Introduzione

Linux è il diretto discendente del mitico Unix.
80+ % dei server di rete mondiali sono basati su Linux.
Questa documentazione intende presentare l'utilizzo pratico di Linux da parte di un utente relativamente inesperto, e che intenda progredire a diventare un amministratore di sistema.
Licenza

La presente documentazione è distribuita secondo i termini della GNU Free Documentation License Versione 1.3, 3 novembre 2008.
Ne è garantita assoluta libertà di copia, ridistribuzione e modifica, sia a scopi commerciali che non.
L'autore detiene il credito per il lavoro originale ma nè credito nè responsabilità per le modifiche.
Qualsiasi lavoro derivato deve essere conforme a questa stessa licenza.
Il testo pieno della licenza è a: https://www.gnu.org/licenses/fdl.txt
Prefazione
Una persona è confrontata con la vecchiaia anche quando si rende conto che la maggior parte delle nozioni e informazioni storiche su Unix e Linux non le ha carpite o imparate dai libri, ma dalla pratica, quando sono uscite.
Non che io fossi là nei mitici tempi dei Laboratori Bell, ma già nei miei primi lavori, all'inizio degli anni '80, mi sono confrontato con versioni Unix per piccoli sistemi, coma Venix, o PC/IX, o il mitico Minix.
Tre floppies da 360kb solo per compiere il boot. Un'interfaccia di comandi così amichevole da far rimpiangere subito il DOS.
E tutti dicevano che Unix non era una cosa seria, che solo il mainframe IBM offriva possibilità di lavoro, al limite il nuovo e promettente PC AT, con ben 10 MB di disco.
E che il linguaggio del futuro era il Cobol, naturalmente.
Nei miei più di 20 anni all'Olivetti mi sono occupato della formazione sulle 'nostre' versioni di Unix, per server dipartimentali: per server M80 e M90 prima, poi per la serie LSX3000 ed LSX5000, l'ultimo con una variante nostra di Unix System V. Era tutto prodotto al laboratorio Olivetti di Cernusco sul Naviglio, con sorgenti liberamente scopiazzate dalla versione BSD proveniente dai nostri laboratori di Cupertino.
Nei primi anni '90 ero inviso, un po' deriso, per la mia posizione evangelica nei confronti del nuovo GNU/Linux, quello che ci voleva un giorno a ricompilare il kernel per calibrarlo alle proprie necessità, e una settimana per far andare l'interfaccia video con la propria scheda grafica.
Il 'sistema operativo' era Windows NT, certo, ma ricordo un paio di progetti di successo in cui abbiamo segretamente sostituito NT, che si schiantava in continuazione, con Red Hat 5.2. Il cliente era entusiasta delle performance, e ,ignaro,lodava la Microsoft.
Ora Unix è morto, ma Linux si è affermato come il sistema per datacenters. e per workstations, e per personal, e come base per Android e piattaforme Real Time, e mille altre soluzioni.
E' con amore e nostalgia che provo a scrivere il manuale seguente, ricordando che Unix non è solo un prodotto, ma una filosofia di produrre software di qualità e bellezza.
Non essendo un Guru, qualsiasi errore od omissione nelle pagine seguenti è interamente responsabilità mia.
| Michele Simioli, Firenze, 2024. |
La Sessione di Lavoro

L'utente si collega a UNIX/Linux per compiere operazioni:
- editare files
- dare comandi
- usare utilities
Per collegarsi l'utente passa attraverso la fase di Login, in cui deve autenticarsi con uno username (login name) e una password.
Se riconosciuto, dà inizio ad una sessione di lavoro, che può essere:
- a caratteri
- grafica
Al termine del lavoro si termina la connessione con l'operazione di Logout:
- comando
exita caratteri - opportuno bottone ocomando se in grafica
Il logout è assolutamente diverso dallo Shutdown, che compie uno spegnimento dell'intero sistema e per cui occorrono i permessi amministrativi.
Storia di Unix
La conoscenza della storia di UNIX, e di Linux che ne è derivato, è indispensabile per la comprensione di molti concetti che stanno alla base del sistema operativo.

Unix per se non esiste più.
I principali sistemi operativi discendenti di Unix sono:
- HP-UX (Hewlett Packard)
- AIX (IBM)
- Solaris (Oracle)
- MacOS X (Apple)
- Linux (varie distribuzioni)
- Windows (Mirosoft, molto modificato)
Alcuni sistemi Unix necessitano di hardware proprietario (HP-UX. AIX, MacOS X).
Altri sono disponibili anche per PC (Solaris, Linux).
Nasce Unix

Laboratori Bell della AT&T nel New Jersey, 1969:
- Ken Thompson è esperto di MULTICS, sistema operativo ipotetico mai terminato, che doveva fare di tutto (male)
- Per usare un Digital PDP-7 e giocare, scrive in assembler il sistema operativo UNICS, che fa una cosa bene (giocare)

- Arriva il nuovo DEC PDP-8 e Dennis Ritchie lo aiuta a riscrivere il sistema operativo in Linguaggio C
- Il nuovo sistema è rinominato UNIX

- Per giustificarne l'esistenza, Joe Ossana scrive il software di editazione Documentor's Workbench
- Si evolve internamente alla AT&T per numerose versioni
Unix si evolve
- 1980: Thompson si trasferisce a Berkeley e porta con sè Unix – nasce lo Unix System Support Group e la Berkeley Standard Distribution
- 1981: La AT&T adotta Unix per i propri sistemi 3B, con licenza d'uso, e lo chiama The UNIX System
- 1981: La AT&T cita a giudizio l'università di Berkeley per uso illegale di Unix. Il dissidio dura 12 anni.
- 1982 … : Si evolvono UNIX System III e System V
- 1985: Il marketing AT&T assicura che System V sarà la “final distribution”
- Le altre versioni si chiamano System V Release 2, ecc. - abbreviate SVR2, SVR3, SVR3.2, ecc.
- 1990: Esce UNIX System V Release 4
Unix wars

- 1990-93:
- AT&T e Sun Microsystem si alleano in un cartello e adottano SVR4. La Sun lo chiama Solaris
- IBM, Motorola, Digital, Microsoft e altre 150 ditte si alleano nella Open Software Foundation per contrastarli
- La Digital si incarica di produrre OSF/1, che terminerà nel 1993 come Digital Unix, poi rinominato Tru64 Unix
- Digital vende a Microsoft il suo Unix incompleto “Prism” e la Microsoft lo adatta come Windows NT
- AT&T, Sun e altre 120 ditte formano Unix International per contrastare la OSF
- Molte ditte vendor cambiano campo tra UI e OSF a seconda delle alterne fortune
- 1993: Prima chiude le operazioni Unix International, poi piano piano termina anche la Open Software Foundation
Unix è morto, Viva Unix
- 1993: L'università di Berkeley taglia i fondi allo USSG e chiude BSD
- 1993: I laboratori Bell vengono acquistati dalla Novell, che licenzia quasi tutti Il nuovo Unix della Novell si chiama UnixWare ed è concepito come client NetWare
- 1996: Incapace di mantenerlo, la Novell cede il codice UnixWare alla Santa Cruz Operations e Hewlett Packard
- Il marchio è ceduto allo Open Group per impedire speculazioni
- Ogni UNIX proprietario viene a questo punto sviluppato separatamente
Free Unices
- Dall'ultima versione di Berkeley, 4.4BSD, nascono i progetti FreeBSD, OpenBSD e NetBS

- Il “guru” del software libero, Richard Stallman, inizia il progetto GNU (GNU's Not Unix) per la riscrittura di tutto il codice Uni in modo libero, soggetto a licenza Copyleft GPL (Gnu Public License)

- Andrew Tannenbaum (univ. Amsterdam) sviluppa Minix per PC, inteso come progetto universitario chiuso

- Linus Thorvalds “ruba” il kernel di Minix, lo riadatta chiamandolo Linux e lo dona ai newsgroup
- Nasce GNU/Linux
Distribuzioni di Linux

Linux non è controllato da un unico vendor, ma sviluppato da letteralmente decine di migliaia di contribuenti.
Non vi è un unico prodotto 'Linux' ma svariate 'distribuzioni'. La necessità di una distribuzione è data da:
- Necessità di integrazione di sistema
- Supporto fisico e metodo di installazione
- Amministrazione e supporto

Vi sono al momento più di 50 distribuzioni diverse.
Queste si possono però ricondurre a tre gruppi principali:
- Distribuzioni Enterprise
- Red Hat Enterprise Linux (RHEL)
- SuSE Linux Enterprise System (SLES)
- Distribuzioni Curate
- Slackware
- Distribuzioni Free and Libre
- Debian
- Ubuntu
Distribuzioni Enterprise
Nel primo gruppo abbiamo le distribuzioni enterprise, che hanno le seguenti proprietà:
- estremamente stabili
- soggette a licenza pagata, che però non copre il software, di per sè free, ma:
- gli aggiornamenti automatici
- il supporto
- la copertura assicurativa
- non proprio il sofware più moderno, ma garantito stabile
- un circuito di training e certificazioni
- software proprietario aggiuntivo per problemi aziendalicomuni
- ambiente di amministrazione integrato, esaustivo nel caso di SLES
- numero medio di pacchetti software, integratiperfettamente nella release e contenuti in un unico repository, accessibile anche offline (p.es.DVD)
Sia Red Hat Enterprise Linux che SuSE (System un Software Entwicklung) sono ottime soluzioni aziendali.
Distribuzioni Curate
Il secondo gruppo ha come capostipite Slackware, distribuzione storica dell'olandese Peter Volkerding, che al limite ha software ancora più stabile e meno innovativo delle distribuzioni enterprise.
Manca un ambiente unico di amministrazione, che viene compiuta editando a mano opportuni files. La flessibilità è elevatissima, ma viene richiesta una conoscenza pregressa dell'editor vi e della programmazione shell.
La filosofia d'uso è quella dello Unix originale:soprattutto da linea di comando, con configurazioni personalizzate e 'cucite a mano'.
Il numero di pacchetti software è ridotto, sono stati preselezionati i 'migliori', a giudizio del fondatore.
Non è assolutamente necessario essere 'on line' per installarli, cioè sono su un DVD.
Si dice che chi diventa esperto nell'amministrazione di Slackware non incontri difficoltà co nessun'altra distribuzione.
Slackware esiste in versione 'pura', ma da essa sono state derivate numerose altre distribuzioni, spesso con grafica molto innovativa ed effetti speciali, da 'nerd'.
Distribuzioni Free and Libre
Il capostipite del terzo gruppo, Debian, è una distribuzione cha all'origine voleva essere pura e politically correct: veniva accettato solo software Open Source con le licenze più estremiste. Per quanto lo scopo iniziale si sia traviato alquanto nel tempo,
Debian rimane la distribuzione di chi intende scegliere il proprio software in modo da non violare licenze o avere alcuna prospettiva di condizionamento.
L'amministrazione di Debian è sui generis e un po' 'marziana' per chi proviene da altre distribuzioni. Molto gettonato all'inizio dai nerds, Debian è ora um _meme_in calo.
Dalla Debian il multimiliardario sudafricano Mike Shuttleworth (è stato su una Soyuz russa a sue spese), ha ricavato Ubuntu. La parola Swahili non è esattamente traducibile ma dà la coonotazione di 'tutti insieme come esseri umani', e la promessa è quella di una distribuzione di qualità che sia perennemente libera e gratuita.
Per quanto le promesse di un miliardario non convincano subito tutti, Ubuntu ha ad oggi guadagnato la reputazione di ottima distribuzione, amichevole e in continuo miglioramento, destinata soprattutto ai desktop.
Ubuntu è gestita dalla ditta Canonical, di Mike, che però pare abbia lati uscuri in altri campi.
La sua interattività ed amministrazione ricordano alquanto il MacIntosh; il software disponibile è vasto e l'installazione è particolarmente facile. E' apprezzata soprattutto come piattaforma per lo sviluppo software, con una esperienza personale molto superiore a Windows.
Per quanto esista una variante 'Ubuntu Server' non è molto usata, perchè richiede licenza per assistenza e supporto, e non è della stessa calibratura di RHEL.
Il tentativo della Canonical di introdurre certificazioni non ha avuto molto successo.
In sintesi i server sono soprattutto gestiti in Red Hat Enterprise Linux, il desktop con Ubuntu.
Red Hat

Una delle prime distribuzioni di Linux degli anni '90, la Yellow Dog, si era presto costituita in enterprise in America col nome Red Hat. RH aveva ottime distribuzioni molto stabili e curate, con numerose innovazioni, come l'internazionalizzazione e la disponibilità per architetture diverse da Intel.
Famosa la sua distribuzione 5.2 della fine dei '90, in vera concorrenza come server con Windows NT 4.0. Ottime anche le release dalla 7.1 alla 7.3 dei primi anni 2000.
La release seguente, 8.0, non era però affatto buona; la correzione di evidenti bachi con la 8.0A ha introdotto vistose pecche aggiuntive. La sostituzione con la 9.0, poi 9.0A e 9.0B indicavano problemi di sviluppo interni del team di Red Hat.
Una ditta che usava la 8.0 ha sofferto una notevole perdita di dati conseguenti all'uso di Linux, e ha fatto causa alla Red Hat, vincendola con compensi milionari. La corte decretò che, nonostanta la release fosse gratuita, ciò non esimeva la ditta produttrice dalla responsabilità legale del software.
Come risultato la Red Hat terminò la propria distribuzione Linux nei primi anni 2000. Chi intendesse acquisire il proprio prodotto doveva ora acquisire la licenza, a pagamento, della corrente versione Red Hat Enterprise Linux 4.0, e con i proventi della release la Red Hat avrebbe finanziato la copertura assicurativa in caso di ultriori litigi legali.
RHEL è quindi passata da allora attraverso le release 4.x, 5.x, 6.x ed ora 7.x.
Ogni 'major' release è supportata per 10 anni e chi possiede la licenza ha diritto a tutti gli upgrade per la durata della licenza, ma solo per la distribuzione specifica. Poi occorre contrarre una nuova licenza. Dopo tutto nel mondo dell'IT, 10 anni rappresentano un'obsolescenza notevole.
Al momento la release 5 è scaduta da due anni, la 6 ha ancora poco più di un anno di vita, la 7 durerà fino al 2024.
L'uso continuativo di release non più aggiornate, patchate e supportate, per quanto praticamente possibile, espone l'utilizzatore a problemi notevoli di attacchi hacker (questo è vero anche per Windows, ove la 7 è scaduta). La Red Hat è particolarmente conscia e preoccupata dei problemi di sicurezza di rete.
La Red Hat ha notevolissime restrizioni d'uso e personalizzazione delle proprie release, proprio per mantenere al massimo il livello di sicurezza. Inoltre sono stati introdotti ambienti di sicurezza innovativi, come il Security Enhanced Linux (SELinux) della NSA, che sono obbligatori in America nelle pubbliche amministrazioni.
Derivati di Red Hat
Fedora

La decisione di terminare la release gratuita di Red Hat aveva causato il dispiacere della comunità mondiale di utilizzatori non corporate.
La Red Hat ha quindi favorito il fondare nel 200x della 'Fedora Core', gruppo legalmente senza liability secondo la legge americana, che ha preso in mano la successiva distribuzione di un Linux molto simile a RHEL, senza copertura assicurativa e senza supporto, destinato ai singoli utilizzatori e ai loro desktop.
Fedora è passato attraverso parecchie release, ed è stato spesso utilizzato da Red Hat come piattaforma di testing di accettabilità per innovazioni tecniche fino ad ambienti nuovi e rischiosi: se rifiutate o criticate dagli utilizzatori, esse sparivano; se giudicate favorevolmente erano successivamente incorporate in una release RHEL.
Fedora è palesemente indirizzato al desktop e il suo tuning di base presume limitate risorse di calcolo del PC. Sfortunatamente ha avuto un successo limitato perchè le esperienze Linux desktop di molte derivate dalla Slackware, e soprattutto di Ubuntu, sono palesemente maggiori.
CentOS

Il codice sorgente di Linux è per licenza Open Source, allo scopo di:
- consentire la verifica della qualità del codice
- assicurarsi che la compilazione generi proprio il prodotto che la Red Hat vende
Altre distribuzioni, come la Slackware, mettono il codice sorgente a disposizione sul proprio sito web. Red Hat non lo fa, ma lo rende comunque disponibile a enti di una certa consistenza giuridica.
Un gruppo, originariamente di universitari americani, ottiene regolarmente il codice Linux dalla Red Hat ad ogni minor release, lo ricompila e genera la distribuzione Community enterprise Operating System (CentOS).
Questa distribuzione è esattamente uguale alla corrispondente RHEL ma:
- sono stati sostituiti i logo Red Hat e cambiati gli schemi di colore
- non vi è assistenza, assicurazione o upgrade
Fondamenti Architettonici
Unix dal 1993 è descritto da un diagramma 'a cipolla' cioè a strati concentrici.
Gli strati sono:
- hardware
- kernel
- applicativi
Gli applicativi non possono gestire direttamente l'hardware ma richiedono al kernel di farlo tramite delle funzioni, in linguaggio C, chiamate system calls.
Queste corrispondono a quello che in Windows si chiamano le API di Sistema (Application Programming Interface). Sono implementate da tre (minimo) librerie dinamiche, che sono sempre linkate a tutti i programmi che devono funzionare in Linux.
E' da notare che sono in linguaggio C, a basso livello, non in C++ come in Windows o Mac. Per generare degli applicativi scritti in C che vivano da 'buoni cittadini' in ambiente Linux, non basta una conoscenza di base del linguaggio, ma la padronanza di skill e conoscenze appropriate.
Il kernel gestisce l'hardware tramite moduli detti device drivers, anch'essi in linguaggio C. Il kernel stesso è scritto in C, con un minimo di routines a bassissimo livello in Assembler, per massimizzare l'efficienza di codice chiamato molto spesso.
Il kernel ha quindi tre funzioni:
- processi del kernel, propri di gestione dell'ambiente operativo: schedulatore, gestore della memoria, ecc.
- supporto alle system calls
- moduli di device drivers
Corrispondentemente vi sono due interfacce:
- interfaccia delle system calls - libreria standard del Linguaggio C (Glibc)
- interfaccia kernel-driver - con moduli caricati automaticamente
Interfacce Utente
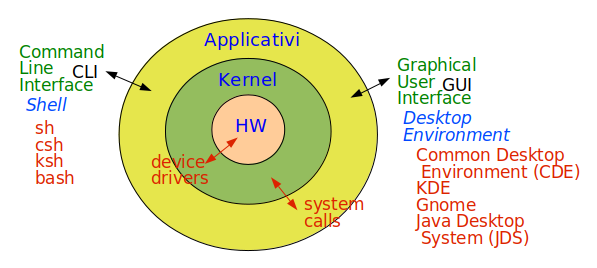
L'essere umano interagisce con gli applicativi Linux in due modalità diverse:
- Client User Interface (CLI) - a caratteri, sempre presente
- Graphical User Interface (GUI) - grafica, non strettamente indispensabile ma molto conveniente
Si può completamente interagire, amministrare e gestire un sistema Linux da CLI, con risparmio di risorse di memoria. Al giorno d'oggi però il risparmio di memoria non è veramente notevole e la convenienza del GUI rimane alta, specie per workstations e piattaforme di sviluppo software.
L'interfaccia CLI è implementata da un tipo di programma chiamato Shell. Vi sono numerose shell disponibili nelle varie versioni di Unix e distribuzioni di Linux; la particolare shell adottata dai Linux moderni è bash (Bourne again shell). Bash fornisce sia l'interattivita con l'utente, come interprete di comandi di linea, sia possiede un linguaggio di programmazione che permette di scrivere 'procedure shell' (shell scripts).
L'interfaccia GUI è implementata da un ambiente grafico complesso detto Ambiente Desktop (Desktop Environment). E' un derivato della serie di programmi detti X Window System originariamente sviluppati allo MIT fino al 1993.
Vi sono svariati ambienti desktop, ma i due rimasti come prioritari in Linux sono:
- Gnome - di default sia in Ubuntu che Red Hat
- KDE - di default in Slackware, installabile in Red Hat
Ogni distribuzione 'personalizza' poi il desktop con effetti e features propri, quindi l'interattività grafica (Look & Feel) dipende sia dalla distribuzione che dalla release.
Attività di Base
Collegamento a Linux

Tradizionalmente il collegamento avviene tramite un terminale (tty). I vecchi terminali a fosfori verdi o ambra, che si collegavano tramite link seriale asincrono (standard RS232) o via modem, non esistono più.
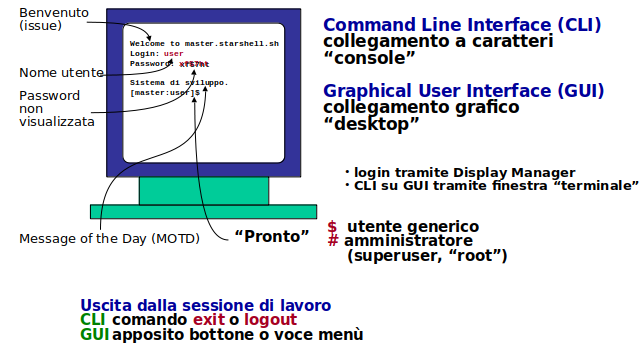
Il collegamento avviene ora usando un programma emulatore di terminale, e usando i protocolli di rete TCP/IP. Il protocollo più usato è ssh (secure shell). Tutti i linux dispongono di un server ssh, attivo di default in Red Hat.
All'atto del collegamento Linux presenta un messaggio di benvenuto, editabile nel file /etc/issue..Quindi richiede un nome di login e una password, invisibile all'atto della digitazione.
Se il login ha successo viene presentato il Message of the Day, editabile nel file /etc/motd. Possono essere compiute altre attività configurabili all'atto del login, alcune delle quali possono presentare messaggi aggiuntivi, p.es. ultimo login precedente o messaggi di posta ricevuti.
Per ultimo viene presentato il 'pronto' della shell, il cui formato è pure pesonalizzabile, ma che tipicamente
indica:
- il nome di login (logname)
- il nome della macchina (hostname)
- la directory corrente (present working directory - pwd)
Il pronto termina con un carattere indicante i privilegi, che può essere alternativamente:
$- utente normale#- amministratore
Il nome dell'amministratore è tradizionalmente root(ed è meglio non cambiarlo). Alcuni sistemi, come Red Hat, permettono il login come 'root' che ha poteri totali sul sistema. Altri, come Ubuntu, non permettono di default il login a 'root', ma sono organizzati concedendo privilegi parziali (o totali) a singoli utenti, tramite opportuni file di configurazione.
Dopo un login di successo l'utente è posizionato in una directory personale, detta HOME directory, nella quale ha tutti i privilegi operativi di cui ha bisogno. La HOME directory di utente è di solito /home/utente.I privilegi operativi di un utente normale in
altre directories sono di solito molto limitati.
La shell attivata, di cui si vede il pronto, si chiama la login shell ed in Linux è bash.
Per uscire dalla sessione di lavoro e compiere un logout, digitare il comando exit oppure premere
i tasti ^D (Control-D).
Qualche comando iniziale
id
Ritorna l'identità dell'utente.
- Ogni utente è internamente noto con un numero intero, lo UID (User ID). Questo è indicato, insieme al nome di login dell'utente tra parentesi. Gli utenti normali hanno uno UID superiore a 999,
- l'amministratore, anche detto il superuser ha lo UID 0.
- Ogni utente necessariamente appartiene ad un gruppo, detto il gruppo primario. Viene dato il GID (Group ID) del gruppo primario e il suo nome tra parentesi. Molto spesso il gruppo primario di un utente normale ha lo stesso nome dell'utente. Quando un utente crea un file, questo 'appartiene' all'utente che lo crea e al suo gruppo primario.
- Ogni utente potenzialmente può essere configurato in più gruppi, detti gruppi secondari, indicati da 'groups' come lista di GID e nomi gruppi. Un utente possiede tutti i privilegi dei gruppi a cui appartiene.
- Vi possono essere altre indicazioni fornite, p.es. le etichette di sicurezza dell'ambiente SELinux
who
Indica la lista di tutti gli utenti correntemente collegati al sistema, con dettagli per ciascuno di essi.
Un tempo, quando Unix era un sistema dipartimentale, non un personal computer, la lista fornita da whopoteva essere anche lunga.
whoami
Ritorna il nome dell'utente corrente dalla lista degli utenti.
Variante:
who am i - staccato (anche who am I) ritorna l'intera linea dell'utente corrente con i dettagli
w
Ritorna una tabella con un rapporto completo sugli
utenti collegati, incluso il comando che
ciascuno di loro sta eseguendo in questo momento.
Ritorna anche lo uptime, lanciabile come comando
separato:
- tempo totale di accensione del sistema
- numero degli utenti collegati
- carico medio del sistema a breve, medio e lungo periodo (1 min, 5 min, 15 min)
tty
Il nome del terminale corrente.
hostname
Il nome completo - FQDN (Fully Qualified Domain Name)
della macchina corrente, così come registrato a DNS.
pwd
'Present Working Directory' - percorso completo della directory corrente. Utilissimo prima dell'esecuzione dei comandi perchè potremmo non avere privilegi sufficienti in un'altra directory.
ls
Lista i file della directory corrente. E' un listato corto.
Varianti:
ls /etc- lista corta del contenuto della directory indicatals -l /- listato lungo della directory indicata - simile al dir di Windows La directory/si chiama 'directory radice' o root directory. Vi è un solo albero delle directories. Non esistono i 'drive'.
date
Ritorna un 'timestamp' con data ed ora. Il comando time non dà solo l'ora, ma cronometra il comando che segue.
man ls
Fornisce la 'pagina' di manuale del comando ls. E' attivo un paginatore che consente di scorrere in sù e in giù; comando q per uscire.
Cambio di password

