da un manifest in Yaml, gestisce Pods e ReplicaSets in modo flessibile, ottenendo lo stato desiderato a partire dallo stato corrente.
NOTA: Non gestire manualmente i ReplicaSet che appartengono ad un Deployment.
Generazione di Deployment
Esempio. Un Deployment di nginx che gestisce un RepkicaSet con 3 pod.
vim ~/scripts/nginx-depl.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Creare il deployment:
kubectl apply -f ~/scripts/nginx-depl.yml
Visualizzare il deploymant:
kubectl get deployments
Ogni deploymant è un rollout. Visualizzarne lo status:
kubectl rollout status deployment/nginx-deployment
Visualizzare il replicaset:
kubectl get rs
Visualizzare i pod e le loro etichette:
kubectl get pods --show-labels
Ogni pod acquisisce automaticamente l'etichetta pod-template-hash, che lo collega al ReplicaSet.
Update di Deployment
Cambiare la versione di nginx usata:
kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1
Si può naturalmente modificare il file di specifiche ~/scripts/nginx-depl.yml e risottometterlo.
Si può inoltre editare direttamente con:
kubectl edit deployment/nginx-deployment
Verificare lo stato del rollout:
kubectl rollout status deployment/nginx-deployment
Solo un certo numero di pod sono disattivati durante il rollout. Default 25% - parametro maxUnavailable.
Solo un certo numero di pod nuovi sono creati durante il rollout.
Default 25% - parametro maxSurge.
I dettagli sul deployment si ottengono con:
kubectl describe deployments
Ogni rollout che cambia i pod crea una revisione. La revisione non viene creata quando si cambia il numero di pod con un'operazione di scale.
Rollback di un Deployment
Utile quando la nuova versione è in un loop di crash.
Per esempio un update con un errore tipografico:
kubectl set image deployment/nginx-deployment nginx=nginx:1.161
Il sintomo di fallimento è l'output del comando:
kubectl rollout status deployment/nginx-deployment
che rimane piantato a lungo.
Altri sintomi si deducono dai comandi:
kubectl get rs
kubectl get pods
kubectl describe deployment
La storia delle revisioni si ottiene con:
kubectl rollout history deployment/nginx-deployment
Per avere dettagli di una specifica revisione:
kubectl rollout history deployment/nginx-deployment --revision=2
Per compiere il rollback alla revisione precedente:
kubectl rollout undo deployment/nginx-deployment
Per compiere il rollback ad una revisione specifica:
kubectl rollout undo deployment/nginx-deployment --to-revision=2
Controllare il risultato con:
kubectl get deployment nginx-deployment
e con:
kubectl describe deployment nginx-deployment
Scalare un Deployment
Oltre che modificare il manifest, ~/scripts/nginx-depl.yml, e risottometterlo, si può modificare il Deployment col comando diretto:
kubectl scale deployment/nginx-deployment --replicas=10
Se è presente uno autoscaler, si può anche dare il comando:
kubectl autoscale deployment/nginx-deployment --min=10 --max=15 --cpu-percent=80
Questo introduce in Kubernetes un oggetto HPA - Horizontal Pod Autoscaler. Questo avviene anche se lo autoscaler non è abilitato.
Si possono vedere gli oggetti HPA con:
kubectl get hpa
kubectl get hpa -w
L'oggetto si cancella con:
kubectl delete hpa nginx-deployment
Il cluster Kind non fornisce un autoscaler. Minikube si.
Terminare l'Esercizio
kubectl delete -f ~/scripts/nginx-depl.yml
Kubernetes Jobs
Un Job è un oggetto che crea uno o più pod, i quali eseguono una sola volta poi terminano.
Semplice Job
Esempio: un job che calcola il valore di Pi Greco a 2000 cifre decimali.
Scriviamo il Manifest:
vim ~/scripts/jobpi.yml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
Li parametro backoffLimit è il numero massimo di riprove prima di dichiarare fallimento definitivo, con valore di default 6.
Sottoponiamo il manifest a Kubernetes:
kubectl apply -f ~/scripts/jobpi.yml
Controlliamo l'esistenza:
kubectl get job
e del pod sottostante:
kubectl get pod
I Job si possono descrivere:
kubectl describe job pi
Quando un Job termina lo si vede dalla colonna COMPLETIONS. Quando il suo pod termina va nello stato Completed.
Per listare tutti i pod non Completed (ancora attivi) che appartengono ad un Job si può usare l'espressione:
pods=$(kubectl get pods --selector=batch.kubernetes.io/job-name=pi --output=jsonpath='{.items[*].metadata.name}')
echo $pods
Per vedere l'output dei pod di un Job si può usare:
kubectl logs jobs/pi
3.141592653589793238462643383279502884197169.....
Rimuoviamo il Job tramite Manifest:
kubectl delete -f ~/scripts/jobpi.yml
La rimozione di un job rimuove i suoi pod.
CronJob
Un CronJob compie attività a intervalli regolari schedulati nel futuro.
E' l'equivalente dell'ambiente cron nel mondo Unix/Linux.
Esempio. Un cronJob che scrive l'ora corrente e un messaggio ogni minuto.
vim ~/scripts/cronjob.yml
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
A intervalli di un minuto viene creato un nuovo pod che esegue il comando specificato.
La schedulazione è data dal campo .spec.schedule, che ha lo stesso formato del cron di Unix.
# ┌───────────── minute (0 - 59)
# │ ┌───────────── hour (0 - 23)
# │ │ ┌───────────── day of the month (1 - 31)
# │ │ │ ┌───────────── month (1 - 12)
# │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday)
# │ │ │ │ │ OR sun, mon, tue, wed, thu, fri, sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
Sono disponibili delle macro:
| Macro | Equivalente a |
|---|---|
| @yearly | 0 0 1 1 * |
| @monthly | 0 0 1 * * |
| @weekly | 0 0 * * 0 |
| @daily | 0 0 * * * |
| @hourly | 0 * * * * |
Il campo .spec.jobTemplate ha lo stesso schema di un Job. Si possono anche usare in esso metadati come labels e annotations.
Sottomettiamo il Manifest:
kubectl apply -f ~/scripts/cronjob.yml
Controlliamo l'esistenza del CronJob:
kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello * * * * * False 0 14s 30s
Dopo qualche minuto controlliamo i Job e i Pod:
kubectl get cronjobs
kubectl get jobs
kubectl get pods
Notare che il nome è costruito a partire dal nome del CronJob.
I nostri pod del Cronjob scrivono ciascuno al suo standard output, quindi nei logs. L'output di un pod è visibile con, p.es.:
kubectl logs hello-28474168-pdh77
Tue Feb 20 17:38:04 UTC 2024
Hello from the Kubernetes cluster
Calibrazione dei Job
Storia dei Job
Anche dopo molti minuti il rapporto mantiene una storia di poche entries. La storia mantenuta è controllata dai parametri:
.spec.successfulJobsHistoryLimit- lunghezza della storia dei jobs/pods che hanno avuto successo (default 3).spec.failedJobsHistoryLimit- lunghezza della storia dei jobs/pods che sono falliti (default 1)
Partenza Ritardata dei Job
Il campo opzionale .spec.startingDeadlineSeconds definisce una tolleranza in secondi per la partenza di un job (default: infinito), se per qualsiasi ragione il job non riesce a partire al momento schedulato.
Non settare mai il parametro inferiore a 10 secondi, o il job può non venire mai eseguito.
Se passa il tempo di tolleranza il job è considerato fallito.
Concorrenza
E' quando il job precedente è ancora in esecuzione e viene schedulato un nuovo job uguale.
Questo è controllato dal parametro .spec.concurrencyPolicy che può avere i seguenti valori:
Allow- (default) concessoForbid- proibito. Il nuovo job schedulato fallisce.Replace- il nuovo job schedulato parte. Il vecchio job non ancora completato, fallisce.
Sospensione
Si può sospendere l'esecuzione di un Job o CronJob settando il parametro .spec.suspend al valore true (default: false).
I job già partiti non sono toccati.
Si possono cambiare i cronjob già attivi, oltre che modificare e sottomettere il Manifest. Per esempio:
kubectl patch cronjob hello -p '{"spec":{"suspend":true}}'
La stringa di patch può essere in Json o Yaml.
ATTENZIONE: Quando un CronJob è sospeso e passano i momenti di schedulazione dei suoi Job, questi vengono accodati. Quando si toglie la sospensione i Job accodati vengono eseguiti simultaneamente. Il comportamento dipende dai settaggi .spec.startingDeadlineSeconds e .spec.concurrencyPolicy.
Terminare l'Esercizio
kubectl delete -f ~/scripts/cronjob.yml
Labels ed Annotazioni
Le Label sono usate principalmente per identificare e raggruppare risorse da Kubernetes ed hanno un significato semantico.
Le Annotation sono per Kubernetes degli oggetti opachi e non hanno impatto sulle operazioni interne. Sono metadati non identificativi aggiunte arbitrariamente ad un oggetto.
Sono dei clients come strumenti e librerie che eventualmente raccolgono questi dati.
Sia le annotazioni che le etichette sono mappe chiave-valore.
Un'annotazione ha la struttura:
[prefisso/]mome: "valore"
Il nome:
- è un requisito
- é lungo al massimo 63 caratteri, inizia e termina con un carattere alfanumerico, può avere trattini, punti e underscores
Il prefisso:
- è opzionale
- è lungo al massimo 253 caratteri
- è un dominio DNS
Il valore
- è un requisito
- è una stringa formattata JSON
Esempio:
apiVersion: v1
kind: Pod
metadata:
name: annotations-demo
annotations:
imageregistry: "http://localhost:5000/"
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
Specifica da quale registry provengono le immagini. E'da notare però che l'immagine è comunque scaricata dal Docker Hub e non dal registry locale.
Le annotations sono lette da tools esterni, non dal Kubernetes corrente.
Le annotazioni sono in genere poste manualmente nel Manifest dell'oggetto creato. Però in certi casi possono essere create ed usate da tools esterni di controllo o gestione.
Per esempio lo Horizontal Pod Autoscaler (HPA) genera annotazioni.
Oltre che porre annotazioni nel Manifest di un oggetto si può annotare un oggetto già esistente col comando kubectl annotate.
Esempi:
- Update del pod 'foo' con la annotation 'description' e il valore 'my frontend'
kubectl annotate pods foo description='my frontend'
- Update di un pod identificato nel file "pod.json"
kubectl annotate -f pod.json description='my frontend'
- Riscrivere un'annotazione esistente
kubectl annotate --overwrite pods foo description='my frontend running nginx'
- Update di un'annotazione in tutti i pod del namespace (-A: in tutti i namespace)
kubectl annotate pods --all description='my frontend running nginx'
- Update del pod 'foo' solo se la risorsa non è cambiata dalla versione 1
kubectl annotate pods foo description='my frontend running nginx' --resource-version=1
- Rimuovere un'annotazione
kubectl annotate pods foo description-
Esempio. Sia dato il Manifest:
vi ~/scripts/annotations.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: dashboard
environment: test
annotations:
build-info: |
{
"commit": "abcd123",
"timestamp": "2023-05-01T10:00:00Z"
}
spec:
containers:
- name: frontend-nginx
image: nginx
Una volta creato l'oggetto si possono compiere delle query basate sia sulle label che sulle annotation.
kubectl get pods nginx-pod -o yaml | grep -A2 'labels:'
labels:
app: dashboard
environment: test
kubectl get pods nginx-pod -o yaml | grep -A5 'annotations:'
annotations:
build-info: |
{
"commit": "abcd123",
"timestamp": "2023-05-01T10:00:00Z"
}
kubectl get pods --selector='app=dashboard'
NAME READY STATUS RESTARTS AGE
nginx-pod 1/1 Running 0 5m33s
kubectl get pods --selector='app in (dashboard), environment in (test)'
NAME READY STATUS RESTARTS AGE
nginx-pod 1/1 Running 0 7m36s
E in generale si può usare la meravigliosa utility jq per compiere queries su stringhe JSON:
kubectl get pods -o json | \
jq -r '.items[] | select(.metadata.annotations."build-info" | fromjson | .commit=="abcd123") | .metadata.name'
nginx-pod
Terminare l'Esercizio
kubectl delete -f ~/scripts/annotations.yml
Controllo di Sanità e Probes
Kubernetes fornisce due tipi di sonde (probes) per testare l'usabilità di un applicativo: Liveness Probes e Readiness Probes.
Un Liveness Probe testa se l'applicativo è vivo e raggiungibile. Se non lo è, il pod che lo implementa viene terminato e ristartato.
Un Readiness Probe testa se l'applicativo può ricevere traffico del tipo programmato, Se non può, non viene inviato traffico al pod che lo implementa.
Vi sono tre tipi di probe; HTTP, Comando e TCP.
- HTTP - Kubernetes accede ad un path HTTP del pod, e se il responso ha i codici tra il 200 e il 300 lo considera attivo. Un pod può implementare un miniserver HTTP a questo solo scopo.
- Command - viene eseguito un comando nel pod, e se ritorna un codice di ritorno 0 viene considerato attivo.
- TCP - viene aperta una connessione al pod, e se ha successo il pod è considerato attivo.
Command Liveness
Esempio di Liveness Probe:
vim ~/scripts/liveness.yml
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: registry.k8s.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 40; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
I parametri sono:
initialDelaySeconds- quanto tempo attendere prima di inviare il primo probeperiodSeconds- ogni quanto tempo inviare i probe
Sottomettere il manifest:
kubectl apply -f ~/scripts/liveness.yml
Ispezionare gli eventi del pod:
kubectl describe pod liveness-exec
Kubernetes inizia subito ad inviare liveness probes, anche quando il pod non è in stato di Running. Quindi possono esservi degli eventi di fallimento iniziali. Possono essere gestiti aumentando il parametro initialDelaySeconds.
Dopo un certo periodo di tempo il pod è stabile e il rapporto da:
kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 7 (78s ago) 20m
In caso di fallimento si vede un esempio di questo tipo:
Warning Unhealthy 7m17s (x19 over 16m) kubelet Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Warning BackOff 2m27s (x22 over 9m17s) kubelet Back-off restarting failed container liveness in pod liveness-exec_default(0726f57d-8dd9-489d-b0c5-ff352bfdc084)
E il pod è:
kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-exec 0/1 CrashLoopBackOff 7 (5m11s ago) 17m
Terminare il pod:
kubectl delete -f ~/scripts/liveness.yml
HTTP Liveness
Esempio:
vim ~/scripts/http-liveness.yml
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
L'immagine registry.k8s.io/liveness è appositamente didattica.
E' stata scritta in linguaggio Go e contiene il route handler:
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
duration := time.Now().Sub(started)
if duration.Seconds() > 10 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write([]byte("ok"))
}
})
Il responso è appositamente accurato per i primi 10 secondi, ma poi fallisce. Con un Liveness Probe il pod viene ristartato.