Si esegue col comando passwd.
Viene chiesta:
- la password vecchia
- la password nuova
- la conferma della password nuova
La password deve avere complessità minima:
- almeno 8 caratteri
- almeno un carattere alfabetico
- almeno una maiuscola, o numero, o carattere speciale
- non deve essere simile al nome di login
- non deve essere simile alle parole contenute nel dizionario di controllo ortografico
La policy di complessità è determinata da un ambiente globale di sicurezza chiamato PAM(Pluggable Authentication Modules). In Red Hat il cambiamento da parte dell'amministratore del PAM è deprecato poichè può condurre ad una diminuzione
della sicurezza.
L'amministratore può resettare la password di qualsiasi utente col comando passwd utente.
L'amministratore non ha limitazioni PAM quando usa questo comando.
Le password sono solitamente sottoposte a invecchiamento. Può capitare che all'atto del login ad un utente venga chiesto di cambiarsi la password.
Solitamente quando mancano pochi (7) giorni allo scadere della password, l'utente viene avvertito all'atto del login.
Interruzione comandi
Il comando:
sleep 5
non fa nulla (dorme) per cinque secondi poi ritorna il pronto.
Il comando:
sleep 10000
si può interrompere coi tasti Ctrl-C (come in Windows).
Formalmente si dice che è stato inviato il segnale di interruzione al processo corrente.
E' possibile cambiare la combinazione di tasti che inviano il segnale di interruzione. Non è una buona idea, perchè tutti si aspettano un Ctrl-C, ma dimostra che questo aspetto è controllato da configurazione, non 'bruciato' nel sistema.
Digitare:
stty intr "^A"
che cambia in Ctrl-A la combinazione di tasti per il segnale di interruzione.
Attenzione: digitare ogni carattere come indicato. Cioè doppio-apice, accento circonflesso, A (maiuscolo o minuscolo ui non importa), doppio-apice.
Spiegazione:
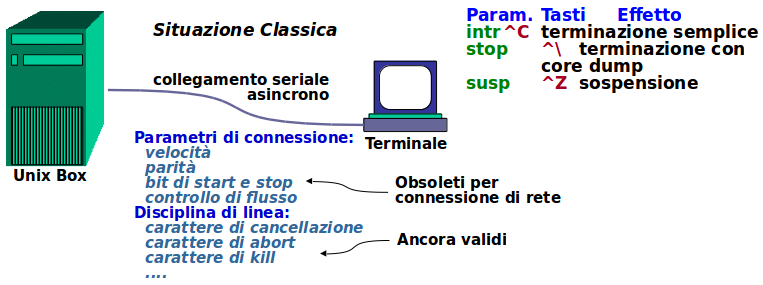
'Anticamente' i terminali avevano dei settaggi, p.es. la velocità in bit al secondo, parità, bit di start e di stop, ecc.
Tali settaggi si impostavano col comando stty. In particolare, per vedere i settaggi correnti, usare:
stty -a
speed 38400 baud; rows 30; columns 72; line = 0;
intr = ^C; quit = ^\; erase = ^?; kill = ^U; eof = ^D; eol = <undef>;
eol2 = <undef>; swtch = <undef>; start = ^Q; stop = ^S; susp = ^Z;
rprnt = ^R; werase = ^W; lnext = ^V; discard = ^O; min = 1; time = 0;
-parenb -parodd -cmspar cs8 -hupcl -cstopb cread -clocal -crtscts
-ignbrk -brkint -ignpar -parmrk -inpck -istrip -inlcr -igncr icrnl ixon
-ixoff -iuclc -ixany -imaxbel iutf8
opost -olcuc -ocrnl onlcr -onocr -onlret -ofill -ofdel nl0 cr0 tab0 bs0
vt0 ff0
isig icanon iexten echo echoe echok -echonl -noflsh -xcase -tostop
-echoprt echoctl echoke -flusho -extproc
NB: Qui e in esempi successivi il carattere $ non è da digitare.Serve a indicare il comando da dare, e differenziarlo dall'output prodotto dal comando.
Il rapporto fornisce due tipi di settaggi, quelli di controllo del terminale, e quelli della cosiddetta disciplina di linea. Tra i secondi abbiamo appunto tutti quelli con un segno di uguale, che denotano le sequenze per l'invio di segnali,
p.es. intr, quit, erase, ecc.
I caratteri di controllo terminale sono da considerarsi in pratica obsoleti, gli altri sono ancora efficaci.
Attenzione:
Qualsiasi cambiamento ai settaggi di terminale, come nel nostro esempio, è labile, e funziona soltanto per
la sessione di terminale corrente. Al prossimo login ritorneranno i settaggi di default.
Per rendere permanenti i settaggi di terminale, i comandi di settaggio devono essere inseriti nal file.bashrc nella directory di login. Questo è un file che viene eseguito ogni volta che viene lanciata la shell bash. (bashrc = bash run commands).
Naturalmente occorre un editor.
SSH

Collegamento da terminale remoto
Fornisce login remoto sicuro e altri servizi su canale insicuro
E' in realtà un'insieme di utilities:
ssh- secure shell - emulatore di terminale remotosftp- secure file transfer protocol - trasferimanto di filescp- secure copy - copia di files tra sistemi remoti
SSH fornisce:
- Crittografazione del canale
- Autenticazione forte - basato sull'uso di chiavi doppie (Pubblica / Privata)
- Tunnel per altri protocolli su ssh (X Window)
Contrasta:
- IP spoofing
- DNS spoofing
- Alterazioni di routing
SSH è anche usato come canale di connessione sicuro da altre utilities, p.es. Git.
E' una utility Client-Server
- Il server deve essere attivo sulla macchina che ospita i login
- Il server si autentica con chiave pubblica
- Il client deve accettare e fidarsi della chiave pubblica
E' possibile preinstallare le chiavi pubbliche degli host conosciuti
Files:
/etc/ssh/known_hosts(default per tutti gli utenti)$HOME/.ssh/known_hosts(per ciascun utente)

Ubuntu
Può non essere installato di default il server ssh
Test:
sudo service ssh status
sudo systemctl status ssh
which sshd
Ricerca del pacchetto:
sudo apt search sshd
Installazione:
sudo apt install openssh-server
Abilitazione / disabilitazione al target corrente:
sudo systemctl enable | disable ssh
Uso di SSH
Ottenere l'indirizzo IP della macchina:
ip addr show
Test in locale:
ssh utente@IP
- Rispondere 'yes' alla domanda di accettazione della chiave pubblica
- Dare la password di utente
- Uscire dalla shell con 'exit'
- La chiave viene registrata nel file
~/.ssh/known_hosts- E' possibile editare il file per rimuovere entries errate
Test da macchina remota:
ssh utente@IP
Collegamento SSH senza password
Questo diventa utilissimo in due casi principali:
- aumenta la sicurezza prevenendo la presenza di 'Man in the Middle'
- velocizza alcuni tipi di operazioni come il
git push
Il seguente è un esempio, da personalizzare secondo le proprie esigenze.
(1) E' necessaria una coppia di chiavi pubblica e privata. Se non se ne dispone già, generarla.
Generazione chiavi asimmetriche sul client:
ssh-keygen
- Accettare la locazione di default ~/.ssh/id_rsa
- Dare la passphrase 'segreto' ( 2 volte) (per esempio)
- Registrare la chiave allo ssh agent:
ssh-add- Viene chiesta la passhphrase
La 'passphrase' serve a crittografare il file contenente la chiave privata sul proprio sistema. E' un file molto delicato; se fosserubato e se è in chiaro, inficierebbe tutta la sicurezza del metodo.
(2) La chiave pubblica deve essere manualmente installata sul server.
Copy della chiave pubblica
cat ~/.ssh/id_rsa.pub
Copy di tutto il file nel clipboard
Collegarsi al server: ssh utente@IP
- Siamo ancora in modo 'normale', quindi viene ancora chiesta la password.
Editare il file contenente le chiavi autorizzate dal server:
vi ~/.ssh/authorized_keys
Incollare la chiave dal clipboard
E' indispensabile che il file delle chiavi permesse abbia sicurezza aumentata:
chmod 600 authorized_keys
Uscire quindi dalla sessione 'normale col server.
(3) Test della connessione senza password
ssh utente@IP
Viene chiesta la 'passphrase'. Questa non è la password di accesso al server, ma la password con cui è stata crittografata la chiave privata sul client.
Il sistema del client di solito pone tale 'passphrase' in una cache locale per alcuni minuti.
Collegamento parametrico
Per evitare digitazioni inutili, si può redigere il file di configurazione sul client. ~/.ssh/config
Host userv
User mich
Hostname 192.168.1.2
Port 22
IdentityFile ~/.ssh/id_rsa
Sostituire il proprio nome di login sul server e l'indirizzo del server
Si possono aggiungere più paragrafi, per più host remoti
Test:
ssh userv
Uso della Shell
La shell è l'interprete di comandi per l'interfaccia CLI.
La shell possiede anche un linguaggio di programmazione suo proprio - shells diverse hanno linguaggi con sintassi in generale simile, ma co molte differenze nei dettagli.
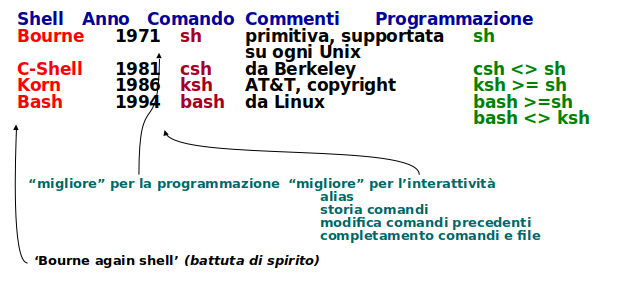
Vi sono state più shell storicamente notevoli:
sh- 'Bourne' shell (1971)- un dipendente della AT&T, non Jason Bourne dei romanzi
- molto di base, se si vuole rilanciare il comand precedente, occorre ridigitarlo
- il linguaggio di scripting associato è basilare, un poco 'strano'
csh- C shell di Berkeley (circa 1981)- l'idea era di far assomigliare lo scripting al linguaggio C - non è riuscito molto bene
- il linguaggio di scripting C shell è completamente incompatibile con quello della Bourne shell
- l'interattività è migliore, ma ancora molto ostica
ksh- 'Korn' shell, nome dell'autore (AT&T, 1986)- più interattiva, con comandi tratti dall'editor 'vi'
- lo scripting è un superinsieme della Bourne shell
- è la shell di default dello Unix IBM - AIX
bash- 'Bourne' again shell.- gioco di parole, rifacimento della shell di Bourne
- l'interattività è molto migliorata
- lo scripting è un superinsieme di quello della Bourne shell ma diverso da quello della Korn shell
Fino a non tanti anni fa' il suggerimento era:
- usare la bash per comandi interattivi
- programmare i Bourne shell per la massima portabilità
Non è più vero. Tutti i Linux e anche gli Unix moderni hanno la Bourne shell: meglio usare questa sia per il comportamento interattivo che per le procedure (scripts).
Codice colore
Quando si listano dei file col comando ls, sia in Ubuntu che in Red Hat, in realtà si invoca un alias, definito come:
alias ls='ls --color=auto'
Provare a dare il comando alias e lo si vede.
Questo fa sì che i file vengano colorati diversi a seconda del loro tipo.

Struttura dei comandi
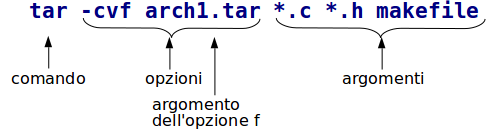
Il comando è il primo elemento della linea di comando.
Le opzioni sono precedute dal trattino:
-a -b -c = -abc = -bc -a
Le opzioni indicano un comportamento variante rispetto al comando principale.
Il trattino indicante l'opzione è stato inventato dallo Unix System V, Lo Unix di Berkeley non ce l'aveva.
Teoricamente le opzioni sono indipendenti e possono essere date in qualsiasi ordine. Non è sempre vero però, a volte le opzioni devono essere date in un ordine prestabilito e possono esserci opzioni che dipendono dalla presenza di altre, precedenti, opzioni.
A volte si hanno opzioni diverse logicamente incompatibili tra loro.
In qualche comando vi è un insieme di opzioni alternative tra cui occorre necessariamente usarne una e una sola: si chiamano opzioni chiave.
Le opzioni sono decise dai programmatori e diverse per comandi diversi: non esistono opzioni comuni a tutti i programmi.
L'unico modo è di leggere il manuale.
Da qualche anno a questa parte si è affermato un nuovo stile di opzioni, precedute da due trattini, in cui l'intera parola a seguire rappresenta l'opzione, non ogni singolo carattere.
Per esempio:
-bar = -b -a -rsono tre opzioni--barè una singola opzione
Non tutti i programmatori usano questa convenzione, però.
Esempio. Opzioni di ls
| Comando | Azione |
|---|---|
ls | solo nomi files, multicolonna verticale |
ls -l | tutti i principali attributi dei file |
ls -lh | colonna dimensione in unità più 'umane' |
ls -a | anche i file nascosti - sono nascosti i files il cui nome inizia con punto |
ls -F | segnalini finali per indicare il tipo di file |
ls -x | solo nomi files, multicolonna orizzontale |
ls -S | sortizza per dimensione file |
ls -t | sortizza per data di aggiornamento |
ls -X | sortizza per estensione |
ls -? | paginata di aiuto |
- Non necessariamente i nomi dei file hanno un'estensione
- L'estensione viene utilizzata dai programmi, non dal sistema operativo, oppure è per chiarezza umana
- L'estensione non è necessariamente di tre caratteri
Contenuto di un File
Mandare tutto il contenuto di un file ad output:
cat file
Paginare il file:
more file- (vecchio e deprecato)less file- (il meno è meglio del più)
Principali comandi interni di less:
SPAZIO ^F PgGiu- giù di una paginab ^B PgSu- su di una paginar ^R- ridisegna il videog- va a inizio fileG- va a fine file/stringa | ?stringa- ricerca in avanti | all'indietron | N- prosegue la ricerca in avanti | all'indietro!comando- esegue un comando shell esternov- entra in editazione del file corrente- Secondo la variabile d'ambiente EDITOR
- Al termine dell'editazione si torna in less
q ZZ- esce dalla visualizzazione
Il Comando date
Il comando date ha un feature che non è una opzione, ma una stringa di formattazione: questa è racchiusa tra singoli apici e preceduta dal carattere + (più).
date- visualizza stringa di data e oradate +'%H:%M:%S'- dà ore, minuti e secondidate +'%T'- stesso effettodate +'%d/%m/%y'- dà giorno, mese e annodate +'%D'- stile americano
E' possibile, per il superuser usare il comando 'date' per settare la data e l'ura corrente:
date MMDDhhmmYYYY.ss
Esempio: date 073114352017.00
- 31 luglio 2017 alle 14:35:00
Nota
In ambiente enterprise non è una buona idea settare la data a mano.
Tutte le varianti moderne di Unix devono avere l'ora sincronizzata mondialmente a meno di mezzo secondo di scarto. Questo è possibile soltanto usando il Network Time Protocol (NTP).
Nella precedente 'arte di amministrazione di sistema', c'era la raccomandazione di compiere un reboot immediato se si cambiavano i seguenti parametri:
- ora di sistema
- nome del computer
- indirizzo IP
La ragione era che molti servizi mettono questi parametri in cache quando sono attivati, e l'unico modo di garantire la sanità del sistema era di farlo ripartire dall'inizio.
Chi non lo faceva si accorgeva che a distanza di tempo, minuti a giorni a mesi, si verificavano 'strane' inconsistenze, sempre al momento meno opportuno per un restart.
I server di oggi non devono MAI essere spenti. Devono essere installati, configurati, e lasciati da soli per anni. Qualora si verificassero dei crash dovuti a condizioni ambientali (mancanza di corrente, ecc. - che pure non devono verificarsi se c'è un'unità di continuità appropriata), i sistemi devono ristartare da soli e tornare in produzione piena da soli.
Il target di RHEL è proprio questo: si autoamministra.
Occorre comunque adottare avvedutezze:
- avere un'aggiornamento automatico della release, con opportuno contratto
- usare solo hardware approvato
- usare solo software previsto dalla distribuzione, o software approvato dalla Red Hat (Java, DB Oracle, ecc.)
- monitorare automaticamente da remoto lo stato del server con utilities che forniscano allerte automatiche
Red Hat Enterprise Server possiede ambienti che informano i servizi all'atto dei cambiamenti dei parametri principali di sistema, consentendo il loro aggiornamento senza bisogno di un reboot.
Personalizzazioni

Pronto della Shell
Due variabili d'ambiente principali:
PS1- pronto primario- Diverso in diverse versioni di Unix, si può settare
PS2- pronto di continuazione, quando il comando non è terminato o vi sono stringhe aperte- Default "
>", meglio non cambiarlo
- Default "
La Bash ha altri due pronti molto meno usati:
- PS3 - pronto di select
- PS4 - pronto di shell debugging
Settare il pronto primario:
PS1='stringa'
Valido nella shell corrente (eventualmente: .bashrc)
La stringa può contenere valori di variabili d'ambiente o segnalini
Pronto: esempi
PS1='comanda padrone '- Massaggio dell'ego
PS1='c:$PWD> '- Emulazione di Windows - la directory corrente completa può diventare molto lunga
PS1='\u@\h:\w $ '- Chi sono, in che computer sono, in che directory di base sono e sono un utente normale
PS1='\u@\h [$(date +%H:%M:%S)]> '- Chi sono, dove sono e che ore sono
PS1='\e[42m \e[47m \e[41m \e[0m > '- Patriottico
PS1="\n\e[42m \e[47m \e[41m \e[0m \u@\h:\w $([ $UID -eq 0 ] && echo \# || echo \$) "- Due linee, patria, id, host, dir e se sono root o no
Alias
Sostituzione di una stringa con un'altra
alias dir='ls -l'
Lo alias ha precedenza sui comandi, anche interni:
alias cd..='cd ..'
alias date='date +%d/%m/%y'
Ma attenzione ai riferimenti circolari o di comandi preesistenti:
alias time='date +%H:%M:%S'
- Quali alias sono definiti:
alias - Definizione di un particolare alias:
alias date - Cancellazione di un alias:
unalias date
Gli alias vanno configurati in:
~/.bash_profilein RHEL~/.bash_aliasesin Debian/Ubuntu
NB: ~ identifica la directory di login
Storia dei Comandi
- Richiamare il comando precedente: freccia su
- Si può quindi editare e lanciare
- Premere INVIO ovunque, non serve andare alla fine
- Rilanciare il comando precedente senza editare:
!-1oppure!! - Rilanciare l'ultimo comando che iniziava con ls:
!ls - Rilanciare l'ultimo comando che conteneva la stringa 192:
!?192 - Visualizzare la storia dei comandi:
history - Rilanciare il comando 42:
!42Lanciare il comando stat con l'argomento dell'ultimo comando:stat !$ - Verificare senza lanciare:
!!:p !42:p !?192:pecc. - Cancellare la storia:
history -c
La storia dei comandi viene conservata in memoria in un buffer
- La dimensione è data dalla variabile d'ambiente
HISTSIZE
Alla chiusura del terminale il buffer è salvato in append in un file della directory di login
- Nome dato dalla variabile d'ambiente
HISTFILE - Default:
.bash_history - Dimensione massima del file data dalla variabile d'ambiente
HISTFILESIZE
Variabili d' Ambiente
Personalizzano il comportamento di comandi ed utilities
printenv- lista tutte le variabili d'ambiente correntiexport VAR=valore- crea una variabile di nome VAR e dato valore e la esporta all'ambiente- per convenzione le variabili d'ambiente hanno nome maiuscolo
- tutti i comandi successivi la conoscono
unset VAR- cancellare una variabile
Non tutte le variabili d'ambiente potenzialmente utili sono già settate
Se una variabile d'ambiente non è settata, il programma che eventualmente la usa ha un comportamento di default
Esempi di Variabili d'Ambiente
less file
Si può entrare in editazione con il comando less v che invoca:
- l'editor definito nella variabile d'ambiente
EDITORse esiste vionanodi default in Red Hat
man comando
man visualizza schermate usando il paginatore definito nella variabile d'ambiente PAGER se esiste oless di default
Configurazioni
Files o directories che si trovano nella directory di login dell'utente
Tipicamente sono nascosti: iniziano con . (punto)
-
.bash_profile- comandi eseguiti al login con la Bash shell -
.bashrc- comandi eseguiti al lancio della Bash shell (p.es. nuova finestra di terminale) -
.ssh- directory con i settaggi dell'utilityssh -
ls -a- listare i file nascosti -
source .bash_profile- rieseguire la procedura.bash_profiledopo un cambiamento per non compiere relogin- Ma le utilities non shell (grafiche, ecc.) non hanno sentito i cambiamenti
Aspetti Avanzati
Linea di Comando
Durante l'editazione di un comando vi sono una serie di caratteri di controllo che si possono usare per avere più produttività.
| Comando | Effetto |
|---|---|
| Ctrl-A | All'inizio del comando |
| Ctrl-E | Alla fine del comando |
| Ctrl-U | Cancella intera linea (salva nel buffer) |
| Ctrl-W | Cancella parola precedente (salva nel buffer) |
| Ctrl-Y | Paste del buffer |
| Ctrl-B | Indietro di un carattere |
| Ctrl-F | Avanti di un carattere |
| Ctrl-P | Comando precedente |
| Ctrl-N | Comando seguente |
| Ctrl-T | Inverte i due caratteri precedenti |
| Ctrl-O | Esegue la linea di comando |
| Ctrl-R stringa | Ricerca all'indietro nella storia per la stringa |
| Ctrl-L | Pulisce il video |
| Ctrl-X Ctrl-E | Inserisce la linea di comando in una sessione di editor, e lo esegue quando l'editor termina |
Quale editor venga usato è dato dal valore della variabile d'ambiente EDITOR.
tput
Invia una sequenza di controllo al terminale, come specificata in terminfo .
| Comando tput | Effetto |
|---|---|
| tputcolors | ritorna il numero di colori supportati |
| tput lines | ritorna il numero di linee delterminale corrente |
| tput cols | ritorna il numero di colonne del terminale corrente |
| tput sc | salva la posizione del cursore |
| tput rc | restore della posizione del cursore |
| tput home | cursore in alto a sinistra (0, 0) |
| tput cup x y | cursore a posizione (x, y) |
| tput cud1 | cursore giù si una linea |
| tput cup1 | cursore su di una linea |
| tput civis | cursore invisibile |
| tput cnorm | cursore normale |
| tput bold | testo in bold |
| tput smul | inizio testo sottolineato |
| tput rmul | fine testo sottolineato |
| tput rev | testo a colori invertiti |
| tput blink | testo lampeggiante |
| tput invis | testo invisibile |
| tput smso | testo a modalità standout |
| tput rmso | fine modalità standout |
| tput sgr0 | toglie tutti gli attributi al testo |
| tput setaf valore | colore di foreground |
| tput setab valore | valore di background |
| tput smcap | salva l'intero schermo |
| tput rmcap | restore dello schermo |
| tput el | pulisce fino a fine linea |
| tput el1 | pulisce fino a inizio linea |
| tput ed | pulisce dal cursore a fine video |
| tput clear | pulisce tutto il video |
I valori per i colori sono:
| Valore | Colore |
|---|---|
| 0 | nero |
| 1 | rosso |
| 2 | verde |
| 3 | giallo |
| 4 | blu |
| 5 | magenta |
| 6 | ciano |
| 7 | bianco |
| 8 | non usato |
| 9 | restore dei colori originali |
Non tutti i terminali possiedono tutte le capabilities.
Il seguente programma testa l'acquisizione dinamica delle dimensioni del terminale corrente.
Fa uso del fatto che X Window invia il segnale WINCH al terminale al variare delle proprietà della finestra del terminale.
(size.sh):
#!/bin/bash
# term_size2 - Dynamically display terminal window size
redraw() {
clear
echo "Width = $(tput cols) Height = $(tput lines)"
}
trap redraw WINCH
redraw
while true; do
:
done
Il prossimo programma testa vari attributi del testo.
(tput.sh):
!/bin/bash
# tput_characters - Test various character attributes
clear
echo "tput character test"
echo "==================="
echo
tput bold; echo "This text has the bold attribute."; tput sgr0
tput smul; echo "This text is underlined (smul)."; tput rmul
# Most terminal emulators do not support blinking text (though xterm
# does) because blinking text is considered to be in bad taste ;-)
tput blink; echo "This text is blinking (blink)."; tput sgr0
tput rev; echo "This text has the reverse attribute"; tput sgr0
# Standout mode is reverse on many terminals, bold on others.
tput smso; echo "This text is in standout mode (smso)."; tput rmso
tput sgr0
echo
Il prossimo programma prova varie combinazioni di colori.
(colors.sh):
#!/bin/bash
# tput_colors - Demonstrate color combinations.
for fg_color in {0..7}; do
set_foreground=$(tput setaf $fg_color)
for bg_color in {0..7}; do
set_background=$(tput setab $bg_color)
echo -n $set_background$set_foreground
printf ' F:%s B:%s ' $fg_color $bg_color
done
echo $(tput sgr0)
done
L'ultimo programma illustra la visualizzazione di alcune proprietà del sistema, guidata da menù.
(menu.sh):
#!/bin/bash
# tput_menu: a menu driven system information program
BG_BLUE="$(tput setab 4)"
BG_BLACK="$(tput setab 0)"
FG_GREEN="$(tput setaf 2)"
FG_WHITE="$(tput setaf 7)"
# Save screen
tput smcup
# Display menu until selection == 0
while [[ $REPLY != 0 ]]; do
echo -n ${BG_BLUE}${FG_WHITE}
clear
cat <<- EOF
Please Select:
1. Display Hostname and Uptime
2. Display Disk Space
3. Display Home Space Utilization
0. Quit
EOF
read -p "Enter selection [0-3] > " selection
# Clear area beneath menu
tput cup 10 0
echo -n ${BG_BLACK}${FG_GREEN}
tput ed
tput cup 11 0
# Act on selection
case $selection in
1) echo "Hostname: $HOSTNAME"
uptime
;;
2) df -h
;;
3) if [[ $(id -u) -eq 0 ]]; then
echo "Home Space Utilization (All Users)"
du -sh /home/* 2> /dev/null
else
echo "Home Space Utilization ($USER)"
du -s $HOME/* 2> /dev/null | sort -nr
fi
;;
0) break
;;
*) echo "Invalid entry."
;;
esac
printf "\n\nPress any key to continue."
read -n 1
done
# Restore screen
tput rmcup
echo "Program terminated."
Il seguente comando aggiorna perennemente la data e l'ora ponendole nell'angolo in alto a destra dello schermo.
while sleep 1;do tput sc;tput cup 0 $(($(tput cols)-20));date +'%D %T';tput rc;done &
Colori
Alcuni terminali supportano 256 colori. Si possono ottenere mandando direttamente a terminale le sequenze di escape ANSI.
Il seguente programma prova tutti i colori di foreground e background:
(fbcolors.sh):
#! /bin/bash
for code in {0..255}
do
echo -e "\e[38;05;${code}m $code: Test"
done
for code in {0..255}
do
echo -e "\e[48;05;${code}m $code: Test \e[48;05;0m"
done
Editors di Linux
Un editor ha un'enorme importanza nel lavoro di un programmatore o sistemista - anche solo per cambiare files di configurazione o scrivere procedure shell.
Unix ha una lunga storia di sviluppo di editors di testi, poichè è sempre stato usato da programmatori.
Nell'interazione a caratteri di Red Hat Enterprise Linux ed Ubuntu sono già disponibili due editor:
- nano - editor tradizionale, semplice, non modale, limitato
- vim - editor avanzato, modale, potente ma non facile
Si possono comunque installare altri editor da repository RH o da rete. Questo diventa indispensabile per il programmatore.
A lungo andare è meglio però imparare anche ad usare il vim, poichè non si può sapere quale editor sia installato sulla macchina di destinazione.
L'editor vim possiede un vasto ecosistema di plugin, ad esempio per la colorazione sintattica dei programmi, l'indentazione automatica, gli snippets, ecc.
Ad un amministratore di sistema non serve veramente la competenza con un particolare editor, piuttosto un editor che sia semplice e intuitivo per editare files di configurazione o procedure shell.
La Tastiera
La tastiera Linux italiana contiene molti più tasti di quella Windows. Nell'immagine seguente:
- Basso a sinistra: Tasto
- Alto a sinistra: Shift+Tasto
- Basso a destra: AltGr+Tasto
- Alto a destra: AltGr+Shift+Tasto
Per AltGr si intende Alt Grafico, il tasto a destra della barra spaziatrice.