Sottomettiamo il manifest:
kubectl apply -f ~/scripts/http-liveness.yml
E ben presto abbiamo una situazione di questo tipo:
kubectl get pod
NAME READY STATUS RESTARTS AGE
liveness-http 1/1 Running 2 (13s ago) 75s
Con l'evento dedotto da:
kubectl describe pod liveness-http
.....
Warning Unhealthy 1s (x4 over 28s) kubelet Liveness probe failed: HTTP probe failed with statuscode: 500
Terminiamo l'esercizio:
kubectl delete -f ~/scripts/http-liveness.yml
HTTP Readiness
Una leggera modifica alle specifiche di liveness:
vim ~/scripts/http-readiness.yml
apiVersion: v1
kind: Pod
metadata:
labels:
test: readiness
name: readiness-http
spec:
containers:
- name: readiness
image: registry.k8s.io/liveness
args:
- /server
readinessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
Sottomettere il manifest:
kubectl apply -f ~/scripts/http-readiness.yml
Inizialmente il pod si comporta come prima, e dopo 10 secondi fallisce. Kubernetes lo dichiara fallito e non lo ristarta.
Il rapporto di eventi è:
kubectl describe pod readiness-http
.....
Warning Unhealthy 18s (x21 over 75s) kubelet Readiness probe failed: HTTP probe failed with statuscode: 500
E il pod:
kubectl get pod
NAME READY STATUS RESTARTS AGE
readiness-http 0/1 Running 0 2m5s
Pulire l'esercizio:
kubectl delete -f ~/scripts/http-readiness.yml
TCP Liveness e Readiness
Prepariamo un manifest:
vim ~/scripts/tcp-liveness-readiness.yml
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: registry.k8s.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
Ha entrambi i tipi di probe, a scopo didattico per notare che non vi è differenza sintattica ma solo di comportamento. Basta uno o l'altro probe.
Kubernetes prova un'apertura di connessione alla porta 8080. Se ha successo il pod è alive/ready.
Sottomettiamo il manifest:
kubectl apply -f ~/scripts/tcp-liveness-readiness.yml
Non vi sono eventi di errore dopo tempo ragguardevole. Il pod sta bene.
Terminiamo l'esercizio:
kubectl delete -f ~/scripts/tcp-liveness-readiness.yml
Sicurezza e Controllo di Accesso
Modello
Una tipica rcichiesta API dal client kubectl allo API Server di Kubernetes passa possibilmente attraveso alcune fasi di sicurezza:
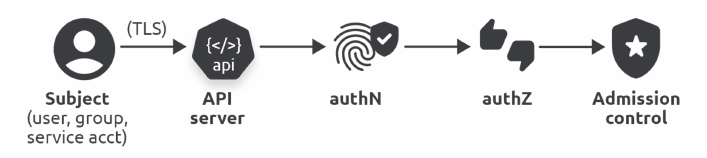
Le fasi sono:
- Autenticazione
- Autorizzazione RBAC
- Controllo di Accesso
RBAC è il modello di autorizzazjone usato da Kubernetes: Role Based Access Control.
Questo modello implementa il Principio del Minimo Privilegio: tutte le azioni sono proibite a meno che esista una regola che le consenta.
Esempio: L'utente pippo vuole creare un Deployment app1 nel namespace util.
- il modulo di autenticazione determina se pippo è un utente reale o un impostore
- il modulo di autorizzazione determina se pippo ha il permesso di creare un Deloyment nel namespace util
- il controllo di accesso applica le policy di creazione di Deployment
Autenticazione
Livello indicato anche come AuthN (auth-enne).
Le richieste API includono credenziali e il modulo le verifica. Se la verifica fallisce, viene ritornato un errore HTTP 401.
Il modulo non è parte di Kubernetes, che non si occupa di gestione account. Questa è fornita dall'esterno, possibilmente con un plugin, p.es. il Cloud Provider fornisce il plugin e le credenziali di autenticazione.
Le credenziali di autenticazione sono mantenute nel file di kubeconfig, che nel caso di Linux è $HOME/.kube/config.
less ~/.kube/config
...
users:
- name: kind-kind
user:
client-certificate-data: ...
client-key-data: ...
...
Si può vedere la configurazione più concisamente col comando:
kubectl config view
Nel nostro caso è un Certificato Client, supportato da ogni versione di Kubernetes.
Questo certificato è stato prodotto da Kind in fase di installazione del cluster. Alternativamente si possono usare strumenti esterni per generarlo, e inserirlo nel file di configurazione.
Si può ispezionare il certificato degli utenti installando l'utility jq:
sudo apt install jq
E dando il comando:
kubectl config view --raw -o json \
| jq ".users[] | select(.name==\"$(kubectl config current-context)\")" \
| jq -r '.user["client-certificate-data"]' \
| base64 -d | openssl x509 -text
Autorizzazione
Abbreviato in AuthZ (auth-zi).
Si occupa di tre aspetti:
- users
- actions
- resuorces
Descrive quali users possono compire quali actions su che tipo di resources.
Un esempio può essere dato dalla seguente tabella:
| User (subject) | Action | Resource |
|---|---|---|
| Bao | create | Pods |
| Kalila | list | Deployments |
| Josh | delete | ServiceAccounts |
RBAC si basa su due concetti:
- Role - definisce un insieme di permessi
- RoleBinding - concede i permessi a utenti
Role
Un esempio di Manifest che definisce un Role:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: shield
name: read-deployments
rules:
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "watch", "list"]
Notare la particolare apiVersion.
Notare le direttive:
namespace- si applica a questo spazio nomiapiGroups- indica la componente gruppo del campoapiVersion- per esempio sappiamo che i Deployments hanno apiVersion
apps/v1 - se
apiGroupsè omesso o seapiGroups: [""], allora è lo apiGroup core, p.es. Services che ha soloapiVersion: v1
- per esempio sappiamo che i Deployments hanno apiVersion
resources- quali oggetti Kubernetes sono influitiverbs- quali comandi dikubectlsi possono usare
Per avere una lista dei verbi disponibili per ogni risorsa:
kubectl api-resources --sort-by name -o wide
Nei campi apiGroups, resources e verbs si può mettere un asterisco (*) che indica tutti i valori.
Per esempio:
...
rules:
- apiGroups: ["*"]
resources: ["*"]
verbs: ["*"]
...
RoleBinding
Un Role deve essere collegato ad un utente con un RoleBinding.
Esempio:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-deployments
namespace: shield
subjects:
- kind: User
name: sky
# This is the authenticated user
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: read-deployments
# This is the Role to bind to the user
apiGroup: rbac.authorization.k8s.io
L'utente autenticato "sky" può compiere un comando come: kubectl get deployments -n shield.
Con adeguata progettazione dei Role e RoleBinding si ottiene che certi utenti autenticati possano compiere solo certe azioni solo su certi oggetti di un determinato spazio nomi.
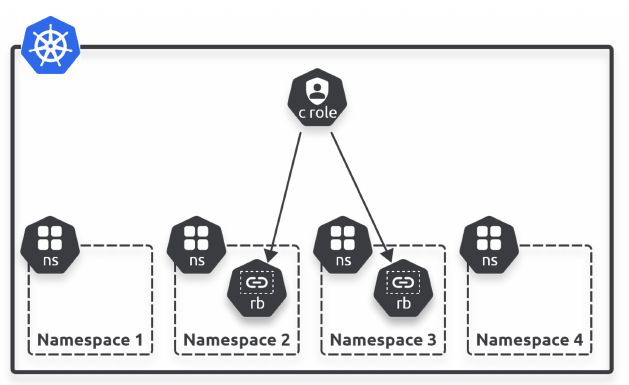
Cluster Level
Vi sono in realtà 4 oggetti RBAC:
- Roles
- ClusterRoles
- RoleBindings
- ClusterRoleBindings
Roles e RoleBindings sono specifici di namespace.
ClusterRoles e ClusterRoleBindings si applicano all'intero cluster.
ClusterRole
Esempio:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: read-deployments
rules:
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "watch", "list"]
NOTA
Questo è solo un esempio. In generale non è una buona idea modificare i ClusterRole o ClusterRoleBinding se non si procede com molta cautela
Una serie di ClusterRole sono definiti nel cluster. Per vederli:
kubectl get clusterrole
Molti sono creati all'atto dell'installazione del cluster. Alcuni sono stati aggiunti da Manifests.
Per vedere i dettagli di un ClusterRole, p.es.:
kubectl describe clusterrole metallb-system:controller
ClusterRoleBinding
Vedere tutti i ClusterRoleBinding:
kubectl get vlusterrolebinding
Vedere i dettagli di uno, p.es.:
kubectl describe clusterrolebinding system:basic-user
Name: system:basic-user
Labels: kubernetes.io/bootstrapping=rbac-defaults
Annotations: rbac.authorization.kubernetes.io/autoupdate: true
Role:
Kind: ClusterRole
Name: system:basic-user
Subjects:
Kind Name Namespace
---- ---- ---------
Group system:authenticated
Sequenza
Il cluster ispeziona il certificato dell'utente che accede, ricercando il campo "Subject:". Lo possiamo vedere da:
kubectl config view --raw -o json \
| jq ".users[] | select(.name==\"$(kubectl config current-context)\")" \
| jq -r '.user["client-certificate-data"]' \
| base64 -d | openssl x509 -text | grep "Subject:"
Subject: O = system:masters, CN = kubernetes-admin
Ne estrae la proprietà O che ha valore system:masters. Questo è un gruppo predefinito che equivale agli amministratori globali di sistema.
Il ClusterRoleBinding corrispondente, predefinito, è cluster-admin. Lo si può vedere con:
kubectl describe clusterrolebinding cluster-admin
Name: cluster-admin
Labels: kubernetes.io/bootstrapping=rbac-defaults
Annotations: rbac.authorization.kubernetes.io/autoupdate: true
Role:
Kind: ClusterRole
Name: cluster-admin
Subjects:
Kind Name Namespace
---- ---- ---------
Group system:masters
Il ClusterRole associato è cluster-admin. Possiamo ispezionarlo con:
kubectl describe clusterrole cluster-admin
Name: cluster-admin
Labels: kubernetes.io/bootstrapping=rbac-defaults
Annotations: rbac.authorization.kubernetes.io/autoupdate: true
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
*.* [] [] [*]
[*] [] [*]
Questo equivale in pratica a tutti i permessi su tutti gli spazi nomi.
Controllo Accesso
E' basato su una serie di Policy ed è implementato da degli Admission Controllers.
Vi sono due tipi di Admission Controllers:
- validating - controllano la validità di una richiesta ma non possono cambiarla
- mutating - possono modificare una richiesta
Gli Admission Controllers di tipo Mutating sono eseguiti per primi.
Un'implementazione di cluster ha un numero considerevole di Admission Controllers. Sono controllati da un numero considerevole di settaggi nei Manifest delle risorse gestite.
Per esempio, il settaggio .spec.containers.imagePullPolicy corrisponde al controller AlwaysPullImages.
La possibilità di loro gestione è determinata dall'implementazione del cluster, ed è di solito eseguita col comando kube-apiserver.
Nell'implementazione cluster Kind questo comando non è direttamente usabile ma è interno al pod kube-apiserver-kind-control-plane nello spazio nomi kube-system.
Per vedere i Controllers installati in Kind, il comando può essere:
kubectl exec kube-apiserver-kind-control-plane \
-n kube-system -- kube-apiserver --help | \
grep enable-admission-plugins | grep enabled | \
cut -d. -f2
Sfortunatamente il controllo fine può essere eseguito solo modificando il codice sorgente di Kind.
Esempi
Il Manifest di creazione del servizio di Metallb fornisce numerosi esempi d'uso di controllo di accesso.
Creazione di ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app: metallb
name: controller
namespace: metallb-system
Definizione di ClusterRole
Il ClusterRole è globale di cluster.
Una serie di regole, ciascuna contraddistinta da apiGroups/resources.
Quali sono i verbi, cioè le azioni, che chi possiede questo ClusterRole può compiere sugli apiGroups/resources.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app: metallb
name: metallb-system:controller
rules:
- apiGroups:
- ''
resources:
- services
verbs:
- get
- list
- watch
- apiGroups:
- ''
resources:
- services/status
verbs:
- update
- apiGroups:
- ''
resources:
- events
verbs:
- create
- patch
- apiGroups:
- policy
resourceNames:
- controller
resources:
- podsecuritypolicies
verbs:
- use
Definizione di Role
Locale di namespace. Serie di regole serie di regole, ciascuna contraddistinta da apiGroups/resources.
Quali sono i verbi, cioè le azioni, che chi possiede questo ClusterRole può compiere sugli apiGroups/resources.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
labels:
app: metallb
name: config-watcher
namespace: metallb-system
rules:
- apiGroups:
- ''
resources:
- configmaps
verbs:
- get
- list
- watch
Chi possiede il ruolo config-watcher, solo nel namespace metallb-system: su tutti i ConfigMaps può dare i comandi kubectl get, kubectl list e kubectl watch.
In realtà non sono comandi client di kubectl, sono verbi della API REST che vengono inviati allo API Server.
Definizione di RoleBinding
Associazione tra ServiceAccount e Role.
Questo RoleBinding si chiama config-watcher, che è anche il nome di un Role: non confondersi, sono due oggetti diversi.
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
app: metallb
name: config-watcher
namespace: metallb-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: config-watcher
subjects:
- kind: ServiceAccount
name: controller
- kind: ServiceAccount
name: speaker
DaemonSet
Finalmente il Daemonset contiene specifiche di chi può operare.
Contiene anche molti altri elementi interessanti, utili per imparare seguendo gli esempi.
Prima l'intera specifica:
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: metallb
component: speaker
name: speaker
namespace: metallb-system
spec:
selector:
matchLabels:
app: metallb
component: speaker
template:
metadata:
annotations:
prometheus.io/port: '7472'
prometheus.io/scrape: 'true'
labels:
app: metallb
component: speaker
spec:
containers:
- args:
- --port=7472
- --config=config
- --log-level=info
env:
- name: METALLB_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: METALLB_HOST
valueFrom:
fieldRef:
fieldPath: status.hostIP
- name: METALLB_ML_BIND_ADDR
valueFrom:
fieldRef:
fieldPath: status.podIP
# needed when another software is also using memberlist / port 7946
# when changing this default you also need to update the container ports definition
# and the PodSecurityPolicy hostPorts definition
#- name: METALLB_ML_BIND_PORT
# value: "7946"
- name: METALLB_ML_LABELS
value: "app=metallb,component=speaker"
- name: METALLB_ML_SECRET_KEY
valueFrom:
secretKeyRef:
name: memberlist
key: secretkey
image: quay.io/metallb/speaker:v0.12.1
name: speaker
ports:
- containerPort: 7472
name: monitoring
- containerPort: 7946
name: memberlist-tcp
- containerPort: 7946
name: memberlist-udp
protocol: UDP
livenessProbe:
httpGet:
path: /metrics
port: monitoring
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
path: /metrics
port: monitoring
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_RAW
drop:
- ALL
readOnlyRootFilesystem: true
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: speaker
terminationGracePeriodSeconds: 2
La linea:
serviceAccountName: speaker
specifica che questo DaemonSet opera come account Speaker, definito sopra, che ha sicuramente un RoleBinding ad un Role, e quest'ultimo lista le azioni che può compiere sulle varie risorse.
Le linee:
nodeSelector:
kubernetes.io/os: linux
richiedono che il sistema operativo sottostante sia Linux.
Le linee:
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
operator: Exists
richiedono che il pod del DaemonSet corrente non venga schedulato sul Master del cluster.
Il Security Context del contenitore del pod è particolarmente interessante:
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_RAW
drop:
- ALL
readOnlyRootFilesystem: true
L'account che opera i pod di questo DaemonSet, che è speaker:
- non può dare comandi equivalenti a
sudoche compiano un Privilege Escalation - se usa il filesystem di root (quello del container), è in sola lettura
- tutti i capabilities sono tolti eccetto NET_RAW, evidentemente il programma inserito nell'immagine usa solo un socket 'Raw', come fa ad esempio ICMP.
Notare le linee:
- name: METALLB_ML_BIND_ADDR
valueFrom:
fieldRef:
fieldPath: status.podIP
Sono l'assegnazione di valore ad una variabile d'ambiente, prese dal campo status.podIP. Quando il pod è creato e allocato ad un nodo, il suo indirizzo IP è già stato assegnato.
L'interessante è che questo campo non esiste nel Manifest, che descrive il desired state, ma è parte del current state del pod appena creato.
Notare anche i probe Liveness e Readiness.
Deployment
Il Deployment è anch'esso interessante:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: metallb
component: controller
name: controller
namespace: metallb-system
spec:
revisionHistoryLimit: 3
selector:
matchLabels:
app: metallb
component: controller
template:
metadata:
annotations:
prometheus.io/port: '7472'
prometheus.io/scrape: 'true'
labels:
app: metallb
component: controller
spec:
containers:
- args:
- --port=7472
- --config=config
- --log-level=info
env:
- name: METALLB_ML_SECRET_NAME
value: memberlist
- name: METALLB_DEPLOYMENT
value: controller
image: quay.io/metallb/controller:v0.12.1
name: controller
ports:
- containerPort: 7472
name: monitoring
livenessProbe:
httpGet:
path: /metrics
port: monitoring
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
path: /metrics
port: monitoring
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 1
successThreshold: 1
failureThreshold: 3
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- all
readOnlyRootFilesystem: true
nodeSelector:
kubernetes.io/os: linux
securityContext:
runAsNonRoot: true
runAsUser: 65534
fsGroup: 65534
serviceAccountName: controller
terminationGracePeriodSeconds: 0
Vi sono due securityContext, uno a livello container e uno a livello pod. Quest'ultimo è:
securityContext:
runAsNonRoot: true
runAsUser: 65534
fsGroup: 65534
serviceAccountName: controller
L'utente controller, che gestisce questo deployment, se ha interazioni con il Linux sottostante, è mappato all'utente di sistema 65534, gruppo di sistema 65534.
Le annotazioni:
annotations:
prometheus.io/port: '7472'
prometheus.io/scrape: 'true'
vengono usate dall'utility Prometheus se esistente.
Ingress
Un LoadBalancer usa un indirizzo pubblico dal pool di indirizzi per ogni servizio configurato.
In un LoadBalancer implementato localmente gli indirizzi del pool possono essere insufficienti. Se il LoadBalancer è fornito dal Cloud Provider, ogni sua istanza ha un costo.
Ingress espone servizi multipli tramite un unico Load Balancer.
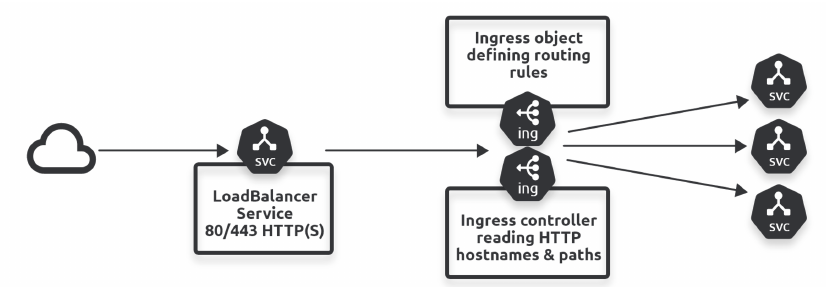
Ha due componenti:
- Ingress controller
- Ingress object
Molte installazioni di cluster Kubernetes, come Kind, non forniscono un Ingress Controller di serie, quindi va installato.
Per l'uso di un cluster Kubernetes di uno specifico Cloud Controller, leggere la documentazione appropriata.
Ingress su Kind
Kind supporta tre Ingress Controllers:
- Contour
- Ingress Kong
- Ingress Nginx
Useremo qui Ingress Nginx-
Modifica del Cluster Kind
Occorre modificare la costruzione del cluster.
Cancellare il cluster corrente con la nostra procedura shell:
cd
./teardown,sh
Creiamo una nuova procedura shell di setup del cluster chiamata ingress.sh:
vim ingerss.sh
#!/bin/sh
set -o errexit
# crea il contenitore del registry se non esiste
reg_name='kind-registry'
reg_port='5000'
if [ "$(docker inspect -f '{{.State.Running}}' "${reg_name}" 2>/dev/null || true)" != 'true' ]; then
docker run \
-d --restart=always -p "127.0.0.1:${reg_port}:5000" --name "${reg_name}" \
-v $HOME/.docker/registry:/var/lib/registry registry:2
fi
# crea un cluster con il registry locale abilitato in containerd
cat <<EOF | kind create cluster --image kindest/node:v1.24.0 --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
containerdConfigPatches:
- |-
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."localhost:${reg_port}"]
endpoint = ["http://${reg_name}:5000"]
nodes:
- role: control-plane
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "ingress-ready=true"
extraPortMappings:
- containerPort: 80
hostPort: 80
protocol: TCP
- containerPort: 443
hostPort: 443
protocol: TCP
extraMounts:
- hostPath: /data
containerPath: /data
- role: worker
extraMounts:
- hostPath: /data
containerPath: /data
- role: worker
extraMounts:
- hostPath: /data
containerPath: /data
EOF
# connette il registry alla rete del cluster se non connesso
if [ "$(docker inspect -f='{{json .NetworkSettings.Networks.kind}}' "${reg_name}")" = 'null' ]; then
docker network connect "kind" "${reg_name}"
fi
# Documenta il local registry
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: local-registry-hosting
namespace: kube-public
data:
localRegistryHosting.v1: |
host: "localhost:${reg_port}"
help: "https://kind.sigs.k8s.io/docs/user/local-registry/"
EOF
La sezione aggiunta, dopo la linea - role: control-plane è:
kubeadmConfigPatches:
- |
kind: InitConfiguration
nodeRegistration:
kubeletExtraArgs:
node-labels: "ingress-ready=true"
extraPortMappings:
- containerPort: 80
hostPort: 80
protocol: TCP
- containerPort: 443
hostPort: 443
protocol: TCP
Rendiamola eseguibile:
chmod +x ingress.sh
Copiamo la procedura di setup in una nuova:
cp setup.sh setup-ingress.sh
Modifichiamo la nuova procedura setup-ingress.sh sostituendo le linee:
echo "~/std.sh"
~/std.sh
con
echo "~/ingress.sh"
~/ingress.sh
Lanciamo il nuovo cluster che supporta Ingress:
./setup-ingress.sh
Deployment di Ingress
Copiamo dalla rete il Deployment del controller di Ingress e poniamolo nella directory ~/scripts:
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/kind/deploy.yaml
mv deploy.yaml ~/scripts/ingress-deploy.yml
Eseguiamo il deployment e attendiamo che sia pronto:
kubectl apply -f ~/scripts/ingress-deploy.yml
echo Waiting up to 120s for nginx-ingress pod ...
kubectl wait --namespace ingress-nginx \
--for=condition=ready pod \
--selector=app.kubernetes.io/component=controller \
--timeout=120s
Test di Ingress
Prepariamo un Manifest di test:
vim ~/scripts/nginx-test.yml
kind: Pod
apiVersion: v1
metadata:
name: foo-app
labels:
app: foo
spec:
containers:
- command:
- /agnhost
- netexec
- --http-port
- "8080"
image: registry.k8s.io/e2e-test-images/agnhost:2.39
name: foo-app
---
kind: Service
apiVersion: v1
metadata:
name: foo-service
spec:
selector:
app: foo
ports:
# Default port used by the image
- port: 8080
---
kind: Pod
apiVersion: v1
metadata:
name: bar-app
labels:
app: bar
spec:
containers:
- command:
- /agnhost
- netexec
- --http-port
- "8080"
image: registry.k8s.io/e2e-test-images/agnhost:2.39
name: bar-app
---
kind: Service
apiVersion: v1
metadata:
name: bar-service
spec:
selector:
app: bar
ports:
# Default port used by the image
- port: 8080
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
spec:
rules:
- http:
paths:
- pathType: ImplementationSpecific
path: /foo(/|$)(.*)
backend:
service:
name: foo-service
port:
number: 8080
- pathType: ImplementationSpecific
path: /bar(/|$)(.*)
backend:
service:
name: bar-service
port:
number: 8080
Lo sottomettiamo:
kubectl apply -f ~/scripts/nginx-test.yml
E attendiamo che i pod vengano creati.
Connessioni di prova:
curl localhost/foo/hostname
foo-app
curl localhost/bar/hostname
bar-app
Al termine cancelliamo dal manifest:
kubectl delete -f ~/scripts/nginx-test.yml
Altro Esempio
Il seguente esempio è preso dal libro The Kubernetes Book di Nigel Poulton.
Abbiamo un Manifest con due pod e due servizi:
mkdir -p ~/scripts/ig
vim ~/scripts/ig/app.yml
apiVersion: v1
kind: Service
metadata:
name: svc-shield
spec:
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
selector:
env: shield
---
apiVersion: v1
kind: Service
metadata:
name: svc-hydra
spec:
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
selector:
env: hydra
---
apiVersion: v1
kind: Pod
metadata:
name: shield
labels:
env: shield
spec:
containers:
- image: nigelpoulton/k8sbook:shield-ingress
name: shield-ctr
ports:
- containerPort: 8080
imagePullPolicy: Always
---
apiVersion: v1
kind: Pod
metadata:
name: hydra
labels:
env: hydra
spec:
containers:
- image: nigelpoulton/k8sbook:hydra-ingress
name: hydra-ctr
ports:
- containerPort: 8080
imagePullPolicy: Always
Sottomettiamo il manifest:
kubectl apply -f ~/scripts/ig/app.yml
Abbiamo due possibilitè per Ingress:
- Host Based Routing - il routing al servizio avviene sulla base dello host di destinazione
- Path Based Routing - il routing al servizio avviene sulla base del Path nella URL
Nell'esercizio la situazione è:
- Host-based: shield.mcu.com >> svc-shield
- Host-based: hydra.mcu.com >> svc-hydra
- Path-based: mcu.com/shield >> svc-shield
- Path-based: mcu.com/hydra >> svc-hydra
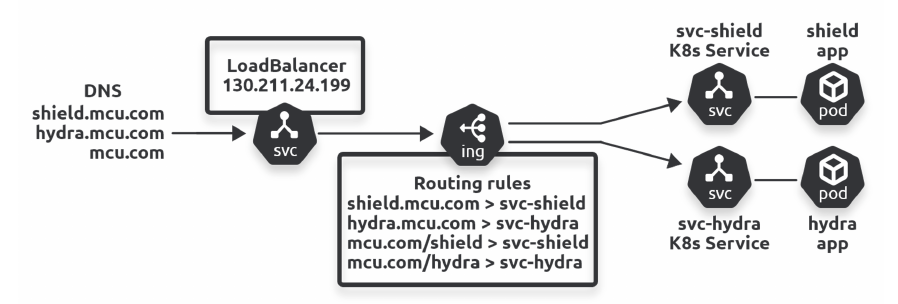
L'oggetto Ingress viene specificato dal manifest:
vim ~/scripts/ig/ig-all.yml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: mcu-all
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: shield.mcu.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-shield
port:
number: 8080
- host: hydra.mcu.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-hydra
port:
number: 8080
- host: mcu.com
http:
paths:
- path: /shield
pathType: Prefix
backend:
service:
name: svc-shield
port:
number: 8080
- path: /hydra
pathType: Prefix
backend:
service:
name: svc-hydra
port:
number: 8080
Note
L'annotazione nginx.ingress.kubernetes.io/rewrite-target: / e' indispensabile per permettere a Ingress il reindirizzamento della richiesta.
E' un esempio di Annotation interpretata da un Controller specifico.
La specifica ingressClassName: nginx non è indispensabile se sul nostro cluster abbiamo solo lo Nginx Ingress Controller.
Qualora vi fossero più Ingress controller dovremmo configurare una classe per ciascuno, per esempio col Manifest:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: igc-nginx
spec:
controller: nginx.org/ingress-controller
Sottoponiamo il manifest:
kubectl apply -f ~/scripts/ig/ig-all.yml
Ispezione degli oggetti Ingress:
kubectl get ing
Descrizione di un oggetto Ingress:
kubectl describe ing mcu-all
Notare la sezione Regole:
Rules:
Host Path Backends
---- ---- --------
shield.mcu.com
/ svc-shield:8080 (10.244.1.10:8080)
hydra.mcu.com
/ svc-hydra:8080 (10.244.2.5:8080)
mcu.com
/shield svc-shield:8080 (10.244.1.10:8080)
/hydra svc-hydra:8080 (10.244.2.5:8080)
Notare anche il campo Address: localhost
Modificare il file /etc/hosts aggiungendo le linee:
127.0.0.1 shield.mcu.com
127.0.0.1 hydra.mcu.com
127.0.0.1 mcu.com
Aprire un browser e testare i seguenti URL:
- shield.mcu.com
- hydra.mcu.com
- mcu.com/shield
- mcu.com/hydra
Al termine ripulire:
kubectl delete -f ~/scripts/ig/ig-all.yml
kubectl delete -f ~/scripts/ig/app.yml
Rimettere anche a posto /etc/hosts.
Storaggio
Kubernetes supporta numerosi tipi di storaggio: iSCSI, SMB, NFS, object storage blobs, ecc. I fornitori (Provisioner) di storaggio possono essere in-house o nel cloud.
E' necessario che Kubernetes installi un plugin per supportare lo storaggio specifico, fornito dal Provisioner.
Il plugin deve essere conforme allo standard CSI - Container Storage Interface.