Linux ha un Metodo di Input che usa combinazioni di tasti sia parallele che seriali.
Con le combinazioni seriali si ottengono lettere accentate, umlaut, ecc.
Per esempio:
AltGr+Shift+. vocale – mette l'umlaut alla vocale
AltGr+Shift+à a – produce å
Digitare la prima combinazione, quindi staccare le dita dalla tastiera e poi premere il secondo tasto.
Il metodo di input di windows, Alt+numero, non esiste in linux.
Attenzione:
La tastiera e il metodo di input Linux sono disponibili se si sta lavorando su Linux, su un terminale a caratteri o finestra di terminale direttamente connessa alla console.
Se si accede a Linux dalla rete, tramite un emulatore di terminale, la tastiera in vigore e il suo comportamento sono quelli del sistema locale, non di Linux.
Per esempio, se su Windows si usa Putty per accedere a Linux tramite SSH, la tastiera è quella di Windows, non Linux.
Per questo si raccomanda, per gli sviluppatori di software, di usare una workstation Linux.
Tasti più usati
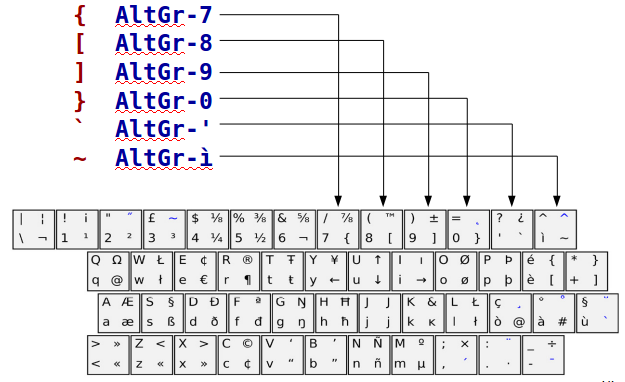
I tasti più usati nelle procedure shell sono tra loro vicini, in alto a destra (ottenuti con AltGr).
Nano

Semplice editor incluso in Red Hat e in molte varianti Linux.
Editare semplicemente il file come in un editor tradizionale
- Usare le frecce
- Usare PgUp e PgDown
Comandi ottenuti con Modificatore-Lettera premuti simultaneamente
Due modificatori
- Control – indicato p.es.
C-X– non si usa mai Shift - Meta – in Linux:
Alt(sinistro, non Alt Grafico) – indicato p.es. A-M
(Il menù d'aiuti imdica questo modificatore con M )
Attenzione: se è impostato il modo wraparound (a capo automatico) delle linee, disabilitarlo con A-L (provare)
Comandi Principali di nano
Salvataggio file:
C-O– chiede conferma del nome file- 'Invio' per conferma
- Digitare altro nome e Invio per cambiare
C-Tchiama un pseudo-browser per scegliere il nomeC-Cper cancellare l'azione
Uscita da editazione:
C-X– chiede se salvare il file correnteYsalva il fileNabbandona il fileC-Ccancella l'uscita e torna in editazione
Import di un file a cursore:
C-R– chiede nome fileC-Tper selezionare da pseudo-browserC-Cper cancellare l'azione
Aiuto:
C-Gapre l'aiuto dei comandiC-Xper uscire dall'aiuto
A-Xtoglie/mette le due linee d'aiuto inferiori
Movimento:
- Frecce, PgUp, PgDown
C-Aa inizio rigaC-Ea fine rigaA-Gsalta a linea- numero per linea con tale numero
C-Yinizio fileC-Vfine file
- C-C mostra la posizione corrente
Per mostrare i numeri di linea lanciare nano con nano -c nomefile
Copia e incolla:
A-Amarca il ponto d'inizio del bloccoA-^copia fino al cursore esclusoC-Ktaglia fino al cursore esclusoC-Uincolla al cursore (si può ripetere)
Ricerca:
C-Wchiede il testo da ricercareA-Wripete la ricercaA-Rricerca e rimpiazza- Il menù indica i modficatori della ricerca
C-Ccancella la ricerca
Altri:
C-Ksenza blocco marcato cancella fino a fine riga- Escape due volte seguito da un numero da 0 a 255 entra il carattere col dato codice ASCII
Vi e Vim

“visual editor”
Ci aono 10 tipi di persone: quelli che capiscono il codice binario e quelli no.
Ci sono due tipi di amministratori e programmatori Unix: quelli che usano Vi e quelli che credono sia un numero romano.
- Editor destinato ai programmatori
- Non è un word processor
- linea e carattere corrente, non paragrafo
vi [opzioni] [file]
view file– apri in modo read-onlyvi -r file– recupera un file dopo un crash
L'editor 'vi' è una evoluzione dell'editor 'ex' (extended editor)
che esisteva prima che vi fossero i terminali, ovvero quando ancora si interagiva col sistema da console come macchina da scrivere.
I terminali apparsi a partire dagli anni '80 erano così tanti e di tante marche diverse che non ci si poteva attendere un normale layout di tasti come al giorno d'oggi.
Gli unici tasti su cui si poteva contare erano:
- i tasti della normale macchina da scrivere
- il tasto Escape che inviava sequenze di caratteri di controllo al terminale
E' stato quindi deciso di produrre un editor modale.
Con l'avvento di Linux, tipicamente usato da PC, quindi con tastiera uniforme, è stato deciso di introdurre un nuovo editor, più moderno e che comprendesse p.es. le frecce, ma che fosse completamente compatibile col 'vi'.
Dopo alcuni tentativi andati a vuoto, il prodotto si è stabilizzato nell'editor 'vim'.
vim - vi improved
Molti più comandi e complessità del vi, ma i comandi di base sono gli stessi
Modi di vim
Vi è un editor modale. Due modalità:
- comando - ogni lettera o combinazione corrisponde ad un comando dell'editor
- inserimento (editazione) - i tasti digitati finiscono direttamente nel file in editazione
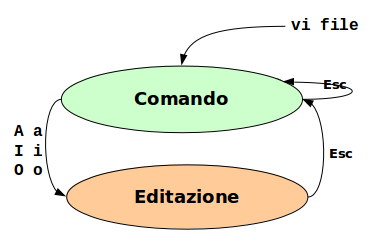
All'apertura di un file ci si trova in modalità comando.
Per passare in modalità editazione vi è un numero limitato di comandi, tra cui il più comune è i (inserimento).
Per tornare in modalità comando battere il tasto Esc (escape).
Se im modalità comando si batte il tasto Esc, si rimane in modalità comando.
vim minimo
Per i timorosi di apprendere troppi comandi strani, un semplice procedimento/trucco permette di usare 'vi' facilmente.
Aprire un file procedura shell per l'editazione:
vim file.sh
- Il primo comando deve essere
i(insert)- Compare in basso a sinistra la scritta
-- INSERT -- - Siamo in modalità editazione
- Compare in basso a sinistra la scritta
- Navigare normalmente con le frecce
- Editare come su un editor normale
Al termine:
- Digitare
Esc. Scompare la scritta-- INSERT --- Siamo in modalità comando
- Per salvare ed uscire:
:wq ENTER- Il digitato compare sull'ultima linea
- Per uscire senza salvare:
:q! ENTER - Per salvare e proseguire:
:w ENTER i
Vi: Terminologia
Essendo un editor e non un word processor, 'vi' ha il concetto di carattere corrente e linea corrente, ma non di paragrafo corrente
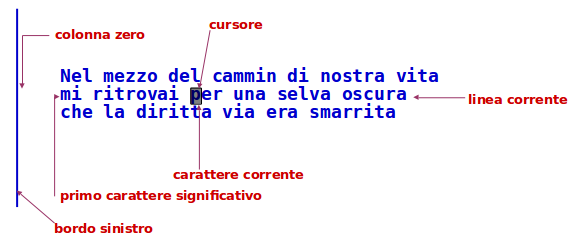
Il cursore è esattamente sopra un carattere e non nell'intervallo tra due caratteri. Il cursore può essere rappresentato come underscore, o come un blocco lampeggiante.
Il fatto che il cursore sia proprio sopra un carattere, e su un alinea, conduce naturalmente al concetto di 'dopo' e 'prima' del carattere, e 'dopo' e 'prima' della linea.
E' prevista una differenza tra il bordo sinistro assoluto di una linea (colonna zero) e il primo carattere significativo della linea indentata.
Comandi di vi
Allo scopo di imparare i comandi 'vi', occorre provarli.
Si consiglia di produrre un file su cui esercitarsi, p.es. come segue:
man bash > bash1.txt
vi bash1.txt
Comandi di inserimento
a- dopo il carattere correntei- prima del carattere correnteA- a fine lineaI- a inizio linea, prima del primo carattere significativoo- in una nuova linea sottoO- in una nuova linea sopra
Comandi di movimento semplice
I comandi di movimento sono molto importanti.
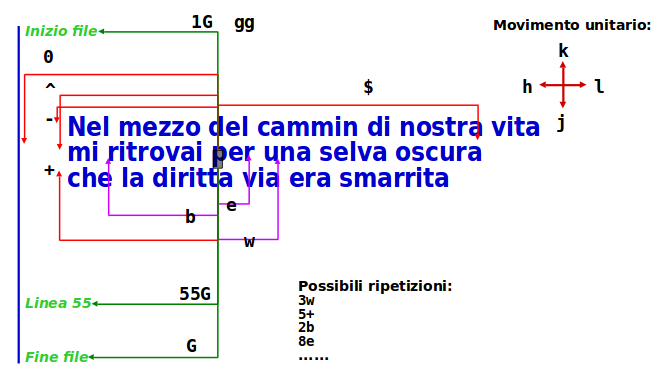
Tramite i comandi di movimento si compiono le operazioni di cut, copy e paste.
Comandi di movimento avanzato
Non sono indispensabili di primo acchito ma:
- risparmiano il numero di tasti digitati
- sono ideali per l'inserimento in macro

Comandi di salvataggio

I comandi di salvataggio sono per la maggior parte dei comandi ex. Quando si digitano i due punti come comando, sientra in modalità ex:
- l'ultima linea del video contiene il comando
- sono possibili comandi anche lunghi terminati da Invio
- per eventualmente interrompere il comando, battere Esc
Comandi di salvataggio avanzato
Sono derivati dall'editor ex. Quando si preme : in modalità comando, si apre l'ultima linea dello schermo ed è possibile editare un comando esteso.
:w file- salva tutto il file corrente con altro nome:1,5w file- salva da riga 1 a 5:1,.w file- salva da riga 1 a riga corrente:.,+5w file- salva da riga corrente fino a 5 righe dopo:.,’aw file- salva da riga corrente a riga marcata con a:r file- inserisci file esterno dopo riga corrente
Operazioni sui file
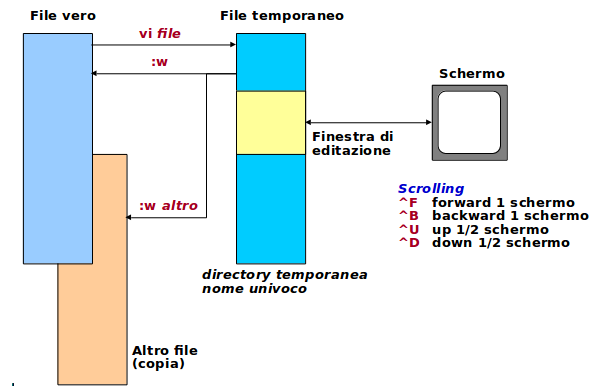
Vi non sta editando il file vero, ma una sua copia. In caso di crash di sistema, al boot successivo è di solito possibile recuperare la precedente sessione di editazione del file temporaneo.
Il 'save' è in realtà un commit. tutti i cambiamenti effettuati vengono finalizzati nel file vero. Tutti i buffer di undo vengono azzerati.
Il salvare con altro nome è un'operazione diversa da altri editor: dopo tale operazione non abbiamo cambiato il nome del file corrente, ma prodotto uno snapshot sul file indicato. Stiamo ancora lavorando sul file originale.
Ricerche in un file

Le ricerche vengono impostate digitando / (slash), che apre l'ultima riga del video e attende il comando di ricerca.
Anche questa è una modalità di 'ex'.
Digitare l'espressione regolare ricercata e premere Invio.
Per compiere la ricerca all'indietro nel file usare ? invece di /.
La ricerca si può ripetere in più modi:
/- continuare la ricerca della stessa espressione regolare in avanti?- continuare la ricerca della stessa espressione regolare all'indietron- continuare la ricerca della stessa espressione regolare nella stessa direzione di prima
Se la ricerca arriva alla fine del file, in avanti o all'indietro, la prossima ricerca compie un wrap arond, cioè prosegue rispettivamente dall'inizio o dalla fine del file.
Markers
Per ricordarsi delle posizioni nel file sono disponibili dei segnalini o markers:
- nome da
afino az - marcano linee , non caratteri nè blocchi
- non è visibile se e quali linee siano marcate
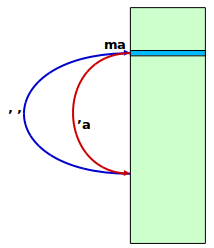
Uso:
ma- marca linea corrente con a’a- vai a linea marcata con a’’- vai a linea prima dell’ultimo movimento (è unsingolo apice ripetuto due volte)'.- vai a linea dell'ultimo cambiamento:marks- mostra i segnalini correnti
Taglia e Incolla
Comandi con prefisso
Permettono di compiere le operazioni di cut, copy e change.
Hanno la struttura
prefisso [ripetizioni] comando_di_movimento
I prefissi sono
d- delete - cancellazioney- yank - copiac- change - cambiamento
L'operazione si estende dal carattere corrente a quello raggiunto col comando di movimento
- Il numero di ripetizioni si riferisce al comando di movimento
- Il materiale cancellato, copiato o cambiato viene conservato nel buffer senza nome
- E' poi possibile il paste coi comandi
poP
- E' poi possibile il paste coi comandi
- Il comando
u(undo) disfa la cancellazione, copia o cambiamento- in vim l'undo è multilivello
Cut (delete)
d + movimento:
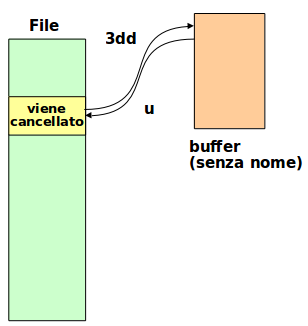
Esempi:
dwcancella fino a inizio parola successivadecancella fino a fine parolad^cancella fino a inizio rigad$cancella fino a fine rigad’acancella fino a riga marcata con ad3+cancella fino a tre righe dopodGcancella fino a fine fileddcancella intera riga
Ammettono ripetitori:
10dw10 voltedw(comed10w)5dd5 voltedd(anched5d)
Paste (put)
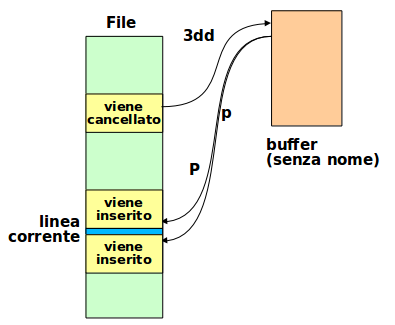
Semplicemente posizionarsi alla destinazione desiderata e premere:
pdal buffer a dopo il carattere o la linea correntePdal buffer a prima del carattere o della linea corrente
Se sono state tagliate/copiate delle linee, queste verranno incollate dopo/prima la linea corrente del cursore.
Se sono stati tagliati/copiati dei caratteri, questi verranno incollati dopo/prima il carattere corrente.
Copy (yank)
y + movimento:
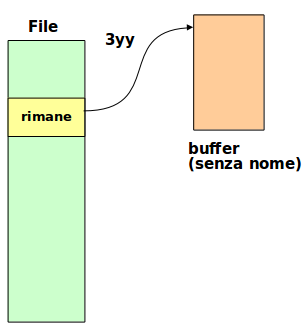
Esempi:
ywcopia fino a inizio parola successivayecopia fino a fine parolay^copia fino a inizio rigay$copia fino a fine rigay’acopia fino a riga marcata con ay3+copia fino a tre righe dopoyGcopia fino a fine fileyycopia intera riga
Ammettono ripetitori:
10yw10 volte yw (come y10w)5yy5 volte yy (anche y5y)
Modifica (change)
c + movimento + versione nuova + Escape:
Dopo il c + movimemto la versione precedente scompare e si entra in modalità inserimento.
Digitare la nuova versione e premere Escape: il cambiamento è finalizzato.
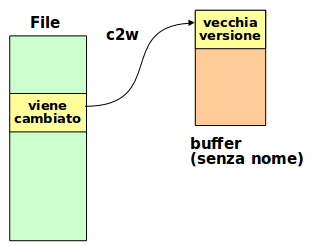
. (punto) ripeti ultimo cambiamento o cancellazione
Cancellazione o modifica avanzate
xcancella singolo carattere correnteDcancella fino a fine riga (=d$)Ccambia fino a fine riga (=c$)Ycopia fino a fine riga (=y$)rcrimpiazza carattere corrente concRentra in modalità “replace”: ogni carattere successivo sostituisce il carattere corrente. Terminare con Escape.~Cambia carattere corrente da maiuscolo a minuscolo o viceversa e avanza a carattere successivo
Buffers con nome
Vi sono 26 altri buffer disponibili oltre quello senza nome.
- Nomi dalla
aallaz - Preceduti da
"(doppio apice) - Prima di comandi delete, yank, change, put
Esempi
”adw- cancella parola a buffera”zy’c- copia da qui a linea marcata conce poni nel bufferz”zp- paste dal bufferz
Ricerche globali
Sintassi:
[range]g/espr_reg/[comando]
- Applicato a tutte le linee di range
- Lista (inizio,fine) come in ed o espressione regolare
- Ricerca espr_reg un'espressione regolare
- Esegue il comando specificato
p- mostra le righe trovate#- mostra le righe col numero di rigad- cancella le righe trovatey- copy (yank) delle righe trovatenormalcomando - esegue il comando esteso vi su ogni riga trovata
Esempi
g/the$/p- Mostra tutte le righe che terminano con the
.,$g/^ *pippo/#- Dalla riga corrente a fine file mostra i numeri e le righe contenenti pippo dopo un qualsiasi numero di spazi da inizio riga
g/^$/d- Cancella tutte le righe vuote
1,/^Examples/g/^Section/+y- Da inizio file alla riga che comincia con Examples copia la linea dopo quella che inizia con Section
g/^Section/normal ONew- Trova tutte le righe che cominciano con Section e aggiungi prima di esse una riga contenente New
Il comando g/Regular_Expression/p è così usato e utile, che è diventato il comando linux grep.
Sostituzioni globali
Sintassi:
[range]s/espr_reg/str_rimpiazzo/[flags][conto]
- Applicato a tutte le linee di range
- Lista (inizio,fine) o espressione regolare
- Ricerca espr_reg, un'espressione regolare
- La sostituisce con la stringa di rimpiazzo
- Secondo le modalità dei flags
c- chiede confermai- ignora caseI- obbedisce al case (default)n- non esegue la sostituzionep- stampa solo le linee trovate (non è necessaria la stringa di rimpiazzo)
- Esegue conto volte (default una)
n- (numero) volteg- ogni volta sulla linea
Settaggi
Modificano il comportamento di vi e vim
- Per vedere i settaggi correnti
:set - Per vedere tutti i settaggi possibili
:set all- Possono essere molte pagine. Per interrompere
Ctrl-C
- Possono essere molte pagine. Per interrompere
Eaempi:
- Per settare i numeri di linea
:set number - Per togliere i numeri di linea
:set nonumber - Vedere il valore corrente
:set number? - Risettare a valore di default
:set number&
I settaggi possono essere booleani, come nell'esempio sopra, o avere un valore. Esempio::set tabstop=4 - setta il Tab a 4 caratteri
I settaggi possono essere abbreviati a stringhe univoche:
:se nu=:set number:se nonu=:set nonumber
Per impostare dei settaggi che vengono eseguiti ad ogni sessione di 'vi', inserirli nel file ~/.vimrc della directory di login, senza i : (due punti)
.vimrc- vim run commands - comandi di lancio del vim
Altri Editors

Vi sono innumerevoli altri editor e ambienti di sviluppo software in Linux.
Per chi usa un editor saltuariamente, per l'editazione di soli file di configurazione, tale editor deve essere facilmente installabile,
intuitivo (sequenze di controllo tradizionali) e usabile da CLI e da collegamento remoto.
Un tale nuovo editor è micro, Open Source, disponibile su https://github.com/zyedidia/micro
Micro è un editor scritto in Go. Il suo comportamento è intuitivo ed è simile a quello dell'editor di Linux nano.
Micro ha le seguenti caratteristiche principali:
- è un editor per terminale, non grafico
- ha supporto per il mouse
- è un editor non modale: tutto quello che si scrive va nel testo
- i comandi sono soprattutto basati su sequenze
Ctrl-x - i comandi sono ridefinibili
- ha svariati schemi di colore
- supporta il syntax highlighting di vari linguaggi moderni, tra cui naturalmente il Go
- ha numerosi plugins per funzionalità aggiuntive
Uso di Base di micro
Lancio
Sintassi:
micro [opzioni] [file]
Se il nome del file non è fornito, verrà richiesto
all'atto del salvataggio.
Vi sono molte opzioni per il settaggio immediato
di configurazioni. Per vederle:
micro -h
Tutto quello che si scrive è inserito immediatamente nel buffer di
editazione: non è modale.
Sono indicati di default i numeri di linea.
Comandi di salvataggio
Ctrl-Ssalva il fileCtrl-Qesce. Se il file è stato modificato chiede se salvarlo.Ctrl-Oapre un file. Si apre la linea di comando per il nome del file. IlTABdà autocompletamento.Escinterrompe il comando corrente
Comandi di movimento
Le frecce si spostano nelle quattro direzioni. AnchePgUp e PgDown funzionano come atteso.
Si può usare il mouse per un posizionamento immediato.
Inoltre:
Ctrl-Leftva a inizio rigaCtrl-Rightva a fine rigaCtrl-Upva a inizio fileCtrl-Downva a fine fileAlt-Rightva all'inizio della parola seguenteAlt-Leftva all'inizio della parola precedenteCtrl-Lva a riga, chiede numero
Comandi di Delete
Backspacecancella all'indietroDelcancella in avantiCtrl-Backspacecancella fino a inizio rigaShift-Ctrl-Leftcancella fino a inizio rigaCtrl-Delcancella fino a fine rigaShift-Ctrl-Rightcancella fino a fine rigaShift-Ctrl-Upcancella fino a inizio fileShift-Ctrl-Downcancella fino a fine fileCtrl-Zundo, multilivelloCtrl-Yredo
Comandi di Copy&Paste
Si può selezionare il testo col mouse.
Con i comandi:
Shift-direzioneseleziona in quella direzioneCtrl-Aseleziona tuttoCtrl-XcutCtrl-CcopyCtrl-VpasteCtrl-Kcut dell'intera rigaCtrl-Dduplicazione delle riga correnteAlt-Upmuove la linea in suAlt-Downmuove la linea in giù
Attenzione:
Per poter eseguire il Cut & Paste tra Micro ed un'altra finestra dell'ambiente linux occorre aver installato il pacchetto xclip.
sudo apt install xclip
Comandi di ricerca
Ctrl-Fricerca: chiede stringaCtrl-Nripete ricerca in avantiCtrl-Pripete ricerca all'indietroEscesce dalla ricerca
Altri comandi
Ctrl-Eesegue comando esteso microCtrl-Besegue comando shellCtrl-Gapre la finestra di aiutoCtrl-Qper uscire dalla finestra di aiuto
L'editor 'ed'

Per completezza, interesse e possibiltà d'uso in procedure shell, vengono qui illustrati i comandi di 'ed', il più antico degli editor di Unix.
'ed' è un editor di linea, con pochi comandi, tipicamente di una sola lettera, ma con prefissi e suffissi
Anche 'ed' è un editor modale.
Simboli di indirizzamento
.- linea corrente$- ultima linea del buffern– la linea n (numero)-o^- linea precedente-no^n– n linee prima della corrente (numero)+- linea seguente+n– n linee dopo la corrente,o%- tutto il buffer ( come1,$);- da linea corrente a fine buffer ( come.,$)/re/- ricerca avanti a linea con espressione regolare re?re?- ricerca indietro alla linea con re'm– alla linea precedentemente marcata con m
Comandi principali di ed
Singola lettera con modificatori seguita da Enter.
Molti ammettono un range di linee a cui applicare il comando, poste prima e senza spazi - il default è indicato tra parentesi (le parentesi non si mettono nel comando)
(.)a– append dopo linea corrente5a- append dopo la riga 5+3a- append tra tre righe in avanti
(.)i– insert prima di linea corrente1i- insert a inizio file
I comandi i e a passano a modalità inserimento. Per uscirne e tornare a modalità comando inserire . (punto) da solo a inizio nuova riga
Altri comandi:
(.,.)d– elimina linea o range di linee.,+5- elimina 5 righe incluso quella corrente
(.,.)c– elimina linea/e e inserisci (cambia linea)(.,.+1)j– unisce linea seguente a corrente(.,.)m(.)- muove a linea indicata(.,.)t(.)- copia a linea indicata
ed: scrittura e lettura file
(1,$)w– salva il file correntew- salva tutto il file
(1,$)w file– scrive il buffer al file (rimpiazza se esiste)1,10w /tmp/z- salva le prime 10 linee del file- il file corrente non cambia nome
(1,$)W file– append del buffer al fileq– quit; se il file è modificato segnala con?, e la ripetizione delqabbandona senza salvareQ– quit senza salvare e senza pronto(1,$)wq file– salva al file ed escewq- salva il file corrente ed esce
(1,$)w !comando– scrive il buffer allo standard input del comando($)r file– inserisce nel buffer il file alla fine di default.r file- inserisce nel buffer il file indicato alla linea corrente
($)r !comando– inserisce nel buffer lo standard output del comandoe file– edita il file nuovo; dare dopo il salvataggioE file– quit senza salvare ed edita il file nuovoe !comando– edita lo standard output del comandof file– cambia nome al file corrente(.,.)p– lista (stampa a video) le linee indicate, senza interruzioni(.,.)l– lista le linee (--More-- se più schermi)(.,.)n– lista con numeri di linea
ed: comandi di sostituzione
(.,.)s/re/nuova_stringa/- rimpiazza l'espressione regolare re con la nuova stringa (prima occorrenza sulla linea trovata)(.,.)s/re/nuova_stringa/n– _n_esima occorrenza sulla linea trovata(.,.)s/re/nuova_stringa/g– tutte le occorrenze sulla linea trovata(.,.)s– ripete l'ultima sostituzione sulla linea correnteu– undo dell'ultimo comando di modifica (singolo livello di undo)(.,.)g/re/comando– applica il comando alle linee contenenti l'espressione regolare re indicata(.,.)v/re/comando- applica il comando alle linee non contenenti re
Espressioni regolari
-
stringa– la stringa indicata- non deve contenere caratteri riservati
-
c– ogni singolo carattere c non riservato -
.- ogni singolo carattere -
[xyz]– singolo carattere tra quelli indicati tra le quadre -
[^...]– escluso i caratteri indicati -
[x-y]– singolo carattere nel range ASCII -
[:classe:]- carattere della classe indicata[:alnum:] [:alpha:] [:blank:] [:cntrl:]
[:digit:] [:graph:] [:lower:] [:print:]
[:punct:] [:space:] [:upper:] [:xdigit:] -
[^:classe:]- carattere non nella classe indicata -
^- inizio linea -
$- fine linea
Ripetitori, seguono il carattere
?- zero o una ripetizione+- una o più ripetizioni*- zero o più ripetizioni{n}- esattamente n ripetizioni{n,}- n o più ripetizioni{m,n}- tra m ed n ripetizioni
Sottoespressioni
Una sottoespressione è racchiusa tra tonde precedute da b_backslash_: \(re\)
\n– numero n della sottoespressione sulla linea- p.es.:
\([xy]\)\1– xx oppure yy
- p.es.:
I Processi
Secondo la 'visione del mondo' di Unix, vi sono due componenti del sistema operativo: i processi e i file
Processo
E' l'esecuzione di un programma eseguibile. E' attivo, ha uno stato di esecuzione, consuma risorse come CPU, RAM, disco, rete. Un processo è un gestore di risorse. Il processo non è il programma. Puù processi possono essere instanziati dallo stesso programma e in esecuzione simultanea.
Il sistema Unix/Linux è:
- Multiuser - naturalmente più utenti possono essere simultaneamente connessi al sistema ed avere attività in corso
- Multiprocesso - più processi sono in esecuzione simultanea, ciascuno con la propria identità
- Multitasking - ogni processo è schedulato su più CPU, ed e composto da sottounità, dette task o threads, eseguite indipendentemente e simultaneamente
I processi non devono essere totalmente isolati, è previsto che i processi comunichino tra loro, tramite più dispositivi di sistema, collettivamente noti come Inter Process Communication.
Nei Linux moderni, i servizi sono costituiti da Cgroups, gruppi di processi in cooperazione tra loro.
File
E' qualsiasi elemento venga gestito da un processo, in due modi: lettura o scrittura.
Non vengono coperti solo i file tradizionali, ma anche i dispositivi periferici, le reti, i terminali, ecc.
Tutto quello che non è un processo è un file. Tutto quello che viene gestito con le funzioni primitive di sistema dei file, è un file.
Ciò significa che vi possono essere anche file, cosiddetti esotici, che non occupano spazio disco, ma sono comunque gestiti come file.
I file sono mantenuti in un File System, che può corrispondere ad una partizione disco, più partizioni, essere remoto in rete, essere anch'esso esotico.
Si è ottenuta col tempo una notevole virtualizzazione dei file e file system, con svariati livelli di indirezione prima di arrivare ai very bytes.
Processi e Memoria
Gestione della Memoria
La RAM è gestita in due modalità diverse e separate.

- sys - contiene tutte le strutture di sistema, incluso il kernel e i suoi processi, le tabelle del kernel, i protocolli di rete, i device drivers, ecc.
- usr - contiene i processi uente, i buffers di I/O dei processi utente, le cache, ecc.
Le due regioni non sono necessariamente contigue.
L'unico modo che gli elementi in system mode e in user mode hanno per comunicare tra loro sono le system calls.
La Memoria Virtuale
E' la memoria indirizzabile da un registro della CPU. Con 64 bit, gli indirizzi di memoria virtuale vanno da 0 a 2^64-1 (solitamente espressi in esadecimale per convenienza).
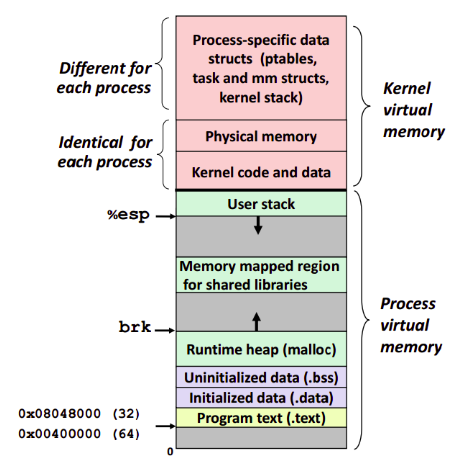
Lamemoria virtuale è suddivisa in regioni:
- text - per il codice eseguibile dei programmi o librerie
- data - per i dati statici, allocati durante la compilazione dei programmi
- stack - per gli stack frames dei programmi; ogni funzione o blocco di codice si vede allocato uno stack frame
- heap - per i dati allocati dinamicamente dai programmi a runtime
All'atto del caricamento (da parte del linker-loader), ogni eseguibile si vede allocato un certo numero di segmenti nelle varie regioni in memoria virtuale. Gli indirizzi dei segmenti di un eseguibile non sono in collisione con i segmenti di un altro eseguibile, tranne in due casi:
- segmenti condivisi - shared memory per la comunicazione volontaria tra loro
- librerie condivise - shared objects linkati dinamicamente. Le libreria dinamiche sono visibili allo stesso indirizzo in memoria virtuale di tutti i programmi che le hanno linkate.
L'insieme di tutti i segmenti di un processo è la memory map del processo.
A runtime, un processo non può accedere ad altri che i suoi segmenti o quelli condivisi. Il tentativo di farlo produrrebbe una condizione detta Segment Violation e la terminazione immediata del processo colpevole.
In particolare l'indirizzo zero di memoria virtuale non è mai nella mappa di nessun processo, così l'uso di un puntatore non inizializzato produce un segment violation.
A runtime, non vi è spazio, nella RAM fisica, per tutti i segmenti di tutti i processi in esecuzione. Vengono instanziati in RAM solo un certo numero di pagine (estensioni di 4 KB l'una) dei segmenti in uso in quel momento dal processo. Il meccanismo si chiama Demend Paging ed è gestito dal processo del kernel detto Memory Mapping Unit.
La dimensione in memoria virtuale dell'intera mappa di un processo si chiama VSZ (Virtual Size). La somma totale di occupazione RAM da parte di tutti i segmenti di un processo in un determinato istante si chiama RSS (Resident Set Size).
Evidentemente: VSZ >= RSS.
Solo i processi in user mode 'giocano' a Memoria Virtuale. I processi del Kernel, che sono in system mode sono sempre residenti in RAM. I processi del kernel non hanno VSZ e RSS.
Tabella dei processi
Il kernel mantiene una Process Table di tutti i processi attivi al momento. Ogni processo è decritto da un record (slot in gergo) di questa tabella. La chiave è il PID. I campi notevoli sono:
- PID - Process IDentifier - numero intero univoco allocato al processo al suo caricamento
- PPID - Parent PID - identificativo del processo che ha lanciato il processo corrente (Italiano: processo padre)
- utente e gruppo possessori - con i cui permessi opera il processo
- puntatore alla u_area - da cui reperire tutte le altre informazioni sul processo
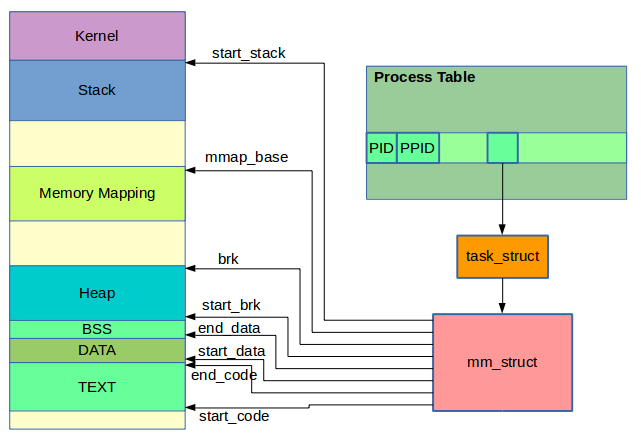
Ogni PID ha un PPID (un figlio ha sempre un padre), ma ogni PPID può avere più PID figli. L'intero insieme di processi in un determinato istante è stato generato al boot di sistema tramite vari files di configurazione, a partire dal primo processo utente, col PID numero 1, che è stato lanciato dal kernel stesso.
Il processo capostipite si chiamava init in Unix e nelle (non così) vecchie versioni di Linux, e si chiama systemd nelle ultime versioni di Linux.
Il comando 'ps'
Process Status (ps) permette di vedere le informazioni relative ai processi attivi.
Nota:
Il trattino indicativo di opzione è stato introdotto in Unix System V. Berkeley Unix non aveva questa convenzione; le opzioni (allora dette flags) esistevano comunque però, ma erano singole lettere senza trattino davanti.
Linux ha il comando ps che viene con un insieme di opzioni col trattino - e producono un output stile System V, e quelle senza trattino, che producono un output stile Berkeley.
Gli insiemi di opzioni sono completamente diversi e producono output diversi, anche se un paio (purtroppo) si assomigliano.
Dato che il kernel di Linux è molto più vicino come parentela a Berkeley che non a System V, sono da preferirsi le opzioni senza trattino.
Le opzioni principali di ps sono:
ps- Processi locali dell'utenteps w- Formato 'largo' - più informazioni, incluso vettore di lancio completops l- Formato 'lungo' – informazioni architettonicheps a- Tutti i processi associati a terminale – anche di altri utentips ax- Anche i processi senza terminale di controllops wax- Rapporto completo largops lax- Rapporto completo lungo
Quest'ultimo produce praticamente tutte le informazioni disponibili su tutti i processi di sistema.
Terminale di controllo
Ogni procwsso che è stato eseguito poichè qualcuno ha digitato un comando da un terminale, ha quello come Terminale di Controllo.
Non è tanto il dare Ctrl-C o Ctrl-Z o altri tasti che contraddistinguono il terminale di controllo.
La verà proprietà è che al venir meno del terminale di controllo tutti i suoi processi sono terminati d'ufficio.
Ai bei tempi gli utenti si collegavano alla Unix Box del centro di calcolo tramite linee telefoniche insicure. Durante il collegamento avevano consumi RAM, disco e CPU, che gli venivano fatturati a fine mese. Se per caduta del collegamento telefonico, SIP o altri, il programma avesse continuato a girare, sarebbe stato un costo, e inoltre l'utente non avrebbe più visto l'output.
Vi sono innumerevoli processi utente che non hanno terminale di controllo, poichè non sono stati lanciati manualmente, ma tramite files di configurazione dai processi di boot. Per esempio i database server, i server di comunicazione, e tutti gli altri servizi.
Questi processi si chiamano demoni e NON sono processi di sistema, poichè comunque lavorano in user mode.
Un altro punto di terminologia. I demoni e i servizi non coincidono, solo al limite per i servizi più semplici. Normalmente un servizio è implementato da un certo numero di demoni cooperanti,cioè raccolti in un Cgroup.
L'organizzazione dei servizi Linux è completamente differente da Windows. In Windows (fino a 10), alcune cose di Linux come i containers, semplicemente non si possono fare perchè manca il supporto architettonico.
Controllo Job e Processi
Processi in Background
Il comando, per esempio:
$ sleep 2000 &
[1] 7145
$
- manda il processo in background
- ritorna subito il pronto
Nell'esempio indicato il simbolo $ denota il pronto, e non è da digitare.
I due numeri tornati nel rapporto sono:
- JID - Job ID - tra parentesi quadre
- PID - Process ID - dopo le quadre
Il PID è globale di sistema, il JID è locale di terminale. Processi in background lanciati su terminali diversi producono la stessa sequenza di JID.
Attenzione perchè il processo continua a leggere e scrivere su terminale, se ne ha bisogno. L'esempio sopra è didattico, in un caso vero bisogna anche preoccuparsi delle eventuali redirezioni di input, output ed errori, prima di lanciare un processo in background.
Fermare i processi
Se improvvisamente dovessimo terminare una partita a scacchi interattiva su un terminale (si faceva una volta, perchè è sorto un problema urgente che richiede il terminale, ci dispiacerebbe battere Ctrl-C, specie se stavamo vincendo noi.
Si può battere Ctrl-Z, che invia al processo il segnale di 'sospensione' (susp - controllare con stty -a). Questo lo pone nello sato particolare 'Stopped', da cui può poi essere fatto ripartire.
Job Control
Vi possono essere più job in stato Stopped, così come più jobs in Background. Il modo interattivo si chiama ora Foreground.
Un ulteriore stato detto Terminated indica i job terminati.
Per listare tutti job sospesi o in background:
jobs
Nel rapporto il simbolo + indica il job di default e il - il prossimo. Il numero associato n è il JID.
Comandi:
fg %n- porta in Foreground il job n, da Background o Stoppedfg- porta in foreground il job di default
bg %n- porta in Bachground il job n, da Stoppedkill %n- porta a Terminated il job n, da Background o Stopped
Il diagramma a stati indicato si chiama Job Control ed è un servizio offerto dalla shell, non dal sistema (la shell originale, di Bourne, non ce l'ha).
E' disponibile anche il settaggio di terminale tostop (_Terminal Output Stop). Dare il comando
stty tostop
fa sì che quando un processo in background tenta di scrivere a terminale, il processo viene portato d'ufficio in modalità Stopped.
Il contrario è: stty -tostop.
Esempio
$ sleep 2000 &
[1] 27402
$ sleep 3000 &
[2] 27406
$ sleep 4000 &
[3] 27407
$ sleep 5000
^Z
[4]+ Stopped sleep 5000
$ jobs
[1] Running sleep 2000 &
[2] Running sleep 3000 &
[3]- Running sleep 4000 &
[4]+ Stopped sleep 5000
$ ps w
PID TTY STAT TIME COMMAND
27384 pts/1 Ss 0:00 bash
27402 pts/1 S 0:00 sleep 2000
27406 pts/1 S 0:00 sleep 3000
27407 pts/1 S 0:00 sleep 4000
27408 pts/1 T 0:00 sleep 5000
27411 pts/1 R+ 0:00 ps w
$ kill %1
$
[1] Terminated sleep 2000
$ kill 27406
$
[2] Terminated sleep 3000
$ kill -9 27408
[4]+ Killed sleep 5000
$
Nell'esempio:
- Vengono lanciati tre job in background
- Viene lanciato un job in forground
- Il job in foreground viene interrotto con
Ctrl-Z - Vengono listati i jobs col comando
jobs - Vengono listati i processi col comando
ps w(largo) - Viene terminato un job tramite Job Control
- Viene terminato un processo tramite
kill PID- Notare che in entrambi i casi occorre battere Invio una seconda volta prima che la shell dia il rapporto di terminazione
- Viene terminato un processo tramite
kill -9 PID- Notare che il rapporto arriva subito, ed è Killed, non più Terminated (non era un eufemismo, ma un termine tecnico preciso)
Segnali
Uno dei meccanismi di Inter Process Communication sono i segnali.
Un segnale è un messaggio semplice con semantica predefinita a seconda del suo identificativo (come le bandiere di segnalazione marittima). Il segnale può essere inviato ad un processo
- dal kernel - segnale di sistema - per indicare anomalie; p.es. Segment Violation è un segnale
- da un altro processo - segnale utente - usando ilkernel come intermediario
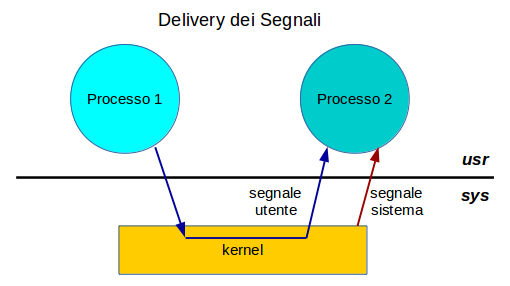
NB: i segnali sono, per forza di cose, asincroni. Quando il processo inviante è attivo, non necessariamente lo è anche il processo ricevente, specie con una sola CPU. E' il kernel che 'recapita' il segnale quando il ricevente diventa attivo nella CPU.
Un processo non aspettaun segnale, lo riceve come 'evento'.
Linux ha una ricca collezione di segnali, più di 30. Alcuni di rilievo sono:
| num | nome | significato |
|---|---|---|
| 1 | hangup | il terminale di controllo non è più connesso |
| 2 | interrupt | l'utente ha premuto Ctrl-C |
| 3 | quit | l'utente ha premuto Ctrl-\ |
| 4 | illegal operation | il processo ha tentato una divisione per zero o altra operazione impossibile |
| 9 | kill | il processo è stato 'ucciso' |
| 10 | usr1 | a disposizione dei programmatori |
| 11 | segment violation | il processo ha tentato un accesso fuori mappa |
| 15 | terminate | il processo riceve una richiesta di terminazione |
Per avere una lista completa dei segnali, linux fornisce il comando kill -l.
Quando un processo riceve un segnale ha a disposizione tre comportamenti:
- default - spesso, morire
- ignorarlo - un processo setta una maschera dei segnali che intende ricevere, (quasi) tutti gli altri sono ignorati
- gestirlo - un processo ha registrato una funzione di callback per ogni segnale che non ignora, e viene invocata alla ricezione del segnale
Tutti i segnali si possono ignorare o gestire, tranne il 9 (kill), alla ricezione del quale si può solo morire.
Ogni (bravo) programmatore Linux deve fornire una procedura di gestione per il segnale 15 (terminate), che gli dia modo di chiudere eventuali file aperti o connessioni, rilasciare risorse, salvare lo stato se necessario, e poi terminare di propria iniziativa.
Quanto sopra è tanto più vero quando un processo è in un Cgroup, che condivide le risorse. In tal caso il processo corrente che termina, deve anche indicarlo al capogruppo.
I processi di un Cgroup che terminano, non vengono immediatamente rimossi dalla memoria, ma rimangono in stato detto Zombie, in attesa che anche tutti gli altri membri del gruppo abbiano terminato. Solo allora il capogruppo rilascia effettivamente le risorse, e tutti gli zombies vengono 'mietuti'.
Il Comando 'kill'
Sintassi:
kill [-segnale] PID
invia il segnale al processo indicato.
Il segnale di default è il 15 (terminate). Questo è il modo in cui si devono terminare i processi.
Solo quando, per motivi runtime, il processo è 'appeso', si può a malincuore inviare kill -9 PID, correndo i rischi inerenti a questo metodo.
Si può inviare un kill -9 solo ai propri processi. Tranne evidentemente che l'amministratore può inviarlo a qualsiasi processo.
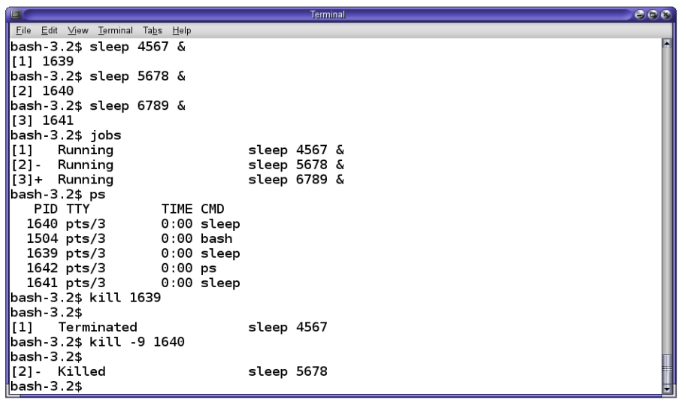
Attenzione:
I servizi di sistema, organizzati in Cgroups hanno procedure di terminazione corretta del servizio, che vengono invocate dal comando systemctl, o service in versioni più vecchie.
Non ammazzare mai processi a caso, componenti di un servizio, o l'intero servizio può trovarsi in uno stato inconsistente.
Il Segnale 'quit'
Se un nostro bellissimo programma è 'appeso', forse in loop infinito, e lo terminiamo con Ctrl-C (segnale di interrupt), il processo termina e noi non sapremo mai perchè era appeso.
C'è la possibilità di terminare il processo in foreground con i tasti `Ctrl-? (segnale di quit) e, con oppurtuna previa disposizione, verrà prodotto un file di Core Dump, contenente lo stato della memoria virtuale del processo all'istante della sua terminazione. (Viene detto anche il cadavere del processo).
Se il programma era stato compilato col supporto al debugger è quindi possibile ispezionare il file di core.
Lasciare i cadaveri a giro è deprecato di default, però.
Limiti di utilizzo risorse
Il comando ulimit -a mostra i limiti di utilizzo risorse per l'utente corrente:
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7385
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 7385
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
$
Per ciascun parametro viene anche indicata l'opzione per cambiarlo.
Un tempo l'amministratore di sistema in un file di configurazione globale, imponeva limiti diversi per utenti diversi, ma questo ambiente è scomparso.
Non vi sono effettivamente limiti: se un parametro non è esplicitamente marcato unlimited, ha comunque un valore di default che è il massimo supportato dal sistema.
Tranne che il 'core file size' che di default è zero. Per cambiarlo:
ulimit -c unlimited
Ora si può provare l'esercizio:
$ ulimit -c unlimited
$ sleep 2000
^\Quit (core dumped)
$ ls -l
total 384
-rw------- 1 mich mich 393216 mar 16 18:29 core
$
Con eventualmente:
$ gdb core
GNU gdb (Ubuntu 7.11.1-0ubuntu1~16.04) 7.11.1
Copyright (C) 2016 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
"/tmp/xx/core": not in executable format: File format not recognized
(gdb) backtrace
No stack.
(gdb) quit
$
Il debugger è gdb, ma non riconosce il file poichè l'eseguibile non era stato compilato col supporto al debugger.
Terminale di Controllo e 'demoni'
Situazione in Ubuntu 16.04
Esempio:
$ sleep 1234 &
[4] 28109
$ ps lax | grep 1234
0 1000 18518 18514 20 0 310804 12344 poll_s S ? 0:00 /usr/share/code/code --type=zygote --no-sandbox
0 1000 28109 27384 20 0 7296 796 hrtime S pts/1 0:00 sleep 1234
0 1000 28111 27384 20 0 14228 1012 pipe_w S+ pts/1 0:00 grep --color=auto 1234
$
Evidentemente grep trova più linee con la stringa 1234. Nella nostra il cammpo TTY vale pts/1 e il campo PPID vale 27384.
Ora chiudiamo il terminale. Poi apriamone un altro e ripetiamo:
$ ps lax | grep 1234
0 1000 18518 18514 20 0 310804 12344 poll_s S ? 0:00 /usr/share/code/code --type=zygote --no-sandbox
0 1000 28109 1488 20 0 7296 796 hrtime S ? 0:00 sleep 1234
0 1000 28367 28350 20 0 14228 1064 pipe_w S+ pts/16 0:00 grep --color=auto 1234
$
Il processo esiste ancora, ma ora:
- il TTY è
?, ovvero non esiste - il PPID è 1488, che a ulteriore investigazione si rivela essere il processo
upstart
Il nostro processo è diventato un demone, che non ha più terminale di controllo.
Su Ubuntu 16.04 LTS tutti i demoni diventano figli del processo upstart.
Situazione in Red Hat Enterprise Linux
La figura seguente indica invece il comportamento su RHEL.
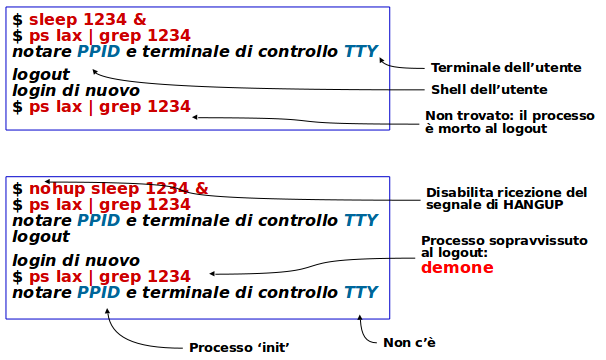
I processi che non hanno più terminale di controllo, di default muoiono.
Per farli continuare a vivere, e diventare demoni, occorre al loro lancio dare il comando shell prefisso nohup:
$ nohup sleep 1234 &
[1] 28509
$ nohup: ignoring input and appending output to 'nohup.out'
$
Questo li stacca già fin dasubito dall'input e ridirigel'eventuale output in un file d'ufficio.
Il comando nohup indica di ignorare il segnale numero 1 - hangup.
i demoni sono immuni a questo segnale.
Per non sprecare un segnale è da (abbastanza) anni ormai invalsa la consuetudine che ricicla il segnale di hangup, quando ricevuto da un demone:
- viene compiuto un warmstart cioè una reinizializzazione del processo senza però terminare e ripartire (che sarebbe un coldstart). Per esempio vengono riletti i file di configurazione.
I File
Un file è tutto ciò che non è un processo.
Non esiste il concetto di device con notazione separata, viene considerato come file speciale.
E' un file tutto quello che si può gestire con le system call di un file. Ciò vuol dire che , oltre ai file regolari e alle directories, che occupano spazio disco, vi è tutta una serie di cosiddetti file speciali (devices, link simbolici, socket).
I files sono molto importanti in Linux, perchè tutti i processi operano su di loro. Sono possibili tre operazioni sui file, a seconda della loro natura e dei loro permessi:
- lettura
- scrittura
- esecuzione
File
Il concetto di 'file' viene originariamente dal Linguaggio C, che è piuttosto antico. Il paradigma è molto potente, ma alquanto datato.
Altri sistemi operativi, come Mac e Windows, che sono scritti in C++, hanno una struttura interna differente dei file.
Un file è una sequenza indeterminata di bytes, uno stream, da zero a teoricamente infiniti, controllato da una struttura di controllo, in C: FILE.
La struttura di controllo si trova nella Per-Process File Table, nella u_area del processo corrente.
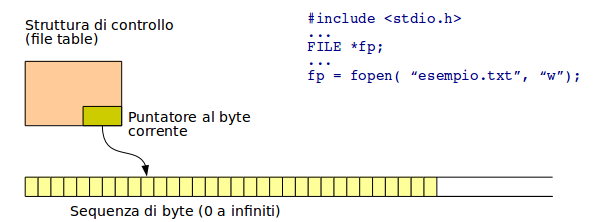
Tipi di file
Il sistema Unix nativamente non deduce il tipo di file dal suffisso del suo nome, o da etichette inserite nell'inode o nella entry di directory.
Unix deduce il tipo dai primi caratteri del file stesso, due o quattro o fino ad otto caratteri, che costituiscono l'etichetta o numero magico del file.