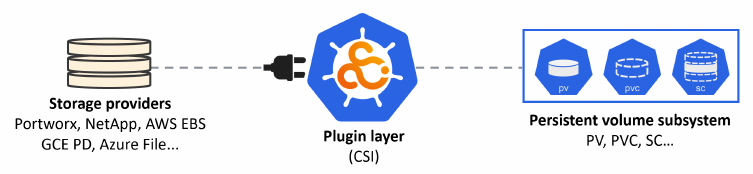
Purtroppo i cluster Kind e Minikube non supportano questa funzionalità e sono limitati allo storaggio Standard - locale, o NFS visto come directory locale.
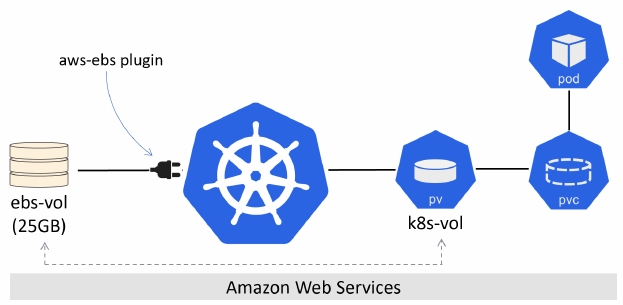
Per esempio un cluster è implementato su AWS e l'amministratore di AWS ha creato un volume di 25GB chiamato ebs-vol. L'amministratore di Kubernetes crea un PV chiamato k8s-vol collegato al volume ebs-vol dal plugin kubernetes.io/aws-ebs.
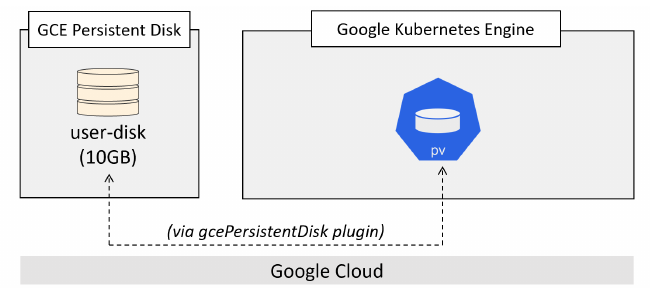
Sistema Persistent Volume
Le tre risorse principlali del sistema Persistent Volume sono:
- Persistent Volume (pv)
- Persistent Volume Claim (pvc)
- Storage Class (sc)
I passi in Kubernetes sono:
- Creare il PV
- Creare il PVC
- Definire il volume nelle specifiche di un Pod
- Montarlo in un container
Esempio di creazione di PV.
vim gke-volume.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
accessModes:
- ReadWriteOnce
storageClassName: test
capacity:
storage: 10Gi
persistentVolumeReclaimPolicy: Retain
gcePersistentDisk:
pdName: user-disk
Il PV è altamente specifico al Provisioner. Per esempio l'attributo gcePersistentDisk si riferisce a Gookle e ha bisogno della presenza del plugin GCE. Il volume user-disk deve essere stato creato prima da GCE.
Anche la storage class di nome test è creata altrove.
Questo è solo un esempio illustrativo, non funziona col nostro cluster.
L'effetto graficamente espresso sarebbe:
La proprietò .spec.persistentVolumeReclaimPolicy dice a Kubernetes cosa farne del disco PV quando non è più in uso.
Due possibilità:
DeleteRetain
Retain ne conserva i dati, ma non sono più accessibili da un altro PVC in futuro. Il PV deve essere rimosso a mano.
Un PVC corrispondente a questo PV sarebbe ad esempio:
vim gke-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
spec:
accessModes:
- ReadWriteOnce
storageClassName: test
resources:
requests:
storage: 10Gi
Vi sono alcune proprietà che devono essere in corrispondenza:

Un pod che usa questo PVC potrebbe essere:
vim volpod.yml
apiVersion: v1
kind: Pod
metadata:
name: volpod
spec:
volumes:
- name: data
persistentVolumeClaim:
claimName: pvc1
containers:
- name: ubuntu-ctr
image: ubuntu:latest
command:
- /bin/bash
- "-c"
- "sleep 60m"
volumeMounts:
- mountPath: /data
name: data
Dynamic Provisioning
Il Dynamic Provisioning è la fornitura da parte del Provider di spazio disco on-demand, quando c'è un Pod che effettivamente lo usa.
Questa funzionalità è basata sul concetto di Storage Class.
Storage Class
Una StorageClass è una risorsa definita nel gruppo API storage.k8s.io/v1. Si riferisce ad un tipo di storaggio offerto da un Provisioner.
Esempio.
vim fast-sc.yml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
zones: eu-west-1a
opsPerGB: "10"
Sottomettere il manifest:
kubectl apply -f fast-sc.yml
Si visionano le storage classes con:
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
fast kubernetes.io/aws-ebs Delete Immediate false 19s
standard (default) rancher.io/local-path Delete WaitForFirstConsumer false 42h
La storage class viene creata anche se il plugin non è disponibile. E' solo al momento di creazione del PVC e Pod che si presentano dei problemi.
Si possono avere molte Storage Classee configurate. I parametri di ciascuna dipendono dal plugin del provisioner.
Per esempio:
vim sc-secure.yml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: portworx-db-secure
provisioner: kubernetes.io/portworx-volume
parameters:
fs: "xfs"
block_size: "32"
repl: "2"
snap_interval: "30"
io-priority: "medium"
secure: "true"
Una StorageClass è un oggetto immutabile. Non si può modificare, solo cancellare e ricreare.
Le fasi d'uso sono:
- Creare il cluster Kubernetes
- Installare i necessari plugin per lo storage
- Creare una StorageClass
- Creare un PVC che si riferisce alla StorageClass
- Creare un Pod che usa un volume basato sul PVC
Non occorre quindi creare un oggetto PV, che è sostituito dalla StorageClass.
Esercizio Demo
Creare una StorageClass
Preparare la directory e creare il file di manifest:
mkdir -p ~/ex/sc
cd ~/ex/sc
vim google-sc.yml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: slow
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-standard
reclaimPolicy: Retain
Applicare il file di manifest:
kubectl apply -f google-sc.yml
Verifica:
kubectl get sc
kubectl describe sc slow
Creare un PVC
Il file di manifest:
vim google-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pv-ticket
spec:
accessModes:
- ReadWriteOnce
storageClassName: slow
resources:
requests:
storage: 25Gi
Applicare il file di manifest:
kubectl apply -f google-pvc.yml
Verificare:
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pv-ticket Pending slow 3s
Notare lo stato Pending. Non abbiamo il driver CSI installato ed è in attesa che venga installato.
Ctreare un Pod
Il file fi manifest:
vim google-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: class-pod
spec:
volumes:
- name: data
persistentVolumeClaim:
claimName: pv-ticket
containers:
- name: ubuntu-ctr
image: ubuntu:latest
command:
- /bin/bash
- "-c"
- "sleep 60m"
volumeMounts:
- mountPath: /data
name: data
Applicare il file di manifest:
kubectl apply -f google-pod.yml
Verifica:
kubectl get pod
NAME READY STATUS RESTARTS AGE
class-pod 0/1 Pending 0 56s
Anch'esso è nello stato Pending.
Ispezionandolo con:
kubectl describe pod class-pod
Notiamo che:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 3m5s default-scheduler 0/3 nodes are available: 3 pod has unbound immediate PersistentVolumeClaims. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling.
Di più non possiamo fare con Kind.
Ripoliamo l'esercizio:
kubectl delete -f google-pod.yml
kubectl delete -f google-pvc.yml
kubectl delete -f google-sc.yml
Autoscaling
Per questo esercizio occorre Minikube.
Lanciare Minikube:
minikube start --base-image='gcr.io/k8s-minikube/kicbase:v0.0.35'
Abilitare lo add-on Metrics Server:
minikube addons enable metrics-server
Controllare gli add-on:
minikube addons list
mkdir -p ~/ex/auto
wget https://k8s.io/examples/application/php-apache.yaml
mv php-apache.yaml ~/ex/auto/php-apache.yml
cd ~/ex/auto
Applichiamo il deployment:
kubectl apply -f php-apache.yml
L'immagine scaricata compie del lavoro intensivo di CPU:
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>
Creiamo uno Horizontal Pod Autoscaler:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
Verifichiamo gli HPA:
kubectl get hpa
Per aumentare il carico, in un'altra finestra:
kubectl run -it --rm load-generator --image=busybox /bin/sh
E all'interno del contenitore lanciamo il comando:
while true; do wget -q -O- http://php-apache; done
Sul primo terminale:
kubectl get hpa -w
kubectl get pods
Torniamo sul secondo terminale e interrompiamo con Ctrl-C.
Sul primo terminale ripetiamo:
kubectl get hpa -w
kubectl get pods
Canccellare lo autoscaler:
kubectl delete hpa php-apache
Pulizia:
kubectl delete -f php-apache.yml
Helm Fondamenti

Helm è un progetto open source che facilità l'impacchettamento, il deployment e l'amministrazione di applicativi su Kubernetes.
Ha il concetto di chart, una collezione di file che descrivono un insieme di risorse Kubernetes-
I chart sono descrizioni accurate, complete e funzionali di un progetto Kubernetes e sono mantenuti in repositories simili a quelli di Docker.
Gli aspetti coperti da questa sezione sono:
- Installazione di Helm
- Comandi di base di Helm - gestione di base di chart esistenti
- Creazione di un chart
- Customizzazione di un chart
Informazioni ufficiali e tutorials su Helm si trovano su https://helm.sh/docs/.
Architettura e Installazione
Componenti di Helm
- Client - strumento da linea di comando che interagisce con l'ambiente Helm
- Chart - collezione di files che definiscono il deployment di un applicativo su Kubernetes
- Repository - collezioni di chart su un server, può essere pubblico o privato
Installazione del Client Helm
Le ultime release di Helm si trovano a https://github.com/helm/helm/releases.
Scaicarlo per la architettura appropriata, estrarlo e spostarlo in una directory del PATH.
Alternativamente usare i seguenti comandi:
curl -fsSL -o get_helm.sh \
https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
Helm deve avere visibilità del cluster Kubernetes, quindi lo installeremo con il secondo metodo.
L'installazione di Helm pone i suoi componenti in locazioni specifiche del sistema corrente, e registra un numero di variabili per raggiungere i componenti.
Queste variabili sono visibili col comando:
helm env
Comandi di Base
Aggiunta df un Repository
Aggiungere un repository:
helm repo add bitnami https://charts.bitnami.com/bitnami
Listare i repositories:
helm repo list
Ricerca del chart drupal:
helm search repo drupal
Ricerca dei chart di Content Management System:
helm search repo content
Ricerca delle versioni disponibili di chart drupal:
helm search repo drupal --versions
La lista può essere lunga.
CHART VERSION è la versione del chart di Helm. APP VERSION è la versione dell'applicativo pacchettizzato nel chart.
Installazione della Release drupal
E' necessario avere un Load Balancer attivo. Noi abbiamo Metallb.
Installazione:
helm install mysite bitnami/drupal
NAME: mysite
LAST DEPLOYED: Sat Feb 10 16:18:03 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: drupal
CHART VERSION: 17.3.4
APP VERSION: 10.2.3** Please be patient while the chart is being deployed **
1. Get the Drupal URL:
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
Watch the status with: 'kubectl get svc --namespace default -w mysite-drupal'
export SERVICE_IP=$(kubectl get svc --namespace default mysite-drupal --template "{{ range (index .status.loadBalancer.ingress 0) }}{{ . }}{{ end }}")
echo "Drupal URL: http://$SERVICE_IP/"
2. Get your Drupal login credentials by running:
echo Username: user
echo Password: $(kubectl get secret --namespace default mysite-drupal -o jsonpath="{.data.drupal-password}" | base64 -d)
Vi sono istruzioni utili per l'utente o amministratore, e conviene leggerle.
E' possibile installare più applicativi uguali nello stesso cluster, a patto che siano in namespace separati. Per esempio:
kubectl create ns first
helm install --namespace first mysite bitnami/drupal
Listare le installazioni:
helm list
helm list --all-namespaces
Documentazione
La documentazione del particolare chart che stiamo installando è a https://artifacthub.io/packages/helm/bitnami/drupal.
ArtifactHub è un sito con documentazione su una svariata quantità di software, in vari formati di pacchettizzazione.
Oltre ad esempi, descizioni e raccomandazioni, vi è una lunga lista di parametri di configurazione.
Rimuovere una Release
helm uninstall mysite
Configurazione di Release
Preparare un file Yaml di configurazione in una directory appropriata:
mkdir -p ~/scripts/drupal
vim ~/scripts/drupal/values.yml
drupalUsername: admin
drupalEmail: admin@example.com
mariadb:
db:
name: "my-database"
Installare una release Helm con il file di configurazione:
helm install mysite bitnami/drupal \
--values ~/scripts/drupal/values.yml
Si puà anche non avere un file di configurazione e modificare parametri di configurazione sulla linea di comando:
helm install mysite bitnami/drupal --set drupalUsername=admin
Per le sottosezioni usare parametri con notazione punto, ad esempio --set mariadb.db.name=my-database.
Si possono avere più opzioni --set.
Si possono avere entrambi il file di configurazione e parametri passati con l'opzione --set. In caso di collisione l'ultimo valore vince.
Upgrade di Installazione
Una release è una particolare combinazione di configurazione e versione di chart per una installazione.
L'installazione di un chart produce una release iniziale.
Un upgrade produce una nuova release della stessa installazione.
Upgrade di Configurazione
Esempio. Un upgrade che cambia solo un parametro di configurazione:
helm upgrade mysite bitnami/drupal --set ingress.enabled=true
In realtà non è così facile. L'errore risultante è esplicativo dei parametri mancanti al comando.
Il nostro applicativo usa tre files di secrets:
- per la password dell'utente drupal
- per la password dell'amministratore del database engine maria-db
- per la password dell'utente che accede al database my-database
Questi tre files vanno preservati durante l'upgrade e quindi le tre password vanno anch'esse settate, invariate. Per scoprirle si caricano i loro valori correnti in variabili d'ambiente con:
export DRUPAL_PASSWORD=$(kubectl get secret \
--namespace "default" mysite-drupal \
-o jsonpath="{.data.drupal-password}" | base64 -d)
export MARIADB_ROOT_PASSWORD=$(kubectl get secret \
--namespace "default" mysite-mariadb \
-o jsonpath="{.data.mariadb-root-password}" | base64 -d)
export MARIADB_PASSWORD=$(kubectl get secret \
--namespace "default" mysite-mariadb \
-o jsonpath="{.data.mariadb-password}" | base64 -d)
E quindi il comando di upgrade è:
helm upgrade mysite bitnami/drupal --set ingress.enabled=true \
--set drupalPassword=$DRUPAL_PASSWORD \
--set mariadb.auth.rootPassword=$MARIADB_ROOT_PASSWORD \
--set mariadb.auth.password=$MARIADB_PASSWORD
Il comando ha così successo.