UNIX cerca
- il numero magico – primi 2 o 4 byte, che informa sul tipo di file
- il blocco di controllo – n bytes a seguire, dipende dal numero magico: fornisce dettagli sul tipo di file e sulle sue proprietà
Per esempio, tutti i file eseguibili cominciano con il numero magico
\01FF E L F, ove \01FF è il primo byte scritto in ottale, e sono tutti bit settati ad uno.
Unix è così vecchio che non avevano ancora l'abitudine di indicare i byte in esadecimale. Si usava ancora la notazione ottale.
Ma per quanto vi sia un solo standard di produrre eseguibili in Unix, vi sono molti dettagli che dipendono dall'architettura specifica:
- 32 o 64 bit
- interi in formato Big Endian (MSB - IBM) o Little Endian (LSB - Intel)
- link statico o dinamico
- tipologia del link dinamico
- versione minima delle System Calls
- se vi sia o no la tabella dei simboli
Tutti questi dettagli sono contenuti nel blocco di controllo, che segue l'etichetta. E' in formato binario e occorre un disassemblatore specifico.
Comando file
Sintassi:
file nomefile
Disassembla il blocco di controllo quando applicato a un file eseguibile, dando informazioni dettagliate a video.
Esempio:
file /usr/bin/passwd
I file eseguibili
Creiamo un file in linguaggio C, editando ciao.c col nostro editor preferito:
#include <stdio.h>
int main(){
printf("Ciao\n");
return 0;
}
Compiliamolo con:
gcc -o ciao ciao.c
L'opzione -o ciao indica che l'eseguibile deve chiamarsi ciao. Senza tale opzione, l'eseguibile si chiamerebbe di default a.out.
Se non vi sono errori nel programma, non vengono dati messaggi.
Verifichiamo che l'eseguibile esiste con ls ciao.
Lanciamolo con ./ciao.
Guardiamo il contenuto del file col dumper ottale (antichissimo):
od -c ciao | less
L'opzione -c indica di tradurre in ASCII tutti i byte stampabili. Il filtro less ci mostra la prima pagina di output. Uscire da less col comando q quando abbiamo finito di ispezionarlo.
Si nota subito l'etichetta (o numero magico): \01FF E L F.
Nota di colore:
E L F in teoria vuol dire Extensible Link Format. In realtà è un silenzioso ringraziamento agli Elfi, senza l'aiuto dei quali, come ogni programmatore di un tempo sapeva, Unix non avrebbe mai visto la luce.
Proviamo a disassemblare il blocco di controllo:
file ciao
Il risultato è:
ciao: ELF 64-bit LSB executable, x86-64, version 1 (SYSV),
dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2,
for GNU/Linux 2.6.32, BuildID[sha1]
=429459a48a14a82e318be5951f8df6f3ecd53e9e, not stripped
Qui not stripped si riferisce alla presenza della tabella dei simboli all'interno del codice. Serve per eventualmente:
- aiutare nel debugging e nel disassemblaggio
- usare il programma corrente come modulo di compilazione di un programma più grande
Per visualizzare la tabella dei simboli il comando è nm ciao:
0000000000601038 B __bss_start
0000000000601038 b completed.7585
0000000000601028 D __data_start
0000000000601028 W data_start
0000000000400460 t deregister_tm_clones
00000000004004e0 t __do_global_dtors_aux
0000000000600e18 t __do_global_dtors_aux_fini_array_entry
0000000000601030 D __dso_handle
0000000000600e28 d _DYNAMIC
...
Se non vogliamo che il file eseguibile sia ulteriormente compilato, o ispezionato, si può togliere la tabella dei simboli, col comando:
strip ciao
Ora il tentativo di ispezionarla fallisce:
$ nm ciao
nm: ciao: no symbols
E il comando file ciao ritorna:
ciao: ELF 64-bit LSB executable, x86-64, version 1 (SYSV),
dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2,
for GNU/Linux 2.6.32, BuildID[sha1]
=429459a48a14a82e318be5951f8df6f3ecd53e9e, stripped
Librerie dinamiche
Se un file è linkato dal compilatore con altre librerie, il link è dinamico di default:
- il codice delle altre librerie non è inserito all'interno del codice dell'eseguibile, solo dei riferimenti ad esse
- tutte le librerie dinamiche di sistema sono registrate ad un preciso indirizzo in Memoria Virtuale dal comando
ldconfiglanciato all'atto del boot di sistema - a runtime, il nostro eseguibile vede automaticamente caricate le librerie con cui è linkato, nel suo spazio di indirizzi virtuali, ovvero nella sua Mappa dei Segmenti.
- programmi diversi che sono linkati con la stessa libreria dinamica, la vedono allo stesso indirizzo virtuale
- la libreria è caricata una sola volta, dal sistema non dall'eseguibile: è uno Shared Object (oggetto condiviso)
- tutti i file di libreria dinamica hanno il suffisso
.so(+ numero di versione)[è un vago equivalente architettonico del.DLLdi Windows]
Se un file è linkato staticamente con delle librerie, all'atto della compilazione con opportune opzioni:
- tutte le funzioni di libreria riferite dal programma hanno il loro codice inserito nel codice del programma eseguibile
- ogni eseguibile statico a runtime le carica nel suo spazio privato di indirizzamento
- questo provoca un notevole spreco di RAM e di disco
- i programmi statici sono però molto più facilmente portabili ad altre istanze di Linux: non c'è da portare anche le librerie
Sia che un file non venga linkato con alcuna libreria, come nel nostro esempio, sia che venga linkato staticamente, ha sempre tre o quattro librerie dinamiche d'ufficio.
Nel nostro esempio le possiamo vedere col comando:
ldd ciao
che produce:
linux-vdso.so.1 => (0x00007fffe8ffe000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f07279b0000)
/lib64/ld-linux-x86-64.so.2 (0x0000560915c47000)
Il numero esadecimale tra parentesi è l'indirizzo della libreria in memoria virtuale, preregistrato al boot da ldconfig.
Tali librerie sono:
libc- la libreria delle System Calls (Standard C Library), con cui il programma può compiere richieste di servizi al Kernellinux-vdso- (Virtual Dynamic Shared Object) la libreria di cittadinanza, con cui il programma può interagire con l'intero Ambiente Operativo - contiene dettagli che cambiano abbastanza spesso nelle release di Linuxld-linux- la libreria Loader: il suo compito è di trasformare un file eseguibile in un processo in esecuzione, caricando l'ambiente di schedulazione
Un esempio di file compilato staticamente, in Go, è il seguente:
$ ldd ~/bin/micro
linux-vdso.so.1 => (0x00007ffdc79f0000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0
(0x00007f630e1c6000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f630ddfd000)
/lib64/ld-linux-x86-64.so.2 (0x00005613dff8f000)
In questo esempio vi è anche la libreria libpthread, che dà il supporto al multithreading. Tutti i programmi Go sono multithread.
Il File System Hierarchy
Il FileStore
E' l'albero globale di tutte le directory e i file visibili
- E' l'unione di più file systems
- Tramite operazione di 'mount'
- Solo l'amministratore può eseguire il mount
- Ogni file system è montato sotto una directory
Non esistono identificativi di drive stile A: B: C: ecc.
- Tutto è visibile sotto un'unico albero delle directory
- La directory principale è la directory radice - root -
/- In alcuni sistemi operativi (Solaris) è la directory di login dell'utente 'root'
Il nome FileStore in realtà non è più usato.
Ora si tende a chiiamarlo File System Hierarchy (FSH) o anche solo il File System per antonomasia
E' molto importante differenziare tra i termini:
- File System - il contenuto organizzato di una partizione, reale o virtuale
- FHS - la gerarchia di File <Systems organizzati in un unico albero
Tutti i sistemi operativi Unix/Linux a livello directories principali - sotto la radice - hanno alcune directories standard con scopi definiti (FHS Standard):
bin- eseguibili principali di sistemalib- librerie principalitmp- files temporanei e labilietc- files di configurazionedev- files speciali identificanti lo hardwarevar- files ad elevata variabilitàusr- componenti e programmi aggiuntivi rispetto al minimo di releaseexport- files condivisibili in rete (nonsempre c'è)home- contenente le sottodirectories di login degli utenti
File System
Organizzazione dei file in un contenitore.
Questo può essere:
- Fisico - contenuto in una partizione di disco o altro dispositivo di storaggio
- Logico - fisicamente organnizato su più partizioni o dispositivi di storaggio, p.es. in rete, ma visibile e accessibile come unico file system
- Virtuale - organizzazione simile a un file system (gestita dalle opportune system calls), ma contenente file speciali che non occupano spazio fisico - Anche detto File System 'Esotico'
- Es. file system
proc- dei processi, file systemshm- della memoria condivisa, file systems in RAM, ecc.
- Es. file system
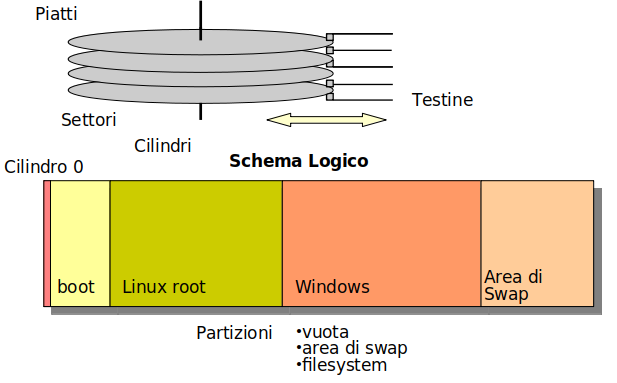
Mentre un disco fisso è unastruttura tridimensionale, viene di solito rappresentato come una 'scatola' divisa in partizioni.
Il loro numero e gestione a basso livello dipende dal firmware di sistema. Con il caro vecchio BIOS vi erano quattro partizioni primarie di cui una poteva contenere ulteriori partizioni estese.
Il numero di tipi diversi di file system riconosciuti da Linux è notevole:
| Nome | Tipo |
|---|---|
| Minix | antico FS Linux |
| Ext2 | FS standard |
| Ext3 | FS standard con journalling (Red Hat 5.x) |
| Ext4 | FS standard ultimo (Red Hat 6.x) |
| Reiser | nuovo FS con journalling (Slackware) |
| GFS | Global FS (Red Hat – per clusters) |
| ISO9660 | CD e DVD (molte varianti) |
| FAT e VFAT | vecchio DOS e nuovo Windows |
| NTFS | nuovo Windows (RH: solo lettura) |
| UFS | Unix FS (Solaris) |
| XFS | Silicon Graphics, ora il default in Red Hat 7.x |
Il numero di FS riconosciuti dipende dalla presenza o meno di device drivers
Alcuni file systems sono proprietari, e alcune distribuzioni enterprise di Linux non hanno la licenza di accedervi pienamente.
Altri sono soggetti a licenza.
Non viene considerata una buona idea utilizzare un file system che non sia Open Source.
Rapporti d'uso del File System
# fdisk -l /dev/sda- Lista le partizioni se boot BIOS (privilegiato)
# parted → print → quit- Lista le partizioni se boot EFI (privilegiato)
$ df -h- Rapporto su spazio usato da ogni file system
$ du -s directory- Spazio totale usato dalla directory
Gli esempi indicano con un # che sono richiesti privilegi amministrativi per il comando, e con $ la possibilità di darlo come utenti comuni.
Struttura di un File System
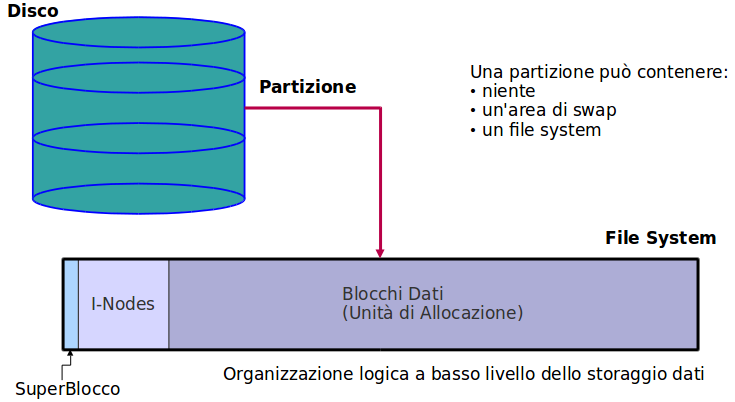
Il diagramma è illustrativo e in realtà non esiste nessun file system specifico che abbia questa struttura interna.
Vi sono essenzialmente tre elementi importanti di un File System:
- il superblocco - che contiene l'indice o sommario di tutto il file system, e i puntatori alle varie zone
- la tabella degli i-node - strutture ciascuna delle quali gestisce un file
- i blocchi dati - le unità di allocazione dei file
Il superblocco è critico per la integrità, e in sua assenza nessun dato sarebbe più accessibile. Tutti i file system moderni hanno accorgimenti per replicare parecchie volte il superblocco.
I blocchi dati sono tipicamente di dimensione 4 KB, variabili forse da 1 a 8 KB. Alcuni file systems non usano blocchi di dimensione fissa ma estensioni di dimensioni variabili. Lo spreco medio è di mezzo blocco per file. Un tempo ci si preoccupava dello spreco ed esistevano degli algoritmi bizantini per la gestione di 'frammenti' di un blocco, per l'allocazione dei file. Ora il disco fisso è economico, i file sono più grandi, e non c'è più la preoccupazione di ottimizzare lo spazio disco.
Ogni i-node gestisce un file. Senza gli i-node non sarebbe possibile allocare file anche con spazio disco sufficiente. Fortunatamente i file system moderni allocano tanti i-node quanti sono i blocchi dati disponibili.
Alcuni file system mantengono gli i-nodes in una struttura ad albero bilanciata, per massimizzare l'efficienza in lettura. Altri sparpagliano appositamente gli i-node per minimizzare la frammentazione. Ogni file system ha algoritmi propri di gestione che migliorano alcuni campi architettonici, ma non tutti.
Come il motto della Nasa: "Faster, Cheaper, Safer. Choose two."
i-Node
Un i-node in Ext2-Ext4 ha la struttura indicata.
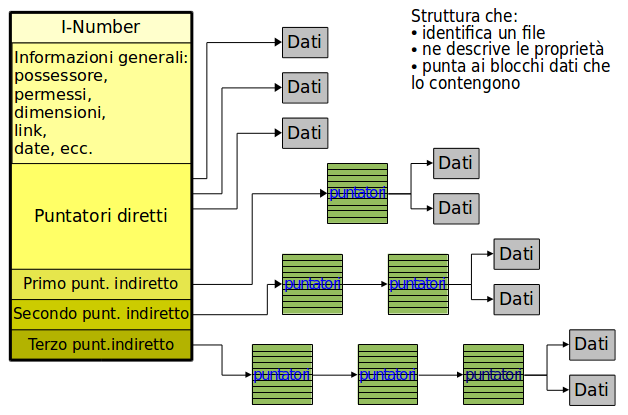
Il campo chiave è lo i-number, intero univoco nel file system.
Notare, non univoco nel FSH, ci possono essere file diversi con lo stesso i-number, ma in file system diversi tra quelli che compongono il FHS. Il campo i-number per antonomasia viene anche detto solo lo i-node.
Lo si può vedere dando il comando ls con l'opzione -i.
La prima sezione di un i-node contiene le informazioni su file:
- utente possessore
- gruppo possessore
- dimensione in bytes
- permessi d'accesso
- numero di riferimenti
- date di creazione, modifica, accesso
- ecc.
Sono tutte informazioni visualizzabili col comando ls e le sue varie opzioni.
La seconda sezione contiene i puntatori ai blocchi dati.
I primi (circa 10) sono puntatori diretti ai primi blocchi del file.
Segue un puntatore indiretto, che punta ad un blocco di puntatori.
Segue un secondo puntatore, doppiamente indiretto, che punta ad un blocco di puntatori, ciascuno dei quali punta ad un secondo blocco di puntatori.
Se ancora non bastasse, un altro puntatore successivo compie tre livelli di indirezione.
Directory
Si è notato che il nome di un file non è conservato nell'i-node.
L'elemento di file system che contiene il nome del file è la directory.

E' un file normale ma strutturato come tabella a due colonne:
- il numero dell'inode
- il nome del file corrispondente
Comandi sui File
I comandi sono di due tipi:
- comandi interni della shell
- comandi esterni, file eseguibili
I comandi interni della shell Bash sono numerosi. Per avere la loro lista completa digitare:
help
Per ottenere un (piccolo) aiuto su ciascuno di essi, digitare help comando.
I comandi esterni devono avere il permesso di esecuzione per chi li invoca.
Possono essere:
- un eseguibile binario - viene caricato dalla libreria loader
- una procedura interpretata - viene caricata dall'interprete nel cui linguaggio è scritta
I file di procedura interpretata devono avere a prima linea il costrutto Hash Bang, cioè i caratteri #! seguiti dal Vettore di Lancio dell'interprete per la procedura corrente (percorso completo ed eventuali opzioni).
Le procedure quindi iniziano con, p.es.:
#! /usr/bin/perl
Se lo Hash Bang non è indicato, le procedure vengono passate all'eseguibile descritto dalla variabile d'ambiente SHELL: tipicamente /bin/bash.
Esempio
$ echo "echo Ciao" > saluto1
$ chmod +x saluto1
$ ./saluto1
Ciao
$ echo 'printf("addio\n");' > saluto2
$ chmod +x saluto2
$ ./saluto2
./saluto2: line 1: syntax error near unexpected token `"addio\n"'
./saluto2: line 1: `printf("addio\n");'
$
$ echo '#! /usr/bin/perl' > saluto2
$ echo 'printf("addio\n");' >> saluto2
$ ./saluto2
addio$
$ cat saluto1
echo Ciao
$ cat saluto2
#! /usr/bin/perl
printf("addio\n");
$ echo $SHELL
/bin/bash
$
Percorsi
Il percorso è la locazionedi un file nel FSH. Può essere:
- Percorso assoluto - inizia con / (slash) e parte dalla directory radice
es: /usr/share/man/man1/zsh.1.gz
- Percorso relativo - non inizia con / (slash) e parte dalla directory corrente
es: bin/try1.pl
Un percorso ha due componenti:
basename: nome del file dopo ultimo /dirname: percorso prima dell'ultimo /
Quindi il percorso intero è: pathname = [dirname/]basename
Si chiama pathname qualificato quello in cui il dirname è esplicitato. Si chiama pathname non qualificato quello in cui vi è solo la componente basename.
Esempi: sono qualificati
/usr/bin/passwd
./saluto1
bin/micro
Non sono qualificati:
passwd
saluto2
micro
I comandi espressi da un pathname qualificato vengono eseguiti direttamente
I comandi espressi dal solo basename vengono sempre ricercati nelle directories espresse dalle variabili d'ambiente PATH
- Solo in quelle. Non di default nella directory corrente.
Per sicurezza la directory corrente non è mai nel PATH
Esecuzione di prova, nella directory corrente
./prova
Ricerca di un eseguibile nel PATH:
which eseguibile
Il comando eseguibile è trovato ma non eseguito, e otteniamo ad output il percorso qualificato di eseguibile.
Notare che se eseguibile non c'è o non è nel PATH, which non dà errore, semplicemente un output vuoto.
Gestione Directories
Creazione di directory:
mkdir newdir
Rimozione di directory:
rmdir dir
Deve essere vuota. Per rimuovere una directory non vuota:
rm -rf dir
Rimozione ricorsiva della directory e di tutto il suo contenuto senza warnings (ATTENZIONE!)
Cambiamento di directory:
cd dir
Casi speciali:
cd: (senza argomento) torna alla directory di login – valore della variabile d'ambiente $HOME - anchecd ~cd ~pluto: alla HOME directory di plutocd -: torna alla directory precedente l'ultimo cd
Lista contenuto di una directory:
ls dir
Molte opzioni. Per listare la directory stessa e non il suo contenuto: ls -d dir
Verifica della directory corrente:
pwd: (print working directory) mostra il percorso completo directory corrente
E' molto importante sapere sempre in che directory ci troviamo prima di dare dei comandi. I processi hanno il concetto di Working Directory (Directory di Lavoro), che è quella in cui sono stati lanciati. I processi possono avere deggli errori se la loro directory di lavoro non ha i permessi adeguati.
Il comando di copia
Sintassi:
cp sorgente destinazione
cp sorg1 sorg2 sorg3 ... destinazione
Due tipi di copia:
- Copia singola
- sorgente deve essere un file
- destinazione può essere
- file nella stessa directory (nuovo nome)
- file in altra directory (stesso o nuovo nome)
- directory (stesso nome)
- Copia multipla
- destinazione deve essere directory (stesso nome)
Due casi per il file di destinazione:
- File destinazione esiste: è riscritto
- File destinazione non esiste: è creato

Il comando cp è un comando lento, perchè compie le seguenti operazioni:
- generazione di una nuova directory entry
- il campo nome è kl nome del file di destinazione
- viene allocato un nuovo inode e inserito nel campo inode
- ricorsivamente:
- allocazione di un nuovo blocco dati
- puntatore dell'inode al nuovo blocco dati
- copia dei dati del blocco dati sorgente nel blocco dati di destinazione
Il comando di link
Sintassi:
ln vecchionome nuovonome
Crea un nuovo nome file per lo stesso file riferito dal nome vecchio
- Il nome vecchio deve esistere
- Il nome nuovo non deve esistere
- può essere una directory: stesso nome del vecchio
- Il nuovo nome deve essere nello stesso file system del vecchio nome
Dopo il link non si sa più qual'era il file originale (situazione simmetrica). Il listato mostra che entrambi i file hanno ora un numero di riferimenti di 2 - in realtà sono lo stesso file.
Con il comando ls -li viene mostrato il numero di inode dei file.
Si può notare che vecchionome e nuovonome si riferiscono allo stesso inode e sono quindi due nomi diversi per lo stesso file.
Il comando ln è un comando veloce. Compie le seguenti operazioni:
- alloca una nuova directory entry
- il campo nome è il nome del nuovo file
- il campo inode è lo stesso del vecchio file
- nell'inode viene aumentato di 1 il numero dei riferimenti
Attenzioni
Il comando ln si chiama anche Hard Link e:
- non si può dare se la destinazione è in un file system diverso dalla sorgente
- non si può dare se la sorgente è una directory
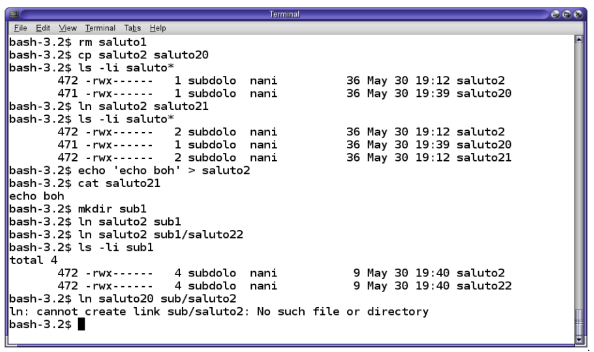
A cosa serve
Se avessimo due file linkati staticamente, p.es. comprime e decomprime, l'algoritmo di compressione e decompressione sarebbe praticamente lo stesso in entrambi e si avrebbe uno spreco di spazio disco.
Si può pensare di fare un singolo file, che abbia del codice aggiuntivo all'inizio. Il codice testa con che nome è stato invocato, e ha due comportamenti a seconda del nome. Si risparmia spazio disco.
Al limite è pensabile di avere decine di comandi che in realtà sono nomi diversi per lo stesso file eseguibile sottostante.
Questa è effettivamente la situazione dell'utility busybox, che implementa decine di comandi di base in distribuzioni di Linux mimime, quali ad esempio usate in contenitori Docker.
Il comando di rimozione
Sintassi:
rm file
Il comando rm corrisponde internamente alla system call unlink() ed effettivamente di suo compie le operazioni inverse di ln:
- Rimuove la directory entry col nome che si riferisce al file
- Decrementa il numero di riferimenti di 1 nell'inode
- Se ora il numero di riferimenti è ancora maggiore di zero gli altri nomi e il file rimangono
Se il numero riferimenti nuovo è zero viene invocata una funzione di Garbage Collection del device driver del filesystem:
- I blocchi del file ritornano alla lista dei blocchi liberi
- Il contenuto dei blocchi non viene toccato per velocizzare le operazioni
- I puntatori nell'inode sono azzerati
- L'inode è riallocabile
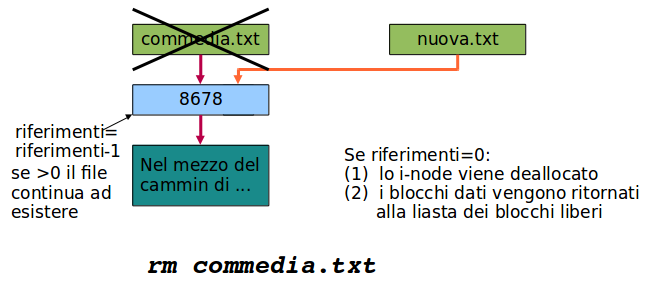
Il comando rm è un comando veloce se avanzano riferimenti, lento se viene cancellato l'ultimo riferimento.
In molti file system il file non più recuperabile. Non esiste un comando undelete.
Ciò non esclude sempre la possibilità di recuperare, almeno parzialmente, il file rimosso, ma con l'uso di procedimenti forensi ed utilities molto specializzate (non parte della distribuzione standard).
Se si vuole contrastare la possibilità di analisi forense dei dati cancellati, occorre recuperare e installare separatamente delle utilities che cancellino completamente i dati dai blocchi di allocazione all'atto della rimozione del file.
Il comando mv
Sposta un file dalla sua locazione in una directory entry in un'altra locazione.
Sintassi:
mv sorgente destinazione
mv sorg1 sorg2 sorg3 ... destinazione
Stessa sintassi di cp.
Operazione combinata di ln di un nome nuovo e rm del nome vecchio, atomica - non si può interrompere a metà.
La destinazione può avere lo stesso nome se è in una directory differente.
Non si può avere la destinazione in un file system diverso dalla sorgente.
Ma in tal caso molte distribuzioni eseguono un cp seguito da un rm (non è più atomica).
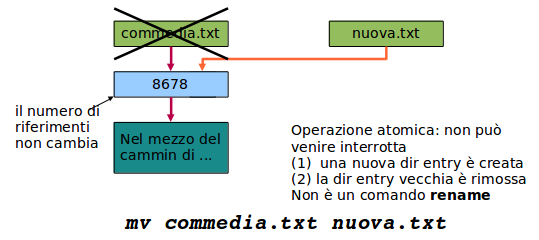
Esempi:
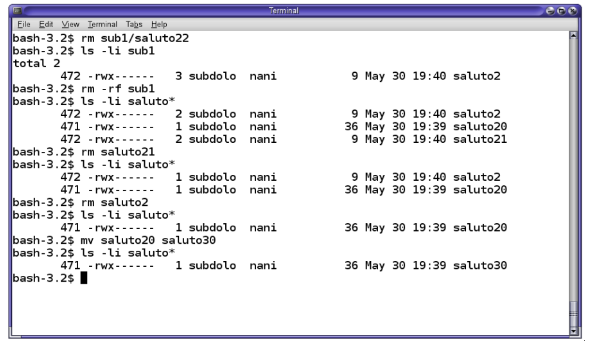
Link simbolico
Sintassi:
ln -s vecchionome nuovonome
Stessa sintassi di ln.
Crea un nuovo file destinazione di tipo “link”:
- i blocchi dati contengono il vecchio nome
- usare il nuovo file causa una redirezione interna al vecchio file
- si possono creare in altri file systems
Situazione di “broken link” se
- il file originale è stato rimosso
- il file system originale è irraggiungibile
E' una situazione asimmetrica.
Viene usato per tre scopi diversi:
- si intende compiere un link di una directory, per cui non è possibile uno hard link
- si intende fornire un riferimento atteso da un applicativo, ma che nel sistema corrente ha un nome diverso da quello che si aspetta l'applicativi (p.es.
vi) - il file sorgente e destinazione sono in file system diversi
E' molto usato in Linux.
Caratteri Jolly
Servono ad identificare più di un file nei comandi shell.
?sostituisce un singolo carattere nella posizione corrente*sostituisce un numero qualsiasi di caratteri, anche zero, nella posizione corrente[ ]racchiudono un numero di carartteri da cui ne viene selezionato uno solo[12af]– un insieme di caratteri[a-m]– un range di caratteri, inclusi i capi, in ordine ASCII crescente[^ ]seleziona un carattere non presente tra le parentesi quadre
Non confondere i Caratteri Jolly con le Espressioni Regolari -
Esempi
cp *.txt sub1
mv chapter??.doc backup
rm *.o
Attenzione!!:
rm * .o
.o: not found
Il seguente comando non è possibile:
mv *.txt *.doc
Procedura shell per ottenere lo stesso effetto:
for i in *.txt
do
j=`basename $i .txt`
mv $i $j.doc
done
I caratteri jolly vengono espansi dalla shell PRIMA dell'esecuzione del comando.
Esempi 2
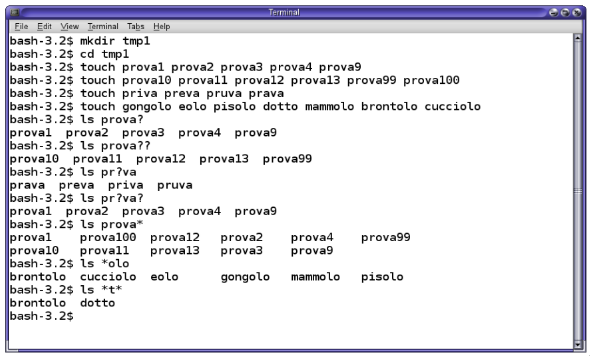

Espressioni Regolari
.- un qualsiasi caratterea+- una “a”a?- zero o una “a”a*- zero o più “a”(ab)*- zero o più “ab”^a- “a” a inizio rigaa$- “a” a fine riga[ab]- il carattere “a” oppure “b”[^ab]- nè “a” nè “b”(uno|due)- la stringa “uno” oppure “due”
Sono usate dal comando grep, che viene in tre versioni:
grep- riconosce parte delle ER, velocità mediafgrep- riconosce poche ER, velocità altaegrep- riconosce tutte le ER, velocità bassa
Le espressioni regolari costituiscono una sintassi complicata
Vi sono purtroppo più motori di espressioni regolari
POSIX- standard ormai anzianoGRE- Gnu Regular ExpressionsPCRE- Perl Compatible Regular Expressions- ecc.
Comandi diversi usano motori diversi e hanno diverse capacità di riconoscimento
perl- (Pattern Extraction and Report Language) è il più completoawk- anch'esso molto completo
Esempi di Espressioni Regolari
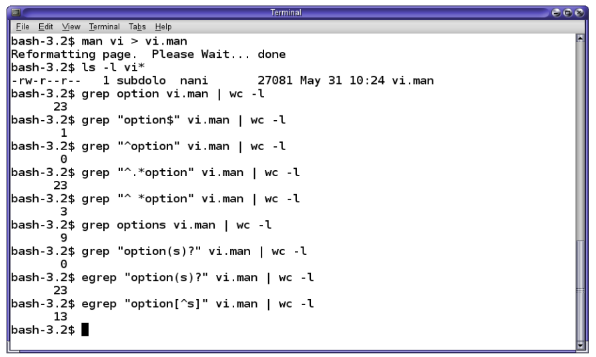
Il nuovo comando rename
Linux in alcune distribuzioni nuove ha introdotto il comando rename, che permette di cambiare parte del nome di un numero di files, identificati da caratteri jolly, tramite una specifica basata su espressioni regolari.
La sintassi di questo comando è:
rename [opzioni] s/regexvecchio/regexnuovo/ patternjolly
ove:
s/.../.../indica sostituzioneregexvecchoè l'espressione regolare che denota componenti del nome dei file esistentiregexnuovoè l'espressione regolare che denotaa i nuovi componenti dei filepatternjollyè un'espressione basata sui caratteri jolly che indica a quali files applicare i cambiamenti
Esempio:
rename s/\.txt/\.doc/ *.txt
Ci vuole \. e non solo.perchè quest'ultimo è un metacarattere delle espressioni regolari
Le opzioni sono:
-v- verboso-n- non eseguire veramente (modalità test)-f- forza la sovrascrittura di eventuali files preesistenti
C'è anche la modalità traduzione, oltre quella sostituzione.Per esempio:
rename y/A-Z/a-z/ *
cambia tutti i nomi dei files da maiuscole a minuscole.
Redirezioni e Pipes
Redirezioni
Ogni processo (programma o procedura in esecuzione)
ha associati d'ufficio tre file:
- stdin o standard input - di default da tastiera
- stdout o standard output (ovvero output normale) - di default al video
- stderr o standard error (ovvero output per gli errori) - di default al video
Ogni processo ha una file table o tabella dei file aperti dal processo, con ogni record indicizzato da un numero interoche parte da zero, il file descriptor (fd).
I primi tre fd, 0 1 2, corrispondono rispettivamente a stdin stdout stderr.
Ridirigere significa associare uno dei tre file standard ad un altro file su disco, anzichè a tastiera e video.
Formalmente si compie indicando il file descriptor che viene ridiretto, subito seguito dai simboli < o > per indicare la ridirezione della lettura o della scrittura, rispettivamente.
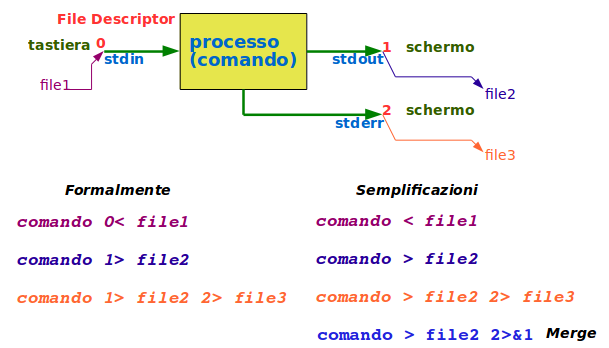
Vi sono due semplificazioni:
0<(redirezione dello standard input) si può scrivere semplicemente<1>(redirezione dello standard output) si può scrivere semplicemente>
Ma la redirezione dello standard error continua ad essere 2>.
E' da notare che i simboli di 'redirezione' sono simili a quelli di Windows ma vi sono alcune differenze:
- in Windows non si scrive
0<o1> - in Windows lo standard error non esiste
Attenzione: La redirezione dello standard output su un file già esistente, se abbiamo il permesso di scrittura, sovrascrive il file. Non viene dato nessun warning.
La particolare redirezione >> scrive lo standard output in modalità append cioè alla fine di un file già esistente. se il file non esiste viene creato.
Esempi di Redirezioni
Il comando ls -l /etc > lista ridirige l'output nel file lista.
Il comando echo "2+2" 1> conto ridirige (formalmente) la stringa "2+2" nel file conto.
Il comando bc < conto lancia l'utility bc (calcolatrice) che legge l'input dal file conto e produce il risultato (4) su output.
Il comando ls /etc/passwd xyyxz produce:
/etc/passwdsu standard output perchè il file esiste- un errore su standard error perchè il file
xyyxznon esiste
Il comando ls /etc/passwd xyyxz > /dev/null:
- butta via lo standard output. Il device
/dev/nullè il cestino infinito - mostra comunque l'errore perchè non abbiamo ridiretto lo standard error
Il comando ls /etc/passwd xyyxz 2> /dev/null butta via lo standard error e tirne lo standard output.
Il comando ls /etc/passwd xyxxz > /dev/null 2>&1 butta via entrambi.
Merge
Quando si vuole ridirigere sia lo standard output che lo standard error nello stesso file, non si deve scrivere:
comando > file 2> file
perchè file viene aperto due volte e i due flussi interferiscono (l'uno cancella quello che l'altro ha già scritto).
Bisogna invece scrivere:
comando > file 2>&1
Si legge 2>&1: il file descriptor 2 è ridiretto in merge al file descriptor 1.
In questo modo il file è aperto una sola volta (da standard output e il flusso di standard error è intercalato allo standard error.
Il comando cat
cat- Scrive lo standard input su standard output
- Ammette redirezioni
cat file1 file2 ...- Concatena (catenates) i file sullo standard output
cat mail??.elm > archivio- Compie un 'join' di tutti i file nell'archivio
cat mail99.elm >> archivio- Scrive il file in append
cat > log.txt- Scrive al file quello che si digita da tastiera
- Terminare con
Ctrl-D(fine file di input) - attenzione a non digitare il Ctrl-D troppe volte o si rischia di chiudere la shell interattiva corrente
Il comando echo
echo ”Ciao a tutta l'Europa”
Invia i suoi argomenti a standard output, seguiti da un newline
- Se gli argomenti contengono metacaratteri, nasconderli tra apici
echo -n ”Scelta: ”
non invia il newline (Linux)
echo ”Scelta: \c”
non invia il newline (System V).
echo -e ”\tScelta: \c”
inserisce un tab e non invia il newline (Linux)
echo ”Buongiorno” >> saluti
compie una redirezione in append al file
Il comando echo di default invia il suo argomento a standard output.
Se desideriamo stampare un errore, che quindi logicamente dovrebbe andare a standard error, allora scriviamo:
echo "errore" 1>&2
Pipes
Una pipe, rappresentata dal simbolo | (alto a sinistra sulla tastiera) è una giunzione tra due comandi:
- ridirige lo standard output del comando prima nello standard input del comando dopo
- i due comandi si chiamano il produttore e il consumatore dei dati
- sincronizza il produttore e il consumatore in modo che non scrivano e leggano simultaneamente, ma alternandosi
- è una primitiva di Inter-Process Communication (IPC) del kernel
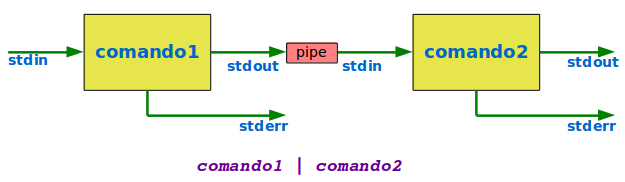
Si possono avere più pipes concatenate (max 10 processi) a formare una pipeline.
Se uno solo dei processi di una pipeline fallisce, anche tutti gli altri processi vengono terminati (situazione detta broken pipe).
(In bash) Non si possono fare pipes dello standard error o input.
Esempi di Pipes
who | wc -l
Ritorna quanti sono gli utenti collegati al sistema
wc -l | -w | -c [file]
conta le linee, le parole, i caratteri in un file o nello standard input
cat /etc/passwd | sort
Elenca gli account di sistema in ordine alfabetico
Si chiamano filtri i comandi che ammettono un argomento opzionale, il file su cui operano, ma
se l'argomento manca, operano su standard input
I filtri possono seguire una pipe
Ogni comando filtro deve produrre output “pulito” poichè potrebbe essere processato da una pipe seguente
Metacaratteri
- Caratteri del codice ASCII che vengono considerati elemanti sintattici da un interprete di comandi o da un'utility
- Caratteri jolly, espressioni regolari, parentesi, ecc.
- La shell stessa ne ha molti
- Interpreti e comandi diversi hanno metacaratteri diversi
Non sono metacaratteri A-Za-z0-9
Nei nomi file non sono metacaratteri shell . - _ (punto, trattino, underscore) ma
.(punto) - come primo carattere di un nome file rende il file nascosto-(trattino) - come primo carattere indica un'opzione
Nascondere i metacaratteri
Regole di quoting
" "- nascondono tutti i metacaratteri tranne$' '- nascondono tutti i metacaratteri\c- nasconde il metacaratterecche segue- Esempi:
\” \' \\ \$
- Esempi:
comando- (apici singoli rovesci) esegue il comando e ritorna nel contesto il suo standard output
Per esempio:
d=`date`
assegna alla variabile d l'output del comando date
Esempio sul quoting:
frutta=pesche
echo ”Il prezzo delle $frutta e' \$2”
Permessi sui File
Informazioni sui file
Il listato lungo di un file ha varie informazioni
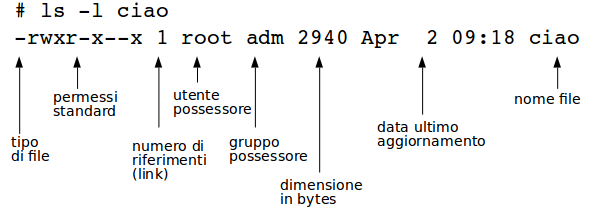
- tipo di file e permessi standard
- numero di link (riferimenti)
- utente possessore
- gruppo possessore
- dimensione del file
- data di ultimo aggiornamento
- nome
Nome file
Caratteri A-Za-z0-9.-_ (altri: metacaratteri shell)
- Max 248 caratteri
- Limitare a 32 per portabilità su CD e in rete
- Non inizia con – (trattino: indicativo opzione)
- Se inizia con . (punto) è nascosto
Tipo file
Si ricorda che tutto ciò che non è un processo è un file
E' il primissimo carattere del rapporto ls -l, attaccato e precedente ai nove caratteri dei permessi standard. Può essere:
-- regolare - un fule normale, di testo, dati, eseguibile, ecc.d- directory
I precedenti occupano spazio disco. I seguenti sono invece file, ma speciali, non occupanti spazio disco:
b- device a blocchic- device a caratteril- link simbolicos- socket
Un socket è una primitiva di comunicazione tra processi (Inter Process Communication - IPC). Un processo produttore scrive nel socket, un processo consumatore legge dal socket, e il kernel li sincronizza ed armonizza.
Vi sono vari tipi di socket:
inet sockets- Internet sockets - usati dai protocolli TCP/IPUnix sockets- file locali
Il segnalino s denota gli Unix socket. Sono multo numerosi in Linux, per esempio l'ambiente di logging usa il socket /dev(log.)
Date di un file
Sono anche chiamate date MAC:
- Modifica
- Accesso
- Modifica dell'inode (inizialmente: Creazione)
Listare le date:
ls -l: modificals -lu: accessols -lc: creazione
Cambiare le date MAC
Il possessore di un file può cambiarne le date MAC:
touch file: pone al file la data corrente a modifica e accesso- se il file non c'è viene creato
touch -t [[CC]YY]MMDDhhmm[.ss] file- dà al file tutte e tre le date secondo lo schema indicatotouch -a schema: solo accessotouch -m schema: solo modifica
Non ci si può fidare delle date MAC di un file come veritiere - possono essere state cambiate dal possessore del file o dall'amministratore.
Files di device
Sono conservati nella directory /dev e sottodirectories, e per sicurezza, solo lì
Esempi:
tty*- terminali di consoleptys/*- pseudo terminali, emulatori graficittyS*- porte serialiusbdev*- dispositivi USBparport*- porte parallelesd*- dischi SCSI o SATA
più numerosissimi altri.
I files in dev esistono solo se è caricato il device driver corrispondente – se ne occupa in automatico l'ambiente udev
L'inserimento di un device supportato (p.es. una chiave USB) produce:
- il caricamento del modulo driver nel kernel
- la comparsa in
/devdi un nome di device preconfigurato
Permessi standard
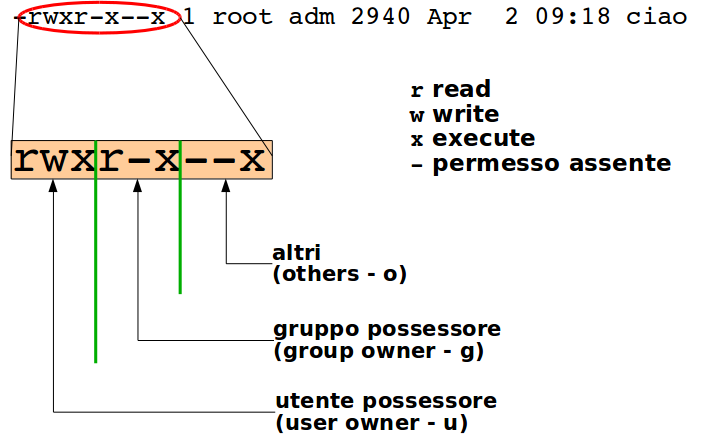
Permessi simbolici
Il possessore può cambiare i permessi dei propri file, con il comando: chmod permessi file
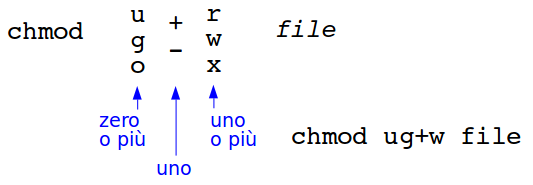
I permessi simbolici si esprimono con
- la combinazione di 0 o più dei caratteri (0caratteri = tutti i caratteri)
u- utente possessoreg- gruppo possessorio- altri
- l'uno o l'altro dei simboli
+- aggiungere i permessi-- togliere i permessi
- uno o più dei caratteri
r- permesso di lettursw- permesso di scritturax- permesso di esecuzione
Permessi numerici
I permassi si possono esprimere in formato numerico.
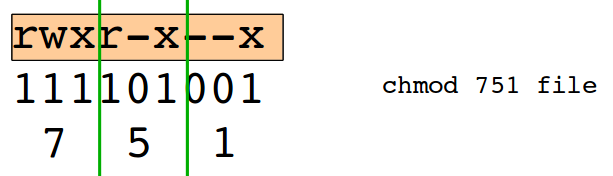
Ogni bit settato della maschera dei permessi corrisponde ad un 1, ogni bit non settato ad uno 0.
I tre gruppi di bit u, g ed o vengono convertiti in numeri decimali (propriamente: ottali), tre cifre. Questo numero di tre cifre viene usato per settare i permessi finali di un file.
Esempio
chmod 751 file
Setta i bit rwxr-x--x, tipica maschera di permessi di una procedura shell, con permessi totali per il possessore, che può essere letta ma non modificata dai membri del gruppo, ma solo eseguita dai membri del pubblico.
Quando si parla dei permessi di un file, in realtà si cita quasi sempre la maschera numerica.
Per citare un altro esempio, alcuni file sensitivi in Linux devono avere i permessi 600 o non vengono trattati dai programmi che li gestiscono.
E' il caso, tra l'altro, dei file contenenti le chiavi private in algoritmi di sicurezza basati su chiavi doppie.
Non è detto che il metodo simbolico di attribuzione permessi non si usi più.
Il caso più comune è l'attribuzione del permesso di esecuzione a procedure shell (o altri interpreti), che sono per loro natura file di testo:
chmod +x procedura
Permessi minimi
Capita a volte che non importi l'esatta machera ottale dei permessi, ma che ci sia il bisogno che almeno certi permessi siano settati.
In tal caso la maschera, nei programmi che la usano, è prefissa con un segno meno.
Per esempio -111 esprime la necessità che siano settati i permessi di esecuzione per tutti.
Permessi e comando find
L'espressione:
find . -perm 751
ricerca, al di sotto della directory corrente, tutti i files cil permessi esatti 751.
Inveceil comando:
find .-perm -111
ricerca i files che abbiano almeno il permesso di esecuzione per tutti.
Permessi Speciali
Notare che le password degli utenti sono conservate nel file /etc/shadow:
$ ls -l /etc/shadow
-rw-r----- 1 root shadow 1733 mar 22 10:29 /etc/shadow
$ cat /etc/shadow
cat: /etc/shadow: Permission denied
Gli utenti comuni non possono certo leggerlo.
Come avviene allore che il comando passwd, quando eseguito da un utente comune, riece a scrivere tale file?
La risposta è nei Permessi Speciali.
Quando si esegue passwd, quale eseguibile viene lanciato? vederlo con:
$ which passwd
/usr/bin/passwd
Verifichiamone i permessi:
$ ls -l /usr/bin/passwd
-rwsr-xr-x 1 root root 54256 mar 29 2016 /usr/bin/passwd
Notare la s.
Vi sono tre permessi speciali.
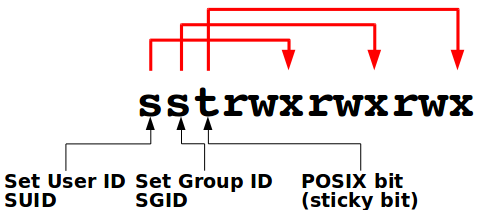
Sono:
Set User ID- (SUID) - chi esegue il file lo fà con i permessi dell'utente possessore del fileSet Group ID- (SGID) - chi esegue il file lo fà con i permessi del gruppo possessore del filePOSIX bit- applicato a directories pubbliche, pone limitazioni al comandormin tali directories: l'utente può rimuovere solo i propri files
I permessi speciali si settano come i permessi normali, tenendo conto che in totale i permessi sono 12 bit, quindi 4 cifre ottali.
Per esempio: chmod 4755 file