Anzichè lo upgrade di un solo parametro si può passare un file di configurazione Yaml, come con il caso di installazione, naturalmente con gli stessi problemi di mantenimento dei Secrets.
helm upgrade mysite bitnami/drupal \
--values ~/scripts/drupal/values.yml \
--set drupalPassword=$DRUPAL_PASSWORD \
--set mariadb.auth.rootPassword=$MARIADB_ROOT_PASSWORD \
--set mariadb.auth.password=$MARIADB_PASSWORD
Upgrade di Versione
E' opportuno prima compiere un update di tutti i repositories configurati, per rinfrescare la lista dei chart disponibili:
helm repo update
Per compiere l'upgrade all'ultima versione disponibile:
helm upgrade mysite bitnami/drupal
Naturalmente si possono usare le opzioni --values e/o --set.
Listare le versioni disponibili:
helm search repo drupal --versions
Compiere l'upgrade as una versione data:
helm upgrade mysite bitnami/drupal --version 12.2.10
Si deve dare la versione del chart, non dell'applicativo.
Rimozione di una Release
Dal namespace di default:
helm uninstall mysite
Da un namespace specifico:
helm uninstall mysite --namespace first
La rimozione può richiedere del tempo, mentre Kubernetes elimina tutte le risorse. Durante questo tempo non è possibile compiere un'altra installazione dello stesso applicativo.
Informazioni di Release
Le informazioni sulle varie release sono mantenute come Secrets:
kubectl get secrets
NAME TYPE DATA AGE
mysite-drupal Opaque 1 64m
mysite-mariadb Opaque 2 64m
sh.helm.release.v1.mysite.v1 helm.sh/release.v1 1 64m
sh.helm.release.v1.mysite.v2 helm.sh/release.v1 1 59m
sh.helm.release.v1.mysite.v3 helm.sh/release.v1 1 37m
sh.helm.release.v1.mysite.v4 helm.sh/release.v1 1 18m
sh.helm.release.v1.mysite.v5 helm.sh/release.v1 1 9m11s
Questo rende possible il rollback ad una revisione precedente.
La rimozione di un chart rimuove anche tutte le informazioni di Secrets connesse.
Altri Comandi Helm
Fasi di Esecuzione
Fasi di esecuzione di una installazione (o di un upgrade) di un chart di Helm:
- Caricamento del chart e delle sue dipendenze
- Attualizzazione dei parametri e dei valori
- Esecuzione dei templati e generazione dei file di specifiche Yaml
- Verifica dei dati di generazione di oggetti Kubernetes
- Invio al cluster Kubernetes
Ciascuna di queste fasi può generare errori.
Se nella fase 5 il server Kubernetes accetta i files Yaml, Helm dichiara il successo dell'operazione.
Questo non vuol dire che l'applicativo sia pronto, poichè i pod possono impiegare tempo considerevole a scaricare le immagini.
Alcune opzioni di installazione aiutano:
helm install mysite bitnami/drupal \
--wait --timeout 120
Helm compie allora ripetute queries a Kubernetes e attende che tutti i pod dell'applicativo installato siano running.
E' buona prassi includere una opzione --timeout espressa in secondi, per non attendere rventualmente per sempre. Al termine del periodo di timeout lo stato dell'installazione è failed. Questo può dare delle inconsistenze se il periodo non è abbastanza lungo.
Un'alternativa è:
helm install mysite bitnami/drupal \
--atomic --timeout 120
E'simile a --wait ma in caso di fallimento Helm compie un rollback automatico all'ultima versione di successo.
Dry Run
helm install mysite bitnami/drupal \
--values ~/scripts/drupal/values.yml \
--set drupalEmail=foo@example.com \
--dry-run
Non genera l'applicativo descritto nel chart. Non invia le specifiche al cluster Kubernetes.
Produce molte informazioni di debugging.
- identificativi della release
- lista di tutti i file di specifiche Yaml generati
- note e istruzioni per l'utente
Anche se non viene generato l'applicativo sul cluster, un dry run può contattare il cluster più volte durante le sue fasi, e generare files di specifiche legati al particolare cluster.
Helm Template
Il comando helm template genera solo l'identificativo della release e la lista dei file di specifiche Yaml. Non contatta mai il server Kubernetes.
helm template mysite bitnami/drupal \
--values ~/scripts/drupal/values.yml \
--set drupalEmail=foo@example.com
Non compie validazione dei file Yaml generati.
Ha praticamente le stesse opzioni di helm install.
Release
Partendo da una situazione pulita, installiamo la prima release di drupal:
helm install mysite bitnami/drupal \
--values ~/scripts/drupal/values.yml \
--set drupalEmail=foo@example.com
Vengono generati dei Secrets:
kubectl get secret
NAME TYPE DATA AGE
mysite-drupal Opaque 1 13s
mysite-mariadb Opaque 2 13s
sh.helm.release.v1.mysite.v1 helm.sh/release.v1 1 13s
Helm mantiene le informazioni di release nel secret sh.helm.release.v1.mysite.v1.
L'ultimo è il numero di versione di upgrade. Ad ogni nuovo upgrade compare un nuovo secret con versione v2, v2, ecc. Vengono mantenute al massimo 10 versioni, le più vecchie sono rimosse.
Si può ispezionare il secret di versione con:
kubectl get secret sh.helm.release.v1.mysite.v1 -o json
La sezione maggiore, data, contiene informazioni per ricreare la release, compresse e trascodificate con Base64.
Si possono estrarre queste informazioni con dei comandi.
helm get notes
Note finali per l'utente:
helm get notes mysite
helm get values
Valori parametrici della release.
Valori forniti nel comando di unstallazione o upgrade:
helm get values mysite
Tutti i valori:
helm get values mysite --all
helm get manifest
Tutti i file di specifiche Yaml:
helm get manifest mysite
Helm Upgrade e History
Upgrade
Compiamo un upgrade alla release.
Prepariamo le variabili d'ambiente necessarie:
export DRUPAL_PASSWORD=$(kubectl get secret \
--namespace "default" mysite-drupal \
-o jsonpath="{.data.drupal-password}" | base64 -d)
export MARIADB_ROOT_PASSWORD=$(kubectl get secret \
--namespace "default" mysite-mariadb \
-o jsonpath="{.data.mariadb-root-password}" | base64 -d)
export MARIADB_PASSWORD=$(kubectl get secret \
--namespace "default" mysite-mariadb \
-o jsonpath="{.data.mariadb-password}" | base64 -d)
Compiamo l'upgrade:
helm upgrade mysite bitnami/drupal --set ingress.enabled=true \
--set drupalPassword=$DRUPAL_PASSWORD \
--set mariadb.auth.rootPassword=$MARIADB_ROOT_PASSWORD \
--set mariadb.auth.password=$MARIADB_PASSWORD
History
Ispezioniamo ora la storia delle release:
helm history mysite
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Sun Feb 11 09:37:53 2024 superseded drupal-17.3.4 10.2.3 Install complete
2 Sun Feb 11 10:20:18 2024 deployed drupal-17.3.4 10.2.3 Upgrade complete
Lo status può essere:
- pending-install
- deployed
- pending-upgrade
- superseded
- pending-rollback
- uninstalling
- uninstalled
- failed
Verifichiamo i valori della release:
helm get values mysite -o json
{"drupalPassword":"dcC54IVRFH","ingress":{"enabled":true},"mariadb":{"auth":{"password":"RzY3j10Azv","rootPassword":"3CVLN2SHFV"}}}
Restart dei Pod
Un upgrade è il meno invasivo possibile: Helm richiede il restart di pods solo se ve n'è bisogno. Si può forzare il restart di tutti i pod con l'opzione --force.
Cleanup
Un'installazione o upgrade fallita può lasciare lo stato di Kubernetes inconsistente. Per esempio possono essere stati creati dei Secrets prima del fallimento.
Questo è più probabile se è stata usata l'opzione --wait o --atomic.
Con l'opzione --cleanup-on-fail viene richiesta la rimozione di tutti gli oggetti della release in caso di fallimento.
Questo però non aiuta nell'eventuale debugging.
Rollback
Compiamo un rollback alla versione 1:
helm rollback mysite 1
Verifichiamo che i valori sono ora quelli della versione 1:
helm get values mysite -o json
{"drupalEmail":"foo@example.com","drupalUsername":"admin","mariadb":{"db":{"name":"my-database"}}}
Ispezioniamo la storia:
helm history mysite
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Sun Feb 11 09:37:53 2024 superseded drupal-17.3.4 10.2.3 Install complete
2 Sun Feb 11 10:20:18 2024 superseded drupal-17.3.4 10.2.3 Upgrade complete
3 Sun Feb 11 10:37:54 2024 deployed drupal-17.3.4 10.2.3 Rollback to 1
Si possono compiere queries di un'altra revisione della storia, per esempio:
helm get values mysite --revision 2
E in modo simile per notes e manifest.
Mantenere la Storia
Si può disinstallare una release, ma mantenere la sua storia:
helm uninstall mysite --keep-history
La storia è ora:
helm history mysite
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Sun Feb 11 09:37:53 2024 superseded drupal-17.3.4 10.2.3 Install complete
2 Sun Feb 11 10:20:18 2024 superseded drupal-17.3.4 10.2.3 Upgrade complete
3 Sun Feb 11 10:37:54 2024 uninstalled drupal-17.3.4 10.2.3 Uninstallation complete
Con la storia presente, si può compiere un rollback ad una previa versione anche se quella corrente non è installata.
Generazione di un Chart
Creazione di un Chart
Helm fornisce un chart di default basato sull'applicativo Nginx.
Questo si chiama uno Starting Point.
Nginx è un buon starting point per applicativi stateless.
Helm fornisce degli starter packs per la creazione di altri modelli di applicativi.
La generazione di un chart di default è:
helm create anvil
Viene creata una sottodirectory anvil con la struttura:
tree anvil
anvil
├── Chart.yaml
├── charts
├── templates
│ ├── NOTES.txt
│ ├── _helpers.tpl
│ ├── deployment.yaml
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── service.yaml
│ ├── serviceaccount.yaml
│ └── tests
│ └── test-connection.yaml
└── values.yaml
Nella directory anvil:
Chart.yaml- semplicemente descrive i numeri di versione del chart e dellìapplicativovalues.yaml- fornisce valori di default per la configurazione dell'applicativo. E' qui che viene configurato di default l'applicativo nginx.
Nella sottodirectory templates vi sono templati per la generazione di file Yaml dell'applicativo:
NOTES.txt- le note per l'utente_helpers.tpl- spezzoni di templati che vengono inclusi in altri templatideploymeny.yaml- per il deploymenthpa.yaml- per lo HorizontalPodAutoscaleringress.yaml- per Ingressservice.yaml- per il servizioserviceaccount.yaml- per il ServiceAccount
La sintassi dei Templates è quella del linguaggio Go, quando con tale linguaggio si preparano applicativi web.
La sottodirectory tests contiene il file test-connection.yaml, che genera un pod per il test di connessione a Nginx.
Tutti questi files sono editabili, per indicare e personalizzare il nostro applicativo al posto di Nginx.
Installazione del Chart
Il chart prototipo è direttamente installabile.
Posizionarsi della directory a monte di anvil e dare il comando:
helm install myapp anvil
NAME: myapp
LAST DEPLOYED: Sun Feb 11 12:53:52 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=anvil,app.kubernetes.io/instance=myapp" -o jsonpath="{.items[0].metadata.name}")
export CONTAINER_PORT=$(kubectl get pod --namespace default $POD_NAME -o jsonpath="{.spec.containers[0].ports[0].containerPort}")
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl --namespace default port-forward $POD_NAME 8080:$CONTAINER_PORT
Il servizio installato nell'applicativo myapp è di tipo ClusterIP:
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 41h
myapp-anvil ClusterIP 10.96.253.188 <none> 80/TCP 4m53s
Ciò vuol dire che il servizio non è direttamente accessibile dall'esterno. Le Note forniscono un workaround, per il testing, con i comandi:
export POD_NAME=$(kubectl get pods --namespace default \
-l "app.kubernetes.io/name=anvil,app.kubernetes.io/instance=myapp" \
-o jsonpath="{.items[0].metadata.name}")
export CONTAINER_PORT=$(kubectl get pod --namespace default \
$POD_NAME -o jsonpath="{.spec.containers[0].ports[0].containerPort}")
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl --namespace default \
port-forward $POD_NAME 8080:$CONTAINER_PORT
L'ultimo comando è bloccante. Aprire un'altro terminale collegato al contenitore kub e dare il comando di test:
curl http://127.0.0.1:8080
Vi sono quattro tipi di servizio previsti:
- ClusterIP - default in questo applicativo
- NodePort
- LoadBalancer
- Ingress
Disinstallare al termine l'applicativo con il comando:
helm delete myapp
Files del Chart
Chart.yaml
Si possono aggiungere numerose altre proprietà oltre a quelle presenti.
Per esempio modificarla in:
apiVersion: v2
name: anvil
description: A surprise to catch something speedy.
version: 0.1.0
appVersion: 9.17.49
icon: https://wile.example.com/anvil.svg
keywords:
- road runner
- anvil
home: https://wile.example.com/
sources:
- https://github.com/Masterminds/learning-helm/tree/main/chapter4/anvil
maintainers:
- name: ACME Corp
email: maintainers@example.com
- name: Wile E. Coyote
email: wile@example.com
La proprietà type: application può essere omessa poichè è il default. L'alternativa è type: library.
Package di Chart
La struttura gerarchica di un package viene trasformata in un archivio tar compresso col comando:
helm package anvil
In luogo di anvil si può dare il percorso, assoluto o relativo, della directory di testa del chart gerarchico.
Il risultato viene posto nella directory corrente ove si da il comando, e in questo caso è anvil-0.1.0.tgz.
La versione numerica è quella del chart, descritta nel file Chart.yaml.
Sono previste delle opzioni:
--dependency-update (-u)- compie un update dei chart dipendenti--destination (-d)- setta la locazione dell'archivio se diversa dalla directory corrente--app-version- cambia la versione dell'applicativo dal default descritto daCharts.yaml--version- cambia la versione del chart dal default descritto daCharts.yaml
Vi sono anche delle opzioni per la firma crittografica del chart, usando PGP (Pretty Good Privacy). I comandi Helm install e upgrade hanno corrispondenti opzioni per la verifica della firma.
Il file eventiale ,helmignore nella directory corrente specifica files e directories da non inserire nell'archivio del chart. La sua struttura è uguala a quella di .gitignore.
Lint di Chart
Lint è uno strumento di analisi statica del chart, ed è utile eseguirlo prima della generazione del pacchetto, per trovare errori ed inconsistenze.
helm lint anvil
Si può anche eseguire su un chart raccolto in archivio:
helm lint anvil-0.1.0.tgz
Lint può generare notifiche di livello INFO, WARNING o ERROR.
Il livello ERROR fa si che il comando lint generi un codice di ritorno diverso da zero, utile quando inserito in una procedura shell.
Con l'opzione --strict anche WARNIBG genera un codice di ritorno diverso da zero.
Helm Avanzato

Helm è un ambiente complesso.