Permessi di default
Il parametro umask determina i permessi di default di nuovi files edirectories.
Permessi di nuovo oggetto sono ottenuti sottraendo umask a numero:
- file :
666 – umask - directory :
777 – umask
Per verificare la maschera corrente: umask
Per cambiarla: umask maschera
umask 022: default, diverso in varie distribuzioniumask 002: fiducia al gruppoumask 007: nessuna fiducia agli altriumask 077: massima diffidenza
Permessi e comandi
I permessi hanno significato diverso perfiles e directories.
- File
r- leggere il file per visualizzarlo, copiarlo o muoverlow- modificare il contenuto del file, ricoprire una destinazione di cp o mvx- eseguire un file binario o una procedura interpretata
- Directory
r- listare il contenutow- creare o distruggere file nella directoryx- eseguire cd nella directory
I comandi hanno bisogno di permessi opportuni sugli oggetti che manipolano.

Utilities

Vi sono molti comandi semplici e più complessi, ed intere utilities ed ambienti di produttività, la cui conoscenza fa veramente una notevole differenza nell'uso di Linux.
Utilities per i File
Il comando find
Per trovare il percorso di files che abbiano certe caratteristiche. Sintassi:
find directory clausola ...
findcompie una ricerca a partire dalla directory specificata per tutte le sottodirectories alla ricerca di files soddisfacecenti alla clausola/e specificata/e- Manda ad output il percorso dei file trovati
Esempi di clausole:
-name “nome”- con caratteri jolly-user utente | -group gruppo- apparteneti all'utente o grupp specificato, sia col nome che col UID o GID-ctime|-mtime|-atime +|- giorni- tempo di creazione, modifica, accesso superiore o inferiore a dati giorni-exec comando \;- esegue il comando sul file- All'interno delcomando il file corrente è designato da
{} - Il comando è terminato da un
;, che deve avere un\davanti per nasconderlo alla shell
- All'interno delcomando il file corrente è designato da
Il comando grep
Ricerca all'interno di uno o più file, o nello standard input, le espressioni regolari indicate. Sintassi:
grep [opzioni] espress_regolare [file]
- Seleziona le linee del file che contengono l'espressione regolare indicata (compie una slice orizzontale)
- Se il file non è indicato, tratta lo standard input
Ilcomando grep viene in tre varianti:
egrep– riconosce più espressioni, ha meno velocitàfgrep– meno espressioni, più velocitàgrep– medio espressioni e velocità
Opzioni principali:
-v– inverte ricerca: linee non contenenti espress.-c– conta solo le linee trovate-f file– legge le espressioni regolari dal file-n– mostra i numeri di linea-i– ignora se maiuscole o minuscole
Il comando cut
Seleziona dal file sezioni indicate (compie una slice verticale).
Due varianti, con le opzioni -c o -f.
Taglio di colonne specificate con -c:
cut -c lista [file] – lista di caratteri
Taglio di campi specificati con -f:
cut -dc -f lista [file]
- I campi sono delimitati dal carattere
c(default: tab) - Non ci vogliono spazi tra
-dec - La lista può onsistere in
- numeri separati da virgole
- range separato da
–(trattino)
- Se il file non è indicato legge da standard input
Il comando bc
Calcolatrice da linea di comando.
- Precisione infinita (limitata da risorse di sistema)
- Uscire con ^D (control-D)
Il comando tr
Copia l'input all'output con sostituzioni o cancellazioni di singoli caratteri
Esempi:
cat file1 | tr ”a” ”b”- cambia le a in b
tr ”[:lower:]” ”[:upper:]” < file1- cambia tutte le minuscole in maiuscole
tr -cd ”[:print:]” < file1- rimuove tutti i caratteri non stampabili dal file
-ccomplementa l'azione ai caratteri non specificati-drimuovi (delete)
Per le classi di caratteri vedere Espressioni Regolari
Il comando split
Spezza un file in file più piccoli con numero di byte o di linee definito.
Esempi:
split -b100k achivio.tar- Spezza il file archivio.tar in files da 100kB ciascuno e chiama i pezzi xaa, xab, xac, ...
split -b99m archivio.tar archivio.- Spezza il file archivio.tar in files da 99MB ciascuno e chiama i pezzi archivio.aa, archivio.ab, ...
split -l50 testo.txt- Spezza il file testo.txt ogni 50 linee
split -l30 -- Spezza lo standard input ogni 30 linee
AWK

E' un mini-linguaggio, inventato da Aho, Weinberger e Kernighan (da cui il nome).
- Scandisce un file, cerca linee con match ad un'espressione regolare ed esegue su di esse uno o più comandi.
- Opzionalmente esegue comandi prima dell'inizio e dopo la fine della scansione del file.
- Possiede numerose variabili predefinite e numerose funzioni
Nella sua semplicità è una piccola meraviglia. Assomiglia come sintassi al Linguaggio C, ma è molto meno formale, ed è un linguaggio di scripting, non compilato.
Sintassi:
awk [opzioni}ì] 'BEGIN{comandi}/pattern/{comandi}END{comandi}' file
awk '{comandi}' file
awk '/pattern/{comandi}' file
awk 'END{comand}' file
comando | awk '...'
awk -f procedura file
Esempio
Sommare lo spazio occupato dai file di una directory, che non siano sottodirectories.
ls -l | awk 'BEGIN{tot=0}/^[-]/{tot+=$5}END{print tot}'
Dove $5 è il quinto campo di un rapporto ls -l. In awk il separatore di campo è un qualsiasi numero di caratteri 'spazio', 'tab' e 'newline'. Se dovessimo farlo con cut dovremmo contare le colonne.
La variabile predefinita $1 sta per il primo campo sulla linea corrente, $2 il secondo, e così via. $0 è l'intera linea corrente. Quindi:
awk '{print $0}` file
è lo stesso di cat file.
Awk è corredato di un insieme cospicuo di funzioni matematiche. Stampare il seno di un angolo di un radiante:
awk '{print sin (1)}' < /dev/null
Qui il trucco è la ridirezione da /dev/null, poichè awk si aspetta un file in input.
I programmi awk si possono inserire in files di procedura, se lunghi, e richiamare all'esecuzione. Per esempio il file vi owner.awk (notare che se il file ha l'estensione awk, il vim lo riconosce e da la colorazione sintattica giusta):
#!/bin/awk -f
BEGIN { print "File\tOwner" }
{ print $9, "\t", \
$3}
END { print " - DONE -" }
Lo si esegue con:
ls -l | awk -f owner.awk
Documentazione e Manualistica

Per saperne di più, consulta il manuale, o in gergo RTFM.
Linux è corredato di manualistica di riferimento molto completa, accessibile tramite il comando man.
Il Manuale Standard
Locazione della struttura di manualistica: /usr/share/man
La directory intermedia ha il nome share per suggerire che, in una LAN con più computer della stessa distribuzione, può essere conveniente mantenere queste informazioni su un unico nodo di rete, in condivisione con gli altri.
Il manuale di Unix è composto da un certo numerodi sezioni standard numerate:
| Sezione | Contenuto |
|---|---|
| 1 | comandi utente |
| 2 | system calls |
| 3 | altre librerie |
| 4 | files di configurazione |
| 5 | altri files di configurazione |
| 6 | giochi |
| 7 | device drivers |
| 8 | comandi di amministrazione e di rete |
Possono esistere altre sezioni e sottosezioni.
Queste sezioni corrispondo alle sottodirectories man1, man2, ecc. della directory di manuale.
Originariamente, ai tempi dell'informatica americana, erano le uniche sottodirectories.
Poi ne sono compare altr, il cui nome è la sigla ISO di una lingua, p.es. it, fr, ...
Al di sotto di tali directories si ripete, forse parzialmente, la serie man1, man2, ecc.
Non è che basti che ci siano tali directories per avere la manualistica anche in tutte le lingue del mondo. Il supporto ad altre lingue è software che va installato separatamente.
Uso della manualistica
Esempi:
man passwd- Pagina del comando passwd (sezione 1)
man 5 passwd- Pagina del file /etc/passwd (sezione 5)
whatis passwd- In quali sezioni si trovano pagine col titolo passwd
apropos password- Quali pagine esistono che contengano la stringa password nel titolo o nella descrizione breve
Il database Whatis
Ogni pagina di manuale ha una sezione NAME, consistente in:
- il nome della pagina
- un trattino separatore
- una breve descrizione su una riga sola
Il manuale è indicizzato in un database con due chiavi: il nome e l'intera riga della sezione NAME. Questo è il database whatis.
L'indicizzazione avviene in automatico con frequenza giornaliera.
Il comando whatis compie una ricerca sul nome, il comando apropos sull'intera sezione NAME.
All'atto di installazione di nuovo software non di distribuzione può capitare che vengano inserite delle directories di manualistica in locazioni non standard.
Occorre allora impostare la variabile d'ambiente MANPATH, che è una lista, separata da :, di tutte le directories di manualistica.
Il database si può reindicizzare manualmente, con permessi amministrativi, coi comandi:
makewhatis- in Red Hatmandb- in Ubuntu
Sequenza di operazioni di man
Le pagine di manuale sono file compressi con gzip, scritte in linguaggio troff (in Linux: GNU groff).
Questo è un linguaggio testuale di descrizione delle pagine (antenato di HTML).
Per vederne un esempio, provare:
gunzip -c /usr/share/man/man1/gzip.1.gz | less
Il comando man:
- decomprime la pagina
- compie la resa a video, interpretando il troff
- compie la paginazione a video con
lesso col paginatore indicato dalla variabile d'ambientePAGER
Terminfo
I terminali seriali per il collegamento con interfaccia CLI sono da sempre il metodo principale di lavorare con UNIX in una sessione.
Vi erano negli anni 1990 più di 500 marche diverse di terminale, con tasti di controllo diversi e capabilities diverse: bold, undeline, scrolling, italics, ecc.
Ben presto nella storia di UNIX sì è stabilito uno standard, adottato da quasi tutti i vendors, per il controllo del terminale.
Un terminale produce una determinata capability quando riceve una determinata sequenza di caratteri preceduta dal carattere Escape: le cosiddette Sequenze di Escape.
UNIX e Linux possiedono un database (gerarchico) per la configurazione di un vasto numero di terminali, il database Terminfo.
Questo si trova nella directory /usr/share/terminfo, ma non è direttamente consultabile come testo, perchè si tratta di files binari.
Il riferimento alla scheda di terminfo che viene adottata dal terminale corrente è il valore dellavariabile d'ambiente TERM.
Controllare il valore corrente con echo $TERM. E' possibile settare un valore diverso, ma bisogna porre attenzione a non scegliere cattive configurazioni, o il terminale può non funzionare più.
Anche i pseudoterminali (terminali con finestra GUI), e gli emulatori di terminale (p.es. telnet, Putty, ecc.) fanno riferimento a questa variabile d'ambiente.
Le proprietà del terminale corrente si possono vedere tramite il comando infocmp.
Le proprietà di un altro terminale si possono vedere tramite il comando infocmp terminale.
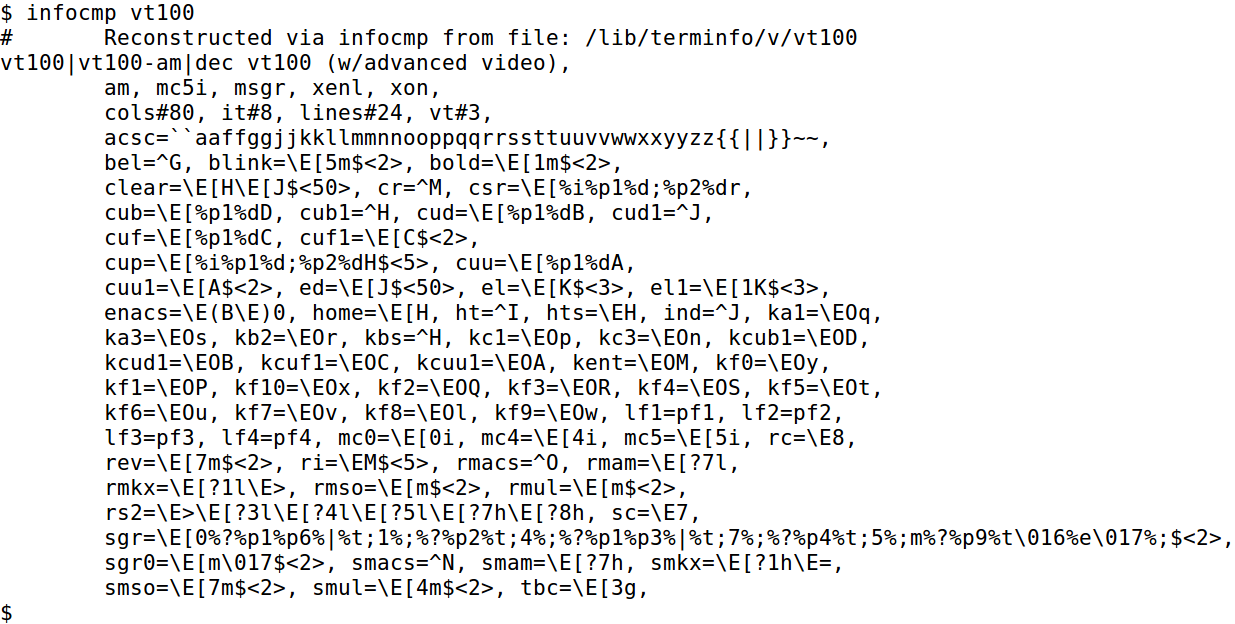
Le proprietà (capabilities) sono di tre tipi:
- numeriche, es.:
cols#80 - booleane, es.:
xon - stringhe di controllo terminale (sequenze di escape), es.:
clear=\E[H\E[J$<50>
Nuovo terminale
Non avviene più molto spesso, ma è possibile configurare un nuovo terminale precedentemente sconosciuto, conoscendo le sue capabilities e sequenze di controllo.
Si procede da una scheda di un terminale nota, copiandola in un file ed editandola con le caratteristiche del nuovo terminale.
Si registra poi nel database col comando: tic nuovoterminale.
Il comando tput
Sintassi:
tput capability
Invia la sequenza di controllo al terminale corrente per produrre la capability desiderata.
tput bold- grassettotput smso- colori invertititput clear- pulisce lo schermotput 23 4- pone il cursore a linea 23, colonna 4
e molti altri.
Attenzione che non tutti i terminali supportano tutte le capabilities.
Attenzione altresì che alcuni comandi, p.es. ls, usano essi stessi questo metodo, e possono ricambiare i settaggi.
Fondamenti di Programmazione Bash
Quando il capo entro con sguardo malefico, seppi subito che erano guai in vista. "Ora che abbiamo cambiato nome ditta da 'Acne' in 'Acme'", disse, "ci sono questi 5000 documenti da editare per mettere il nome nuovo". "Ma ci metterò una settimana!", protestai. "Allora comincia subito."
Psicologia del professional di Unix/Linux: Programmare è divertente, lavorare no.
Noi siamo professionals e a noi non piace lavorare, specie lavori disumani e ripetitivi. Vogliamo programmare il computer affinchè sia lui a compiere i lavori disumani. Noi siamo umani, lui no. Noi vogliamo fare cose nuove e intellettualmente interessanti, come inventare nuovi giochi, per esempio, o nuovi programmi, o nuovi linguaggi. O nuovi computer.
La shell di Linux, Bash, ci permette di scrivere procedure, scripts, che compiono il lavoro noioso per noi.
Bash non è mirata ad essere un linguaggio per applicativi, o destinato all'uso di un utente sconosciuto, o per la generazione di programmi di qualità
Bash è costruita per eseguire comandi in modalità batch, per risolvere problemi di amministrazione di sistema, per essere eseguita dai sysadmins, per accontentarsi di un livello di qualità sufficiente allo scopo.
Ho scritto una procedura shell che scandisce uno per uno i 5000 files e sostituisce il nome vecchio col nome nuovo. Ho impiegato un'ora a svilupparla, 15 minuti a testarla, 30 secondi ad eseguirla.
Ora ho una settimana libera.
Meglio non dirlo al capo, o la prossima volta si attenderà altri miracoli simili.