Gli aspetti coperti da questa sezione sono:
- Templati per i chart - sintassi di costruzione del templato di un applicativo Kubernetes
- Dipendenze dei chart - carts che dipendono da altri charts
- Hooks di Helm - azioni ayyivate a punti specifici del ciclo di vita di un chart
- Repositories privati - setup e amministrazione
Esempio di Chart
Desideriamo produrre un Chart di Helm che automatizzi l'installazione di un nostro precedente applicativo: Wordpress e MySQL.
L'esercizio presume che le immagini verranno scaricate dal registry locale.
Se non presenti dare i comandi:
docker pull mysql:5.6
docker tag mysql:5.6 localhost:5000/mysql:5.6
docker push localhost:5000/mysql:5.6
docker pull wordpress:4.8-apache
docker tag wordpress:4.8-apache localhost:5000/wordpress:4.8-apache
docker push localhost:5000/wordpress:4.8-apache
Scaffolding del Chart
Un Chart non è altro che una directory con una determinata struttura.
Preparare lo scaffolding:
mkdir -p wordpress/charts wordpress/templates/tests
touch wordpress/Chart.yaml wordpress/values.yaml
touch wordpress/templates/01pvpvc-mysql.yaml
touch wordpress/templates/02mysql.yaml
touch wordpress/templates/03pvpvc-wpress.yaml
touch wordpress/templates/04wpress.yaml
Tutti i file contenuti nella directory templates sono considerati dei manifest a meno che il loro nome inizi con _ (underscore).
Vengono inviati allo API Server in ordine alfabetico. Per indicare l'ordine, come trucco diamo ai nomi dei template un numero progressivo.
I PV e PVC gestiti da Helm sono delicati. Meglio avere un manifest che si occupa solo di loro.
tree wordpress
wordpress
├── charts
├── Chart.yaml
├── templates
│ ├── 01pvpvc-mysql.yaml
│ ├── 02mysql.yaml
│ ├── 03pvpvc-wpress.yaml
│ ├── 04wpress.yaml
│ └── tests
└── values.yaml
Elementi del Chart
Per prima cosa preparare le specifiche del chart:
vim wordpress/Chart.yaml
apiVersion: v2
name: wordpress
description: Wordpress app with MySQL backend
type: application
version: 0.1.0
appVersion: "1.0.0"
Inserire il primo template, della parte MySQL - namespace, PV e PVC:
vim wordpress/templates/01pvpvc-mysql.yaml
kind: Namespace
apiVersion: v1
metadata:
name: mysql-db
labels:
name: mysql-db
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv-volume
spec:
storageClassName: standard
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /data/my/
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: my-pv-claim
namespace: mysql-db
spec:
volumeName: my-pv-volume
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
Preparare il secondo template, della parte MySQL - secret, deployment e servizio:
vim wordpress/templates/02mysql.yaml
apiVersion: v1
kind: Secret
metadata:
namespace: mysql-db
name: mysql-pass
type: Opaque
data:
# secret
root-password: c2VjcmV0
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
namespace: mysql-db
labels:
app: wordpress
spec:
selector:
matchLabels:
app: wordpress
tier: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: wordpress
tier: mysql
spec:
containers:
- image: localhost:5000/mysql:5.6
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: root-password
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: my-pv-claim
---
apiVersion: v1
kind: Service
metadata:
name: mysql
namespace: mysql-db
labels:
app: wordpress
spec:
type: LoadBalancer
ports:
- protocol: TCP
port: 3306
targetPort: 3306
selector:
app: wordpress
tier: mysql
La terza è la parte WordPress - PV e PVC:
vim wordpress/templates/03pvpvc-wpress.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv-volume
spec:
storageClassName: standard
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /data/wp/
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pv-claim
spec:
volumeName: wp-pv-volume
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
La quarta è la parte Wordpress - secret, deployment e servizio:
vim wordpress/templates/04wpress.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysql-pass
type: Opaque
data:
root-password: c2VjcmV0
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
spec:
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: Recreate
template:
metadata:
labels:
app: wordpress
tier: frontend
spec:
containers:
- image: localhost:5000/wordpress:4.8-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: mysql.mysql-db
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: root-password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
---
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
spec:
type: LoadBalancer
ports:
- port: 8080
targetPort: 80
selector:
app: wordpress
tier: frontend
Installazione del Chart
Con questi elementi dovremmo essere subito in grado di installare il chart:
helm install myword wordpress
NAME: myword
LAST DEPLOYED: Tue Feb 27 17:01:51 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
Verifichiamo gli oggetti nello spazio di default:
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/wordpress-5cdb8f4c8f-ghbs5 1/1 Running 0 74s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 22h
service/wordpress LoadBalancer 10.96.5.6 172.18.255.201 8080:31037/TCP 76s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/wordpress 1/1 1 1 75s
NAME DESIRED CURRENT READY AGE
replicaset.apps/wordpress-5cdb8f4c8f 1 1 1 75s
Verifichiamo gli oggetti nello spazio nomi `mysql-db``:
kubectl get all -n mysql-db
NAME READY STATUS RESTARTS AGE
pod/mysql-5d5db54ccd-fpmhh 1/1 Running 0 3m38s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/mysql LoadBalancer 10.96.149.15 172.18.255.200 3306:30001/TCP 3m39s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/mysql 1/1 1 1 3m38s
NAME DESIRED CURRENT READY AGE
replicaset.apps/mysql-5d5db54ccd 1 1 1 3m38s
Verifichiamo i PV:
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
my-pv-volume 20Gi RWO Retain Bound mysql-db/my-pv-claim standard 5m49s
wp-pv-volume 5Gi RWO Retain Bound default/wp-pv-claim standard 5m49s
I PVC nello spazio nomi di default:
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
wp-pv-claim Bound wp-pv-volume 5Gi RWO standard 7m24s
I PVC nello spazio nomi mysql-db:
kubectl get pvc -n mysql-db
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
my-pv-claim Bound my-pv-volume 20Gi RWO standard 8m57s
Tutto è presente.
Listiamo il chart installato:
helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
myword default 1 2024-02-27 17:01:51.254489827 +0100 CET deployed wordpress-0.1.0 1.0.0
Proviamo il collegamento con un browser a 172.18.255.201:8080.
Vediamo l'accesso a WordPress.
Sembra funzionare.
Possiamo disinstallare il chart:
helm uninstall myword
Verifichiamo poi che tutti gli elementi dell'applicativo siano stati tolti.
Pacchettizzazione
Pacchettizziamo ora il chart:
helm package wordpress
Questo genera il file di package wordpress-0.1.0.tgz.
Lo potremo porre nel nostro repository personale quando ne avremo uno.
Il chart pacchettizzato è anche scaricabile al link wordpress-0.1.0.tgz.
Note
Il nostro chart non è per niente parametrico: non usa il linguaggi di templating. E' puramente un primo esercizio dimostrativo.
Volendo parte ora una lunga sequenza di Refactoring a passi successivi: a ciacun passo aggiungiamo un cero grado di parametrizzazione.
Diviene utile usare un ambiente di Controllo Versione, come Git, e un chain di CD/CI.
Ma questo è fuori dallo scopo del corso.
Templati
La specifica sintassi dei templati proviene dalla libreria standard dei templati del linguaggio Go, in cui Helm è scritto.
La stessa sintassi si usa anche in kubectl, Hugo e tanti altri applicativi scritti in Go.
Non è però necessario conoscere il linguaggio Go per usarla (anche se è un linguaggio di programmazione moderno, performante e bello da usare).
Azioni
Lo switch dentro il templating engine avviene quando si incontrano due graffe aperte, {{. Lo switch fuori dal templating engine avviene quando si incontrano due graffe chiuse, }}.
Ciò che si trova entro le graffe sono azioni, e possono essere comandi, strutture dati, costrutti di controllo, sottotemplati o funzioni.
Un trattino, -, prima o dopo le graffe, separato con spazio dal contenuto, sopprime spazi nel testo risultante. Per esempio:
{{ "Hello" -}} , {{- "World" }}
genera
Hello,World
Informazioni Esterne
Informazioni acquisite nel templating engine dall'ambiente esterno sono rappresentate come .Nome, oppure .Nome,nome oppure .Nome.nome.nome, ecc.
Tutte le informazioni iniziano col carattere punto, ..
Per motivi derivanti da Go il primo Nome deve essere con iniziale maiuscola. In Go i simboli che iniziano con la maiuscola sono di visibilità pubblica, non privata.
La struttura è gerarchica e il separatore di gerarchia è il carattere punto, .. Corrispondono alla gerarchia presente nei files Yaml di specifica.
Le informazioni possono provenire dal file values.yaml, tantissimi parametri potenziali, e hanno il nome .Values.xxx.
Possono provenire da informazioni sulla release, col nome .Release.xxx:
.Release.Name.Release.Namespace.Release.IsInstall- .Release.IsUpgrade
.Release.Service- il servizio che genera la release, settato a "Helm" nel nostro caso
Possono provenire dal file Chart.yaml, col nome .Chart.xxx:
.Chart.Name.Chart.Version.Chart.AppVersion.Chart.Annotations- una lista di annotazioni in formatokey=value
Possono provenire da informazioni ricevute dal cluster Kubernetes, col nome .Capabilities.xxx:
.Capabilities.APIVersions.Capabilities.KubeVersion.Version.Capabilities.KubeVersion.Major.Capabilities.KubeVersion.Minor
Possono provenire da files dopo una direttiva di inclusione. col nome .Files.xxx.
Possono riferirsi al template in corso di processamento, col nome .Template.xxx:
.Template.Name.Template.BasePath
Pipelines e Tipi
Una pipeline è una sequenza di comandi, funzioni e variabili concatenati, separati dal simbolo di pipe |-
Il funzionamento è molto simile a quello standard di Unix/Linux: l'output del comando precedente la pipe è passato come input al comando seguente. Per esempio:
character: {{ .Values.character | default "Sylvester" | quote }}
Il valore del parametro .Values.character è passato alla funzione default. Questa lo controlla e se è la stringa vuota lo sostituisce con la stringa "Sylvester", quidi lo passa alla funzione quote. Tale funzione racchiude la stringa tra doppi apici.
Attenzione nella specifica di parametri, poichè il linguaggio sottostante Go è fortemente tipizzato e le funzioni lavorano solo su tipi prestabiliti.
Per esempio se .Values.character vale 127, questo è un numero intero; se vale ab112 può venir interpretato come intero esadecimale. Solo se vale "ab112" è una stringa.
Non scordarsi i doppi apici per i valori stringa nei vari files sottoposti al templating engine.
Funzioni
Le funzioni provengono dalla libreria Go chiamata Sprig, e mantenuta a https://github.com/Masterminds/sprig. Sono più di 100.
La documentazione delle funzioni è a https://helm.sh/docs/chart_template_guide/function_list/.
Esempio:
{{- toYaml .Values.podSecurityContext | nindent 8 }}
- viene preso il parametro
podSecurityContextdal filevalues.yaml(o passato tramite l'opzione--set) - vengono tolti eventuali spazi all'inizio, dalla funzione
- - la stringa risultante viene convertita a formato Yaml, dalla funzione
toYaml - la funzione
nindentindenta la stringa di 8 spazi
Go ha tre tipi di collezioni semplici: array (liste immutabili), slice (liste mutabili) e maps (coppie chiave-valore).
Se la funzione nindent riceve in input una collezione, opera su ogni elemento della collezione su nuova riga.
Metodi
In Go un metodo è una funzione che si applica ad un certo tipo di oggetto.
La notazione è (oggetto).metodo.
Se oggetto è una collezione, metodo si applica ad ogni suo elemento.
Vi sono le funzioni:
.Files.Get name- ritorna il contenuto del file il cui nome èname, espresso come percorso relativo alla directory radice del chart. Il contenuto è una slice di caratteri, quella che si chiamerebbe una stringa..Files.GetBytes name- ritorna il contenuto del file il cui nome èname, espresso come percorso relativo alla directory radice del chart. Il contenuto è una slice di byte, espressa in Go come[]byte.Files.Glob pattern- ritorna il contenuto dei file conformi allo schemapattern, come stringa (slice di caratteri). Nel pattern si usano gli stessi simboli?e*della shell di Unix.
Go tratta normalmente le stringhe usando la codifica Unicode UTF-8. Ciò vuol dire che ogni carattere (in Go chiamato runa) è potenzialmente rappresentato da più bytes. Il Go ha corrispondentemente funzioni che operano su stringhe (lunghezza, sottostringhe, ecc.) e funzioni che operano su bytes (JSON, Base64, ecc.).
Queste tre funzioni soprs ritornano collezioni.
Vi sono dei metodi che si applicano alle collezioni risultanti:
.Files.AsConfig- trasforma l'input per renderlo compatibile ad un manifest di ConfigMap.Files.AsSecrets- trasforma l'input per renderlo compatibile ad un manifest di Secrets, codificato Base64.Files.Lines- ritorna il contenuto dell'input come array, compiendo uno split degli elementi col carattere\n
Esempio. La stringa di template:
{{ (.Files.Glob "config/*").AsSecrets | indent 2 }}
potrebbe generare:
jetpack.ini: ZW5hYmxlZCA9IHRydWU=
rocket.yaml: ZW5hYmxlZDogdHJ1ZQ==
Funzione lookup
Compie una query al cluster Kubernetes alla ricerca di risorse.
Per esempio il seguente ricerca un D chiamato runner nel namespace anvil, e ne ritorna le annotazioni nella sezione metadati:
{{ (lookup "apps/v1" "Deployment" "anvil" "runner").metadata.annotations }}
Gli argomenti di lookup sono:
- versione API
- tipo di oggetto
- namespace
- nome dell'oggetto
Nell'esempio seguente viene ritornata la lista di tutti i ConfigMap nel namespace anvil:
{{ (lookup "v1" "ConfigMap" "anvil" "").items }}
La lista è iterabile in un loop.
Naturalmente lookup non funziona in un Dry Run o col comando helm template quando non viene contattato il server Kubernetes.
Costrutto if/else
Con solo la branca if:
{{- if .Values.ingress.enabled -}}
...
{{- end }}
Con anche la branca else:
{{- if .Values.ingress.enabled -}}
...
{{- else -}}
# Ingress not enabled
{{- end }}
and e or
Non sono operatori, ma funzioni che prendono i due argomenti da paragonare.
Esempi:
{{- if and .Values.characters .Values.products -}}
...
{{- end }}
{{- if or (eq .Values.character "Wile E. Coyote") .Values.products -}}
...
{{- end }}
Costrutto with
Simile ad un foreach di altri linguaggi.
Esempio:
{{- with .Values.ingress.annotations }}
annotations:
{{- toYaml . | nindent 4 }}
{{- end }}
Se ad un'iterazione l'argomento corrente del with è vuoto, il blocco viene saltato e si passa all'argomento successivo.
Variabili
Si possono creare delle variabili. Il loro nome inizia col carattere $.
Hanno un tipo, che è dedotto in fase di assegnazione dal tipo del valore.
L'operatore di creazione ed assegnazione - la prima volta - è :=.
Il cambiamento di valore quando la variabile esiste già è =.
Esempi:
{{ $var := .Values.character }}
{{ $var = "Tweety" }}
Lo scopo delle variabili è il templato in cui vivono, dal punto di assegnazione in avanti.
Il riferimento ad una variabile che non esiste è un errore.
Costrutto range
Opera in loop su una collezione, che può essere una lista o ona map (anche chiamata un dict).
Esempio:
Date le collezioni:
# An example list in YAML
characters:
- Sylvester
- Tweety
- Road Runner
- Wile E. Coyote
# An example map in YAML
products:
anvil: They ring like a bell
grease: 50% slippery
boomerang: Guaranteed to return
Iterando sulla lista si può avere:
characters:
{{- range .Values.characters }}
- {{ . | quote }}
{{- end }}
che fornisce in output:
characters:
- "Sylvester"
- "Tweety"
- "Road Runner"
- "Wile E. Coyote"
Il punto, ., è l'argomento corrente del loop di range.
Iterando sul dict si può avere:
products:
{{- range $key, $value := .Values.products }}
- {{ $key }}: {{ $value | quote }}
{{- end }}
che produce in output:
products:
- anvil: "They ring like a bell"
- boomerang: "Guaranteed to return"
- grease: "50% slippery"
$key e $value sono variabili predefinite per l'utilizzo di dict.
Notare che, derivato dal Go, è possibile la doppia assegnazione: $key, $value := .Values.products.
Template con Nome
E' possibile definire un template dandogli un nome, e così richiamarlo da un altro template.
Esempio.
{{/*
Selector labels
*/}}
{{- define "anvil.selectorLabels" -}}
app.kubernetes.io/name: {{ include "anvil.name" . }}
app.kubernetes.io/instance: {{ .Release.Name }}
{{- end -}}
{{/* ... */}}racchiudono un commento{{- define "anvil.selectorLabels" -}}è il nome che si da al template corrente. Può essere un nome gerarchico, separato da., e questo è utile per evitare collizioni di nomi- segue il corpo del template
{{- end -}}termina la definizione di template
include
Richiama un template specificato, includendolo in quello corrente.
Esempio:
{{- include "anvil.selectorLabels" . | nindent 8 }}
- il primo argomento è il nome del template chiamato
- il secondo argomento è un oggetto da passare al template. Il carattere
.indica l'oggetto globale, cioè tutti gli oggetti che sono in scopo al punto della chiamata. E' l'uso più comune. - l'output del template richiamato è eventualmente, come qui, passato alla pipeline
Refactoring del Chart
Organizzazione
Vogliamo incrementalmente migliorare il chart prodotto, introducendo della parametrizzazione.
Il controllo versioni che usiamo è elementare:
cp -rf wordpress wordpress.1
- salviamo la versione stabile corrente in
wordpress.1- poi sarà
wordpress.2,wordpress.3, ecc.
- poi sarà
- modifichiamo
wordpress - rimaniamo sempre posizionati nella directory corrente, dando percorsi relativi
Generiamo anche un chart anvil, quello di esempio standard, da cui trarre spunto:
helm create anvil
Il file di templati viene copiato:
cp anvil/templates/_helpers.tpl wordpress/templates
OIn tale file, ogni occorrenza della stringa anvil deve essere sostituita con wordpress.
Il file wordpress/values.yaml invece lo generiamo passo a passo.
Note
Il chart di esempio presume che il nostro applicativo abbia un solo servizio, invece ne ha due: mysql e wordpress.
Ma possiamo considerare wordpress come servizio primario.
Prima Iterazione: Note per l'Utente
NOTES.txt
Copiamo il file dall'esempio standard e modifichiamolo:
cp anvil/templates/NOTES.txt wordpress/templates
Ogni occorrenza della stringa anvil deve essere sostituita con wordpress.
Per risolvere i riferimenti .Values del file editiamo e inseriamone i valori in values.yaml:
vim wordpress/values.yaml
service:
type: LoadBalancer
port: 8080
ingress:
enabled: false
Occorre anche editare il Manifest del service di wordpress:
vim wordpress/templates/04wpress.yaml
E cambiare la sezione Service in :
apiVersion: v1
kind: Service
metadata:
name: {{ include "wordpress.fullname" . }}
labels:
app: wordpress
spec:
type: {{ .Values.service.type }}
ports:
- port: {{ .Values.service.port }}
targetPort: 80
selector:
app: wordpress
tier: frontend
Installazione e prova:
helm install myword wordpress
Escono i NOTES.
I comandi shell suggeriti funzionano:
export SERVICE_IP=$(kubectl get svc --namespace default myword-wordpress --template "{{ range (index .status.loadBalancer.ingress 0) }}{{.}}{{ end }}")
echo http://$SERVICE_IP:8080
http://172.18.255.201:8080
Diamo il comando di verifica:
kubectl get services
Notiamo che il servizio si chiama ora myword-wordpress e non semplicemente wordpress.
Apriamo un browser a http://172.18.255.201:8080 per verificare se funziona.
Oggetti Built-in
Helm ha una serie di oggetti predefiniti, come ad esempio {{ .Release.Name }} che abbiamo visto in NOTES.txt.
Sezione Release:
Release.NameRelease.NamespaceRelease.IsUpgradeRelease.IsInstallRelease.RevisionRelease.Service- sempre Helm
Sezione Values: oggetti definiti in values.yaml secondo la gerarchia Yaml e con notazione punto.
Sezione Chart: oggetti definiti in Chart.yaml secondo la gerarchia Yaml e con notazione punto.
Sezione Capabilities:
Capabilities.APIVersions- insieme di versioniCapabilities.APIVersions.Has $version- indica se la versione$versionè disponibileCapabilities.KubeVersion- di KubernetesCapabilities.KubeVersion.MajorCapabilities.KubeVersion.MinorCapabilities.HelmVersionCapabilities.HelmVersion.GoVersion- versione del compilatore Go usata
Sezione Template:
Template.Name- il nome completo del Template corrente, incluso il percorsoTemplate.BasePath- solo il nome del Template corrente
Ha inoltre una serie di funzioni di gestione dei file:
Files.Get- ritorna il contenuto del file specificato come caratteri UTF-8 (rune in Go)Files.GetBytes- ritorna il contenuto del file specificato come array di bytesFiles.Glob- ritorna una lista di files specificata da caratteri jollyFiles.Lines- ritorna un file linea per linea, utile nelle iterazioniFiles.AsSecrets- ritorna il contenuto di un file codificato in Base64Files.AsConfig- ritorna un file codificato come mappa Yaml
NOTA
Una piccola guida all'arte di scrivere templati in Helm si trova a
https://helm.sh/docs/chart_template_guide/La documentazione generale è a
https://helm.sh/docs/
Helm Starters
Uno Starter è simile ad uno Helm Chart ma serve come template di nuovi charts.
In uno Starter tutte le occorrenze esplicite del nome del chart in tutti i files, sono sostituite dalla stringa <CHARTNAME>. Questa viene attualizzata al nome specifico del chart quando il chart viene creato sulla base dello Starter.
Creazione di uno Starter
Per creare uno Starter di nome wpstart a partire dal nostro chart wordpress possiamo procedere come segue.
Copiamo tutti i file di wordpress nella nuova directory wpstart:
cp -rf wordpress wpstart
Modifichiamo tutte le occorrenze della sringa wordpress con <CHARTNAME> in tutti i file:
cd wpstart
find . -type f -exec sed -i 's/wordpress/<CHARTNAME>/g' {} \;
cd ..
Lo starter è pronto.
Uso dello Starter
Creiamo un chart mxwp a partire dallo starter wpstart:
helm create --starter wpstart mxwp
La directory wpstart è anch'essa sotto la directory corrente.
Possiamo ispezionare i fles di mxwp per verificare che cntengono il nome del chart corrente.
Solitamente gli Starter più usati vengono posti in una directory dell'ambiente di Helm, $HELM_DATA_HOME/starters. Questa directory può ancora non esistere.
mkdir -p ~/.local/share/helm/starters
cp -rv wpstart ~/.local/share/helm/starters
Ora si può creare un chart basato sullo Starter da ovunque nel filesystem:
helm create -p wpstart mywp
Charts Complessi
Dipendenze
Un chart può dipendere da altri chart.
Dipendenza lasca
Corrisponde ad un'installazione manuale del chart dipendente nella directory charts.
Dipendenza stretta
Formalizza la dipendenza e la gestisce tramite comandi Helm.
Le dipendenze sono specificate nel file Chart.yaml.
Esempio:
dependencies:
- name: booster
version: ^1.0.0
repository: https://raw.githubusercontent.com/Masterminds/learning-helm/main/chapter6/repository/
Per la versione si usa comunemente un range espresso da simboli.
La notazione è la corrente:
| Sintassi | Equivalente a |
|---|---|
| ^1.2.3 | >= 1.2.3 < 2.0.0 |
| ^1.2.x | >= 1.2.0 < 2.0.0 |
| ^2.3 | >= 2.3 < 3 |
| ^2.x | >= 2.0.0 < 3 |
| ^0.2.3 | to >= 0.2.3 < 0.3.0 |
| ^0.2 | >= 0.2.0 < 0.3.0 |
| ^0.0.3 | to >= 0.0.3 < 0.0.4 |
| ^0.0 | >= 0.0.0 < 0.1.0 |
| ^0 | = 0.0.0 < 1.0.0 |
| ~1.2.3 | to >= 1.2.3 < 1.3.0 |
| ~1 | = 1 < 2 |
| ~2.3 | >= 2.3 < 2.4 |
| ~1.2.x | to >= 1.2.0 < 1.3.0 |
| ~1.x | >= 1 < 2 |
Il repository può essere:
- una URL
- un repository di Helm aggiunto con
helm repo add, prefissoda un@, p.es."@myrepo"
Update di Dipendenze
Col comando:
helm dependency update .
Si ottiene un risultato simile a:
Saving 1 charts
Downloading booster from repo https://raw.githubusercontent.com/Masterminds/learning-helm/main/chapter6/repository/
Deleting outdated charts
Durante l'update:
- Vieme generato il file
Chart.lock - la dipendenza viene copiata nells sottodirectory
charts
In luogo dell'argomento . (punto), si può passare come parametro un oggetto, ma non è quasi mai usato.
Dipendenze Condizionali
E' fornita dalla prorietà condition nella descrizione di dipendenza.
Per esempio nel file Charts.yaml:
dependencies:
- name: booster
version: ^1.0.0
condition: booster.enabled
repository: https://raw.githubusercontent.com/Masterminds/learning-helm/main/chapter6/repository/
Controllata dal file values.yaml
booster:
enabled: false
Importare Valori
A volte si desiderano importare valori da un chart dipendente (child) nel chart corrente (parent).
Proprietà exports
Esempio. Nel file values.yaml del child:
exports:
types:
foghorn: rooster
Nel file Charts.yaml del parent:
dependencies:
- name: example-child
version: ^1.0.0
repository: https://charts.example.com/
import-values:
- types
Questo è l'equivalente di aver settato, in values.yaml del parent:
foghorn: rooster
Import Diretto
Se il child ha nel file values.yaml:
types:
foghorn: rooster
Il parent ha nel file Charts.yaml:
dependencies:
- name: example-child
version: ^1.0.0
repository: https://charts.example.com/
import-values:
- child: types
parent: characters
Questo è l'equivalente di aver settato, in values.yaml del parent:
characters:
foghorn: rooster
Librerie di Charts
Le librerie di charts sono concettualmente simili a librerie software Forniscono funzionalità riusabili e sono importate da altri charts.
Le librerie di charts non sono esse stesse installabili.
Creazione di un Library Chart
- Creare un chart normalmente col comando
helm create - Rimuovere il file
values,yaml - Rimuovere il contenuto della directory
templates - Modificare il file
Chart.yamlinserendo il parametrotype: library
Per esempio:
apiVersion: v2
name: mylib
type: library
description: an example library chart
version: 0.1.0
I files implementativi della libreria si trovano nella directory templates e il loro nome inizia con _ (underscore). Helm non genera templates da nomi che iniziano con _.
Le loro estensioni sono .tpl o .yaml.
Un esempio può essere _configmap.yaml:
{{- define "mylib.configmap.tpl" -}}
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ include "mylib.fullname" . }}
labels:
{{- include "mylib.labels" . | nindent 4 }}
data: {}
{{- end -}}
{{- define "mylib.configmap" -}}
{{- template "mylib.util.merge" (append . "mylib.configmap.tpl") -}}
{{- end -}}
Il template mylib.util.merge deve essere altrove definito come:
{{- /*
mylib.util.merge will merge two YAML templates and output the result.
This takes an array of three values:
- the top context
- the template name of the overrides (destination)
- the template name of the base (source)
*/ -}}
{{- define "mylib.util.merge" -}}
{{- $top := first . -}}
{{- $overrides := fromYaml (include (index . 1) $top) | default (dict ) -}}
{{- $tpl := fromYaml (include (index . 2) $top) | default (dict ) -}}
{{- toYaml (merge $overrides $tpl) -}}
{{- end -}}
Il seguente esempio, da un chart mychart, illustra l'uso di questa funzione di libreria:
{{- include "mylib.configmap" (list . "mychart.configmap") -}}
{{- define "mychart.configmap" -}}
data:
myvalue: "Hello Bosko"
{{- end -}}
La prima linea include il template mylib.configmap dalla chart di libreria. L'argomento passato è una lista con l'oggetto corrente e il nome del template i cui contenuti compiranno un override di quelli del template di libreria.
L'output prodotto è:
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app.kubernetes.io/instance:example
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: mychart
helm.sh/chart: mychart-0.1.0
name: example-mychart
data:
myvalue: Hello Bosko
Schema per Values
E' possibile fornire uno schema per controllare con lint la validità del file values.yaml.
Il file di schema si chiama values.schema.json, nella directory principale del chart ove si trova anche values.yaml. ed è scritto in JSON.
Esempio. Se values.yaml è il seguente:
image:
repository: ghcr.io/masterminds/learning-helm/anvil-app
pullPolicy: IfNotPresent
tag: ""
Uno schema corrispondente potrebbe essere:
{
"$schema": "http://json-schema.org/schema#",
"type": "object",
"properties": {
"image": {
"type": "object",
"properties": {
"pullPolicy": {
"type": "string",
"enum": ["Always", "IfNotPresent"]
},
"repository": {
"type": "string"
},
"tag": {
"type": "string"
}
}
}
}
}
Esempio d'uso con un errore:
helm lint . --set image.pullPolicy=foo
Output prodotto:
==> Linting .
[ERROR] templates/: values don't meet the specifications of the schema(s) in the
following chart(s):
booster:
- image.pullPolicy: image.pullPolicy must be one of the following:
"Always", "IfNotPresent"
Error: 1 chart(s) linted, 1 chart(s) failed
Helm Hooks
Azioni compiute ad un certo stadio del ciclo di vita dell'oggetto Kubernetes.
Si specificano nella proprietà annotations e possono avere le seguenti chiavi:
"helm.sh/hook"- azione durante il ciclo di vita dell'oggetto. Vi possono essere più azioni, separate da virgola e senza spazi"helm.sh/hook-weight"- specifica l'annotazione precedente; deve sempre esseere un numero intero, positivo, negativo o zero (default), ma espresso come stringa. Helm sortizza gli hooks in ordine ascendente, dal più piccolo al più grande."helm.sh/hook-delete-policy"- se cancellare l'oggetto Kubernetes trattato relativamente allo hook
Gli hook possono essere:
| Nome | Quando viene eseguito |
|---|---|
| pre-install | prima dell'invio a Kubernetes |
| post-install | dopo l'invio a Kubernetes |
| pre-delete | prima della cancellazione |
| post-delete | dopo la cancellazione |
| pre-upgrade | durante un upgrade, prima dell'invio a Kubernetes |
| post-upgrade | durante un upgrade, dopo l'invio a Kubernetes |
| pre-rollback | prima di un rollback |
| post-rollback | dopo un rollback |
| test | durante il comando helm test |
Le policy di cancellazione, relative ad una risorsa di Kubernetes,possono essere:
| Policy | Descrizione |
|---|---|
| before-hook-creation | cancellata prima dello hook (default) |
| hook-succeeded | cancellata se lo hook ha avuto successo |
| hook-failed | cancellata se lo hook è fallito |
Esempio del templato di un pod con uno hook di tipo post-install:
apiVersion: v1
kind: Pod
metadata:
name: "{{ include "mychart.fullname" . }}-post-install"
labels:
{{- include "mychart.labels" . | nindent 4 }}
annotations:
"helm.sh/hook": post-install
"helm.sh/hook-weight": "-1"
"helm.sh/hook-delete-policy": before-hook-creation,hook-succeeded
spec:
containers:
- name: wget
image: busybox
command: ["/bin/sleep","{{ default "10" .Values.sleepTime }}"]
restartPolicy: Never
L'esecuzione degli hooks durante un comando Helm, può essere saltata con l'opzione --no-hooks.
Helm Test
Helm fornisce di serie il comando di linea helm test.
I templati di test risiedono nella directory del chart templates/tests.
Reinstalliamo il nostro chart d'esercizio:
helm install myapp anvil
Il templato di test è anvil/templates/tests/test-connection.yaml:
apiVersion: v1
kind: Pod
metadata:
name: "{{ include "anvil.fullname" . }}-test-connection"
labels:
{{- include "anvil.labels" . | nindent 4 }}
annotations:
"helm.sh/hook": test
spec:
containers:
- name: wget
image: busybox
command: ['wget']
args: ['{{ include "anvil.fullname" . }}:{{ .Values.service.port }}']
restartPolicy: Never
Che sia un test è specificato da:
annotations:
"helm.sh/hook": test
Proviamo il test:
helm test myapp
NAME: myapp
LAST DEPLOYED: Thu Feb 15 12:07:55 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: myapp-anvil-test-connection
Last Started: Thu Feb 15 12:08:31 2024
Last Completed: Thu Feb 15 12:08:58 2024
Phase: Succeeded
NOTES:
.....
Gestione di Repositories
I charts sviluppati in casa devono essere storati in un Chart Repository per la distribuzione a terze parti.
Lo scenario più comune è un progetto aziendale, quindi i charts devono essere su repository privati.
Vi sono varie soluzioni:
- Installare un web server tradizionale e adattarlo a Chart Repository. Esempi tipici: Apache, Nginx.
- Sviluppare un semplice web server con un linguaggio di programmazione come Python o Go. Avrà delle limitazioni.
- Usare un'offerta commerciale di un Provider, sicuramente a pagamento.
- Usare GitHub Pages. Solo i repository pubblici sono gratis, quelli privati sono a pagamento.
- Usare un prodotto Open Source specifico che offre un Chart Repository
Standard OCI
UCI sta per Open Container Initiative, ed è una struttura aperta di governance per la determinazione di standard aperti, tesi alla gestione di formati di container e ambienti runtime.
Nelle specifiche OCI vi è anche la specifica di distribuzione, una API per la distribuzione di immagini di contenitori, charts di Helm e simili.
A partire da Helm 3.0 è stato aggiunto un supporto per il push e il pull di charts da un registry OCI.
ChartMuseum

E' un progetto Open Source disponibile a https://github.com/helm/chartmuseum.
E' uno Helm Chart Repository scritto in linguaggio Go.
Oltre che storaggio locale, supporta molti tipi di storaggio forniti da Cloud Provider, inclusi Google Cloud Storage, Amazon S3, Microsoft Azure Blob Storage, Alibaba Cloud OSS Storage, Openstack Object Storage, Oracle Cloud Infrastructure Object Storage, Baidu Cloud BOS Storage, Tencent Cloud Object Storage, DigitalOcean Spaces, Minio, ed etcd.
Installazione
curl https://raw.githubusercontent.com/helm/chartmuseum/main/scripts/get-chartmuseum | bash
Preparare una directory che corrisponderà alla rootdir dello storaggio di chartmuseum:
mkdir ~/helmrepo
Lanciare chartmuseum:
chartmuseum --storage local --storage-local-rootdir ~/helmrepo --port 8123
Abbiamo specificato la porta 8123 per evitare collisioni con altri servizi su porte più comuni.
Blocca la finestra corrente.
I comandi seguenti vanno in un'altra finestra.
ChartMuseum in Docker
Sy può istanziare un'immagine Docker, per esempio:
docker run --rm -it \
-p 8123:8080 \
-e DEBUG=1 \
-e STORAGE=local \
-e STORAGE_LOCAL_ROOTDIR=/charts \
-v $(pwd)/charts:/charts \
ghcr.io/helm/chartmuseum:v0.14.0
Nello host mapping la directory locale $(pwd)/charts deve avere i permessi di lettura e scrittura per chi esegue i comandi rivolti a ChartMuseum.
Preparazione di ChartMuseum
Occorre generare un primo chart e trasferirlo a chartmuseum per generare un primo index.
cd /tmp
helm create mychart
helm package mychart
Trasferimento al repository ChartMuseum:
curl --data-binary "@mychart-0.1.0.tgz" http://localhost:8123/api/charts
Ora possiamo usare il repository chartmuseum:
helm repo add chartmuseum http://localhost:8123
helm repo update
helm repo list
Quando si usano chart repositories, meglio usarne uno per volta.
Listare i repositories:
helm repo list
E rimuovere quelli che non vogliamo, per esempio:
helm repo remove bitnami
Ricerca di chart:
help search repo mychart
Per compiere il push a chartmuseum occorre installare un plugin:
helm plugin install https://github.com/chartmuseum/helm-push
Configurazione Complessa
Chartmuseum ammette molti parametri ed opzioni di configurazione, storabili in un file. Sono soprattutto necessari per interfacciare i servizi forniti da un Cloud Provider.
Per ulteriori informazioni si rimanda al sito web del progetto, su GitHub.
Upload di Chart
Avevamo precedentemente prodotto il Chart wordpress. Compiamone lo upload su Chartmuseum.
Charmuseum deve essere attivo e deve avere installato il plugin cm-push.
cd ~/scripts
helm cm-push wordpress/ chartmuseum
helm repo update
Fatto.
Listare i charts disponibili su Chartmuseum, e tutti gli altri repositories configurati:
helm search repo
HashiCorp Vault
Lo storaggio e l'uso di Secrets, che sono solo trascodificati Base64, è un potenziale problema di sicurezza.
Occorrerebbe accedere ai Secrets in modo più sicuro, autenticato e crittografato.
La ditta HashiCorp fornisce il prodotto Vault, un ambiente generico di storaggio ed accesso di informazioni private, incluso i Secrets di Kubernetes.
La versione Kubernetes del prodotto Vault è disponibile in versione base come chart di Helm.
Versioni più complete e complesse sono soggette a licenza e a pagamento.
Il seguente esempio illustra l'utilizzo di Vault per Kubernetes.
Installazione di Vault
Creare la directory di lavoro:
mkdir -p ~/vault
cd ~/vault
Aggiungere il repository helm della HashiCorp:
helm repo add hashicorp https://helm.releases.hashicorp.com
Compiere un upfate:
helm repo update
Ricercare i chart di Vault:
helm search repo hashicorp/vault
Generate un file di configurazione per Vault:
cat > helm-vault-raft-values.yml <<EOF
server:
affinity: ""
ha:
enabled: true
raft:
enabled: true
setNodeId: true
config: |
cluster_name = "vault-integrated-storage"
storage "raft" {
path = "/vault/data/"
}
listener "tcp" {
address = "[::]:8200"
cluster_address = "[::]:8201"
tls_disable = "true"
}
service_registration "kubernetes" {}
EOF
Installare il chart di Vault:
helm install vault hashicorp/vault --values helm-vault-raft-values.yml
Listare i pods:
kubectl get pods
Occorre un tempo anche considerevole perchè la situazione si stabilizzi. Il risultato finale è:
NAME READY STATUS RESTARTS AGE
vault-0 0/1 Running 0 2m12s
vault-1 0/1 Running 0 2m12s
vault-2 0/1 Running 0 2m12s
vault-agent-injector-56b65c5cd4-k7lbt 1/1 Running 0 2m13s
Configurazione di Vault
Inizializzare vault-0 con un key share e un key threshold:
kubectl exec vault-0 -- vault operator init \
-key-shares=1 \
-key-threshold=1 \
-format=json > cluster-keys.json
Il file cluster-keys.json contiene le chiavi di accesso.
Questo è solo un esempio, ed è un procedimento insicuro. Il file delle chiavi dovrebbe immediatamente essere crittografato.
Visualizzare la chiave di sblocco:
jq -r ".unseal_keys_b64[]" cluster-keys.json
Porla in una variabile:
VAULT_UNSEAL_KEY=$(jq -r ".unseal_keys_b64[]" cluster-keys.json)
Sbloccare il Vault sul pod vault-0:
kubectl exec vault-0 -- vault operator unseal $VAULT_UNSEAL_KEY
Unire vault-1 e vault-2 al cluster Raft.
kubectl exec -ti vault-1 -- vault operator raft join http://vault-0.vault-internal:8200
kubectl exec -ti vault-2 -- vault operator raft join http://vault-0.vault-internal:8200
Usare la chiave di sblocco, digitata a mano a richiesta, per sbloccare vault-1 e vault-2
kubectl exec -ti vault-1 -- vault operator unseal $VAULT_UNSEAL_KEY
kubectl exec -ti vault-2 -- vault operator unseal $VAULT_UNSEAL_KEY
Porre un Secret nel Vault
Visualizzare il root token:
jq -r ".root_token" cluster-keys.json
Collegarsi al pod vault-0:
kubectl exec --stdin=true --tty=true vault-0 -- /bin/sh
Login al Vault. Viene richiesto il root token:
vault login
Se ha successo, l'autenticazione è cached e non c'è più bisogno di compiere il login.
Abilitare il secrets engine di integrazione con Kubernetes:
vault secrets enable -path=secret kv-v2
Creare un Secret ad un dato percorso e porvi dei dati:
vault kv put secret/webapp/config username="static-user" password="static-password"
Verificare la registrazione del Secret:
vault kv get secret/webapp/config
Uscire da vault-0:
exit
Autenticazione da Kubernetes
Vault fornisce un metodo di autenticazione Kubernetes che permette ai client di autenticarsi con un Service Account Token di Kubernetes.
Collegarsi al pod vault-0:
kubectl exec --stdin=true --tty=true vault-0 -- /bin/sh
Abilitare l'autenticazione Kubernetes:
vault auth enable kubernetes
Configurare che il metodo di autenticazione Kubernetes usi la locazione dell'API Kubernetes:
vault write auth/kubernetes/config \
kubernetes_host="https://$KUBERNETES_PORT_443_TCP_ADDR:443"
Scrivere una policy di nome webapp che dia la possibilità read dei Secret al percorso secret/data/webapp/config.
vault policy write webapp - <<EOF
path "secret/data/webapp/config" {
capabilities = ["read"]
}
EOF
Creare un Role chiamato webapp che connette il service account name vault di Kubernetes alla policy webapp:
vault write auth/kubernetes/role/webapp \
bound_service_account_names=vault \
bound_service_account_namespaces=default \
policies=webapp \
ttl=24h
Uscire dal pod vault-0:
exit
Applicativo che Usa il Vault
Deployment
Creare il deployment di un applicativo con il manifest deployment-01-webapp.yml:
vim deployment-01-webapp.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: webapp
labels:
app: webapp
spec:
replicas: 1
selector:
matchLabels:
app: webapp
template:
metadata:
labels:
app: webapp
spec:
serviceAccountName: vault
containers:
- name: app
image: hashieducation/simple-vault-client:latest
imagePullPolicy: Always
env:
- name: VAULT_ADDR
value: 'http://vault:8200'
- name: JWT_PATH
value: '/var/run/secrets/kubernetes.io/serviceaccount/token'
- name: SERVICE_PORT
value: '8080'
VAULT_ADDR- indirizzo del servizio di VAULTJWT_PATH- setta il percorso del JSON Web Token fornito da KubernetesSERVICE_PORT- per le richieste HTTP in arrivo
Sottomettere il nostro manifest:
kubectl apply --filename deployment-01-webapp.yml
Test
In un altro terminale compiere il port forward di tutte le richieste compiute a `` alla porta 80 del pod della webapp.
kubectl port-forward \
$(kubectl get pod -l app=webapp -o jsonpath="{.items[0].metadata.name}") \
8888:8080
Usiamo la porta 8888 per evitare collisioni con la porta 8080, possibilmente già in uso.
Nel terminale originale provare il collegamento:
curl http://localhost:8888
password:static-password username:static-user
Cosa Succede
L'applicativo che gira alla porta 8080 del pod webapp:
- si autentica con il token del service account di Kubernetes
- riceve un token da Vault che gli permette di leggere il percorso
secret/data/webapp/config path - recupera il Secret dal percorso
secret/data/webapp/config - ne compie il display in formato JSON
Pulizia Finale
Al termine compiere pulizia dell'esercizio.
Interrompere il Port Forwarding
Rimuovere l'applicativo tramite il suo Manifest
Disinstallare il chart di Vault
Questo ne rimuove tutti i pod e naturalmente i dati di configurazione e i Secrets storati vanno persi.
Ulteriori Possibilità
- Settare Vault con storaggio integrato nel Google Kubernetes Engine.
- Usare Annotations nell'applicativo per interagire con il servizio Vault Injector.
- Persistere i dati di Vault su volumi.
- Usare il servizio Vault fornito dalla stessa HashiCorp, a licenza.
Ulteriori dettagli documentativi si trovano sul sito Vault della Hashicorp.