Procedure e Variabili
Prima procedura
Scriverà ciao a standard output. Si chiamerà ciao.sh.
Procedere come segue. Dare i comandi:
cd- per assicurarsi di essere nella propria HOME directorymkdir shellex- creazione della directory in cui eseguiremo gli esercizi shell, se già non esistecd shellex- cambio directorypwd- verifica di essere nella directory giusta, meglio sempre essere sicurivim ciao.sh- editazione della procedura shell
Il comando di vim i passa in modo editazione. Inserire il testo nel file:
echo "Ciao"
Ora uscire dalla modalità comando con Esc e salvare ed uscire digitando :wq ENTER.
Siamo usciti dal vim tornati alla CLI (comandi interattivi)
E' necessario che una procedura shell abbia il permesso di esecuzione. Glielo diamo col comando:
chmod +x ciao.sh
Ora la lanciamo col comando:
./ciao.sh
Se tutto è andato bene compare l'output:
Ciao
Se vi sono errori, occorre rieditare il file e correggerli.
In tal caso non è più necessario attribuire di nuovo il permesso di esecuzione.
Generalità
In una procedura shell vi è una istruzione per riga terminata da un ENTER
- Osservazione: il terminatore di riga di testo in Unix è
LF(newline) e nonCR-LFcome in windows - Eventualmente più istruzioni per riga sono separate da
;- Ma attenzione: mai mettere
;dopo l'istruzionedo
- Ma attenzione: mai mettere
- I separatori di token sono SPAZIO e TAB
- Il TAB serve a indentare il codice e produrre programmi dall'aspetto visualmente più comprensibile
- Il primo token di ogni istruzione deve essere un comando
Lancio di una procedura shell
Dopo l'editazione della procedura proc
- Lancio esplicito:
bash proc [argomenti]
- Lancio implicito:
./proc [argomenti]
Non proc [argomenti]
- La directory corrente non è mai nel PATH per sicurezza
./procè un percorso completo: dice di lanciare proc dalla directory corrente (il punto)
- Prima del lancio implicito occorre dare alla procedura il permesso di esecuzione:
chmod +x proc
Basta farlo una sola volta
Note
- Commenti
- Dopo il carattere `#` e fino a fine riga
- Sempre una buona idea descrivere il file e il suo scopo all'inizio
- Indentazioni
- Codice incluso nei costrutti di scelta e di ciclo
- Solitamente un TAB per ogni indentazione
- Non necessarie per la shell
- Aiutano la comprensione umana della struttura del programma
- Hash-bang
- Buona norma mettere a prima riga
#! /bin/bash
Un file non compilato col permesso di esecuzione viene presunto essere un file interpretato e passato all'interprete di default, che è descritto dalla variabile d'ambiente SHELL. Questo è di solito la bash in Linux (verificare col comando echo $SHELL).
Per essere completamente formale e rendere più portatile la procedura è meglio sempre mettere a prima linea lo hash-bang:
i caratteri #! seguiti dal percorso completo della shell.
Questo permette in generale di scrivere procedure anche per altri interpreti, oltre alla shell.
Per esempio, se anzichè essere una procedura shell fosse una procedura Perl, lo hash-bang sarebbe:
#! /usr/bin/perl
Variabili
- Non devono essere dichiarate
- Esistono appena vi si assegna un valore
conta=0
nome=Carlo
re='Numa Pompilio'
L'ultima è tra apici per nascondere lo spazio
-
Sono di tipo stringa (tranne eccezioni)
-
Assegnazione con l'0peratore
=- Attenzione: non devono esserci spazi in un'assegnazione
L'assegnazione ha il formato:
nome=valore
C'è differenza tra nome e valore di una variabile:
- Nome:
conta - Valore:
${conta}(formale) o$conta(se non vi sono confusioni)
Per vedere il valore della variabile di nome conts:
echo $conta
oppure
echo ${conta}
Esempio di variabili
(vars.sh):
a=55
echo "a vale $a"
echo "b vale >>$b<<"
a=$(($a+1))
a=`expr $a + 1`
echo "ora a vale $a"
h=$(hostname)
hh=`hostname`
echo "Nome macchina: $h"
echo "anche $hh"
meglio=con
echo ">>$megliosole<<"
echo "${meglio}sole"
Attribuirgli il permesso di esecuzione ed eseguire la procedura:
chmod +x vars.sh
./vars.sh
Il risultato è:
a vale 55
b vale >><<
ora a vale 57
Nome macchina: new-host
anche new-host
>><<
console
Nomi delle variabili
- Usano i caratteri minuscoli, maiuscoli e i numeri e lo underscore (
_) - Non devono iniziare con un numero
- Non possono contenere spazi o altri caratteri
- C'è differenza tra maiuscole e minuscole
- Lunghezza massima: 32 caratteri
- Non possono essere parole riservate del linguaggio
Scopo delle variabili
- Tutte le variabili sono globali nell'intera procedura
- Non vi sono scopi più limitati
- Occorre evitare la duplicazione di nomi
- Non sono note ad altre sottoprocedure
Ambiente
- Insieme di variabili di sessione note a tutte le procedure
- Al lancio ogni procedura "eredita" le variabili d'ambiente
- E' possibile "esportare" una variabile all'ambiente
export VARIABILE=valore
- Sarà nota a tutte le procedure lanciate in seguito
- Per convenzione le variabili d'ambiente hanno nomi tutti in maiuscolo
Comandi esterni dall'interno delle procedure
E' possibile eseguire comandi di sistema dentro le procedure shell.
(info.sh):
#! /bin/bash
echo -e "\tUn po' di informazioni\n"
echo -n "Nome utente: "
whoami
echo -n "Nome macchina: "
hostname
echo -n "Data completa: "
date
Qui \t è un TAB e \n è un NEWLINE.
Dare il permesso di esecuzione e lanciare. Il risultato è simile a:
Un po' di informazioni
Nome utente: mich
Nome macchina: blueice
Data completa: sab 11 mar 2017, 10.42.56, CET
Il comando echo
Invia i suoi argomenti a standard output seguiti da un newline
Se gli argomenti contengono metacaratteri devono essere protetti da quotes
Opzioni:
-n- non inviare il newline finale-e- interpreta le sequenze di escape
Sequenze di escape principali:
\t- tab\n- newline extra\c- non inviare il newline\b- backspace\e- escape
Aiuto sui comandi
- Aiuto generale:
help- Produce una lista di tutti i comandi della shell
- Aiuto più specifico:
help comando- Produce una corta sinossi del comando specificato
Manuale online della shell:
man bash
Descrizione di riferimento e non di apprendimento
Costrutti di Test
Stato di ritorno dei comandi
Ogni comando ritorna alla shell chiamante un numero intero, lo stato di ritorno, di valore:
0- se il comando ha avuto successo>0- se il comando è fallito
Lo stato di ritorno dell'ultimo comando eseguito è contenuto nella variabile $?
Esempio:
ls /etc/passwd
/etc/passwd
echo $?
0
ls /etc/password
… no such …
echo $?
2
Costrutto if
La sintassi è:
if comando
then
istruzioni
else
istruzioni
fi
Notare che l'argomento di if non è una codizione logica booleana, come in altri linguaggi, ma un comando.
if esegue il comando e ne testa lo stato di ritorno
- Se ha avuto successo compie le istruzioni dopo il
then - Se è fallito compie le istruzioni dopo lo
else - La branca
elseè opzionale - E' terminato da
fi
L'indentazione non è necessaria, ma è raccomandata per chiarezza visiva
Esempio.
(if1.sh):
#! /bin/bash
if ls $1 > /dev/null 2>&1
then
echo "Il file $1 esiste"
else
echo "il file $1 non esiste"
fi
Provare con vari test:
./if1.sh if1.sh
Il file if1.sh esiste
./if1.sh zippo
il file zippo non esiste
./if1.sh if*
Il file if1.sh esiste
Note:
> /dev/null ridirige lo standard output sul device nullo, scarta l'output del comando
2>&1 ridirige lo standard error in merge con lo standard output, scarta gli errori del comando
Nel caso di ./if1.sh if* la shell espande il carattere jolly * prima dell'esecuzione del comando
Se vi sono più file soddisfatti dal carattere jolly, solo il primo
viene mostrato.
Notare il caso limite:
./if1.sh
Il file esiste
Occorre testare che vi siano argomenti prima di eseguire il resto della procedura
Il comando test
if esegue un comando
- Normalmente gli if hanno una condizione logica
Il comando test ha come argomenti un'espressione logica
- test ha successo se la condizione è vera
- fallisce se la condizione è falsa
Tramite test si può far provare a if una condizione logica
Rivisitazione dell'esempio precedente:
(if2.sh):
#! /bin/bash
if test $# -eq 0
then
echo "$0: usage: $0 file" 1>&2
exit 1
fi
if ls $1 > /dev/null 2>&1
then
echo "Il file $1 esiste"
else
echo "il file $1 non esiste"
fi
Notare la filosofia: se qualcuno degli ingredienti necessari alla procedura non è presente, allora si termina subito con un messaggio d'errore.
Il comando exit 1 esce dalla procedura e ritorna lo stato di ritorno 1 alla shell chiamante.
In altre parole: non speriamo di avere tutto per poter continuare a lavorare; speriamo che qualcosa manchi così non si deve lavorare.
Oltre che
if test cond_logica
si può scrivere
if [ cond_logica ]
Notare gli spazi obbligatori vicino alle quadre.
Questo è cosiddetto zucchero sintattico per rendere l'aspetto più simile a sintassi tradizionale. Quello che succede internamente è che [ è un alias del comando test.
Esempio.
(test1.sh):
#! /bin/bash
echo -n "Dammi un numero: "
read num
if test $num -gt 5
then
echo "Il numero e' maggiore di cinque"
else
echo "E' un numero piccolo"
fi
Operatori di test
Operatori di paragone numerico:
-gt- maggiore-ge- maggiore o uguale-lt- minore-le- minore o uguale-eq- uguale-ne- non uguale
Operatori di paragone tra stringhe:
"str1" = "str2"- uguali"str1" != "str2"- diverse
Esempio.
(test2.sh):
#! /bin/bash
if [ "$(whoami)" = "root" ]
then
echo "Attenzione: sei l'amministratore"
else
echo "Non sei l'amministratore"
fi
Altro esempio, basato sul fatto che la variabile d'ambiente $UID contiene lo User Id, e che se questo è 0 abbiamo i poteri del supruser, ossia dell'amministratore.
(test3.sh):
#! /bin/bash
warn=Attenzione:
non=Non
if [ $UID -eq 0 ]
then
unset non
else
unset warn
fi
echo "$warn $non sei l'amministratore"
Il comando unset seguito dal nome di una variabile, toglie quella variabile se esiste, e non da errore se non esiste.
Serve per assicurarsi che una variabile non sia settata.
La stampa di una variabile non settat aproduce uno spazio vuoto (non la stringa nulla).
Altre opzioni di test
Il comando test serve anche a testare le proprietà di un file:
-e file- esiste-f file- esiste ed è un file regolare-d file- esiste ed è una directory-L file- esiste ed è un link simbolico-r file- esiste ed ha il permesso di lettura-w file- esiste ed ha il permesso di scrittura-x file- esiste ed ha il permesso di esecuzione-u file- esiste ed è un SUID-g file- esiste ed è uno SGID-k file- esiste ed ha il POSIX bit-s file- esiste e ha dimensione maggiore di zero-b file- esiste ed è un device a blocchi-c file- esiste ed è un device a caratteri-p file- esiste ed è una pipe-S file- esiste ed è un socket
I permesi sono intesi per l'utente che sta eseguendo la procedura corrente.
E ancora:
-O file- siamo i possessori del file-G file- il file è del nostro gruppofile1 -nt file2- file1 è più nuovo di file2 (modifica)file1 -ot file2- file1 è più vecchio di file2file1 -ef file2- file1 e file2 sono link diretti allo stesso inode
Più test diversi si possono unire con operatori logici:
!- NOT-a- AND-o- OR
Anche test di stringhe:
-z $var- testa sevarè una stringa vuota-n $vartesta sevarè una stringa non vuota
Nel test di una stringa con if
il costrutto:
if [ "$str1" = "" ]
causa errore. Meglio scivere:
if [ "x$str1" = "x" ]
oppure meglio ancora:
if [ -z "$str1" ]
Il Costrutto case
Sintassi:
case variabile in
cost1 )
istruzioni
istruzioni ;;
cost2 | cost3 )
istruzioni ;;
. . .
* )
istruzioni ;;
esac
case confronta la variabile con ogni costante
Al primo match esegue le istruzioni che seguono fino al ;; poi esce dopo esac (si, è case a rovescio, cos' come fi è if arovescio)
La costante * è sempre soddisfatta
e se c'è deve essere l'ultima della lista
Esempio.
(case1.sh):
#! /bin/bash
cat << EOF
Unix e':
1) Un bellissimo sistema operativo
2) Un'agenzia ONU
3) Un club di bagni turchi
EOF
echo -n "Scelta? "
read sc
case $sc in
1 )
echo "Bravo!"
echo "Hai studiato" ;;
2|3 )
echo "No!" ;;
*)
echo "Scelta non prevista" ;;
esac
Note:
2|3 denota un OR

Piccola miglioria, il comando interno read è più complesso di quanto si creda (RTFM: help read).
Sostituire le linee:
echo -n "Scelta? "
read sc
con la linea
read -sn 1 -p "Scelta? " sc
ove:
-s- silenzioso-n 1- legge solo un carattere-p "..."- pronto
Tipi, Arrays ed Espressioni
Bash, a differnenza di sh ammette la dichiarazione opzionale di tipi di variabili. Tutte le variabili il cui tipo non è dichiarato sono di default stringhe.
Non ci sono tipi veri ma indicazioni sull'utilizzo.
In realtà dei tipi se ne può fare benissimo a meno. La shell non è un linguaggiodi programmazione applicativi, ma un metodo per automatizzare attività di sistema.
Per assegnare un altro tipo, esempio:
declare -i conta=1- tipo intero
Opzioni per i tipi:
-a var- array-f var- funzione-i var- intero-r var- read-only (costante: deve subito venire assegnata)-p var- mostra gli attributi e il tipo-t var- marcata per il trace-x var- marcata per l'export all'ambiente
Esempio.
(tipi1.sh):
#! /bin/bash
declare -i conta=1
echo $conta
conta=pippo
echo $conta
declare -p conta
declare -r PI=3.14159
PI=3
echo PI=$PI
Uso:
./tipi1.sh
1
0
declare -i conta="0"
./tipi1.sh: line 8: PI: readonly variable
PI=3.14159
Altro esempio.
(tipi2.sh):
#! /bin/bash
var=pippo
declare -p var
readonly area=7.25
area=3
declare -p area
Uso:
./tipi2.sh
declare -- var="pippo"
./tipi2.sh: line 5: area: readonly variable
declare -r area="7.25"
readonly è un sinonimo di declare -r
Array
Strutture monodimensionali ad allocazione dinamica di elementi
indicizzati con interi
- Indici iniziano da zero (non da uno)
- Non tutti gli elementi devono esistere (buchi possibili)
Dichiarazione esplicita:
declare -a array
Dichiarazione indiretta su inizializzazione di un elemento:
array[indice]=valore
Notare l'assenza di spazi
Inizializzazione con più valori:
array=(val1 val2 val3 …)
I separatori sono spazi
Accesso agli array:
- Riferimento a elemento:
${array[indice]}- Le graffe sono necessarie
- Il valore del nome di un array è il valore del suo primo elemento
$arraycome${array[0]}
- Lista di tutti gli elementi assegnati:
${array[*]} - Numero degli elementi assegnati:
${#array[*]} - Lunghezza di un elemento di array:
${#array[indice]}- E' trattato come stringa
Esempio
(array1.sh):
#! /bin/bash
colori=(bianco rosso verde)
echo ${colori[*]}
echo $colori
echo $colori[*]
echo ${colori[0]}
echo ${colori[1]}
echo ">>${colori[4]}<<"
colori[4]=blu
echo ">>${colori[4]}<<"
echo ${colori[*]}
Esecuzione:
./array1.sh
bianco rosso verde
bianco
bianco[*]
bianco
rosso
>><<
>>blu<<
bianco rosso verde blu
Altro esempio.
(array2.sh):
#! /bin/bash
animali=(mucca gatto cane)
animali[4]=corvo
echo "Lista: ${animali[*]}"
echo "Numero: ${#animali[*]}"
unset animali[1]
echo "Lista: ${animali[*]}"
unset animali
echo "Lista: ${animali[*]}"
Esecuzione:
./array2.sh
Lista: mucca gatto cane corvo
Numero: 4
Lista: mucca cane corvo
Lista:
Il comando expr
E' un valutatore di espressioni
Uso:
variabile=$(expr espressione)
- Un'espressione contiene operandi e operatori
- Ogni elemento deve essere separato da spazi
- Operatori aritmetici infissi - solo su numeri interi
+- addizione-- sottrazione\*- moltiplicazione- occorre lo
\perchè*è un metacarattere shell
- occorre lo
/- divisione%- modulo (resto della divisione)
Esempio.
(expr1.sh):
#! /bin/bash
v1=10; v2=3
echo "var1=$v1 var2=$v2"
echo "piu': $(expr $v1 + $v2)"
echo "meno: $(expr $v1 - $v2)"
echo "per: $(expr $v1 \* $v2)"
echo "diviso: $(expr $v1 / $v2)"
echo "modulo: $(expr $v1 % $v2)"
Ce da:
./expr1.sh
var1=10 var2=v2
piu': 13
meno: 7
per: 30
diviso: 3
modulo: 1
Le espressioni aritmetiche e logiche possono anche essere contenute tra doppie parentesi tonde:
(( espressione ))- in contestoif, …$(( espressione ))- in contesto stringa
NB: ci vogliono gli spazi
Migliorie rispetto ad expr:
- Le variabili dell'espressione non necessitano del prefisso
$ - Nessun operatore ha bisogno di
\ - Non sono indispensabili gli spazi separatori tra ogni elemento dell'espressione
Esempio.
(expr2.sh):
#! /bin/bash
v1=10; v2=3
echo "var1=$v1 var2=v2"
echo "piu': $((v1+v2))"
echo "meno: $((v1-v2))"
echo "per: $((v1*v2))"
echo "diviso: $((v1/v2))"
echo "modulo: $((v1%v2))"
if ((v1 > v2))
then
echo "$v1 > $v2"
fi
Che dà:
./expr2.sh
var1=10 var2=v2
piu': 13
meno: 7
per: 30
diviso: 3
modulo: 1
10 > 3
Stringhe
La shell Bash ha avuto una lunga storia e molte aggiunte
- Per la compatibilità con la shell di Bourne
- Per aggiungere nuove funzionalità
- Per interagire con comandi esterni come expr
- Come risultato è un miscuglio di sintassi
- Qualche volta sembra inconsistente
- Vi sono spesso più modi per ottenere un risultato
Esempio tipico è la gestione stringhe
Lunghezza di una stringa:
str=abcdefghijklmnopqrstuvwxyz
echo ${#str}
echo $(expr length $str)
Sottostringa:
echo ${str:10}
echo ${str:10:4}
echo ${str: -4}
NB: ci vuole uno spazio prima del meno
Anche:
echo $(expr substr $str 5 6)
Indice di una sottostringa:
echo $(expr index $str 'lmn')
Rimozione sottostringhe
Data la stringa:
st=abcABC123ABCabc
Rimozione corta iniziale:
echo ${st#a*C}
Rimozione lunga iniziale:
echo ${st##a*C}
Rimozione corta finale:
echo ${st%A*c}
Rimozione lunga finale:
echo ${st%%A*c}
Sostituzione sottostringhe
Sostituzione della prima occorrenza:
echo ${st/abc/xyz}
Sostituzione di ogni occorrenza:
echo ${st//abc/xyz}
Sostituzione condizionale iniziale:
${st/#abc/XYZ}
Sostituzione condizionale finale:
${st/%abc/XYZ}
Sostituzione parametrica
Se la variabile non è settata, usa il default:
${variabile-default}
La variabile però rimane non settata
- Usato soprattutto per gli argomenti della linea di comando
Se la variabile non è settata o è la stringa vuota, usa il default:
${variabile:-default}
Se la variabile non è settata, settala al default:
${variabile=default}
Se la variabile è settata usa l'alternativa:
${variabile+alternativa}
Se la variabile non è settata, esci col messaggio d'errore:
${variabile?"messaggio"}
Esempio.
(param1.sh):
#! /bin/bash
var1=
echo ">>${var1-pippo}<<"
echo ">>${var1:-pippo}<<"
echo ">>${var2-pippo}<<"
echo ">>${var2:-pippo}<<"
echo ">>$var1<<"
echo ">>$var2<<"
Che dà:
./param1.sh
>><<
>>pippo<<
>>pippo<<
>>pippo<<
>><<
>><<
Altro esempio.
(param1a.sh):
#! /bin/bash
echo -n "Ciao, come ti chiami? "
read nome
echo "Benvenuto, ${nome:-ciccio}"
Esempi d'uso:
./param1a.sh
Ciao, come ti chiami? alfio
Benvenuto, alfio
./param1a.sh
Ciao, come ti chiami?
Benvenuto, ciccio
Esempio.
(param1b.sh):
#! /bin/bash
file=${1:-/etc/passwd}
[ -e $file ] && ex="esiste" || ex="non esiste"
echo $file $ex
Uso:
./param1b.sh
/etc/passwd esiste
./param1b.sh zot
zot non esiste
Esempio.
(param2.sh):
#! /bin/bash
var1=
echo ">>${var1=pippo}<<"
echo ">>${var1:=pluto}<<"
echo ">>${var2=paperino}<<"
echo ">>${var2:=minnie}<<"
echo ">>$var1<<"
echo ">>$var2<<"
Uso:
./param2.sh
>><<
>>pluto<<
>>paperino<<
>>paperino<<
>>pluto<<
>>paperino<<
Esempio.
(param3.sh):
#! /bin/bash
var1=
var2=topolino
echo ">>${var1+pippo}<<"
echo ">>${var1:+pluto}<<"
echo ">>${var2+paperino}<<"
echo ">>${var2:+minnie}<<"
echo ">>$var1<<"
echo ">>$var2<<"
Uso:
./param3.sh
>>pippo<<
>><<
>>paperino<<
>>minnie<<
>><<
>>topolino<<
Esempio.
(param4.sh):
#! /bin/bash
: ${HOSTNAME?} ${USER?} ${HOME?} ${MAIL:="non settata"}
echo "Parametri d'ambiente principali settati"
echo "Sei l'utente $USER"
echo "Sul computer $HOSTNAME"
echo "La tua Home Directory e' $HOME"
echo "La tua casella di posta e' $MAIL"
Il comando : è il comando nullo, e qui è usato solo come 'trucco' per settare le variabili a seguire.
Uso:
./param4.sh
Parametri d'ambiente principali settati
Sei l'utente michele
Sul computer thorin
La tua Home Directory e' /home/michele
La tua casella di posta e' non settata
Costrutti di Flusso
Costrutto while
Sintassi:
while comando
do
istruzioni
done
Il ciclo viene eseguito fintanto che lo stato di ritorno del comando è zero (successo)
- Se al primo giro il comando già fallisce il ciclo non è mai eseguito
- Il comando è spesso implementato come istruzione di test
Occorre che le istruzioni del ciclo modifichino opportunamente gli operandi dell'espressione logica testata o si può incorrere in un ciclo infinito
Se si desidera un ciclo infinito lo si ottiene con:
while true
Due comandi utili:
true- ritorna successofalse- ritorna fallimento
Esempio.
(while1.sh):
#! /bin/bash
count=10
while ((count > 0))
do
echo $count
sleep 1
count=$((count-1))
done
Compie un conto alla rovescia da 10 a 1 inclusi, con un secondo di intervallo tra ogni numero.
Note sulle parentesi:
(( … ))- racchiudono un'espressione logica e ritornano 0 se vera e 1 se falsa$( … )- restituiscono l'output di un comando$(( … ))- restituiscono il risultato dell'operazione aritmeticasleep n- attendensecondi
Esempio variante al precedente.
(while1a.sh):
#! /bin/bash
count=10
while ((count > 0))
do
echo $((count--))
sleep 1
done
Operaratori di autoincremento e autodecremento
- Incrementano o decrementano di 1 la variabile
var++var--- usano la variabile prima++var--var- usano la variabile dopo- Sono gli stessi del linguaggioC
- Devono comarire in espressioni
$(( ... ))
Costrutto until
Sintassi:
until comando
do
istruzioni
done
Il ciclo viene sospeso quando lo stato di ritorno del comando è zero (successo)
- Se al primo giro il comando ha già successo il ciclo non è mai eseguito
- Naturalmente il comando è spesso un'espressione di test
Esempio.
(until1.sh):
#! /bin/bash
count=10
until ((count == 0))
do
echo $count
sleep 1
count=$((count-1))
done
Attenzione agli operatori nel contesto (( ... ))
=- di assegnazione==- di paragone di uguaglianza!=- di paragone di differenza
Costrutto for
Prima forma:
for variabile in lista
do
istruzioni
done
Ove:
doedonedelimitano le istruzioni di ciclo- La variabile assume ad ogni ciclo il valore successivo della lista
- La lista è esplicita o generata con un comando
- I cicli terminano quando l'intera lista è stata scandita *Eventuali errori intermedi non terminano la scansione della lista
Esempio.
(for1.sh):
#! /bin/bash
(($# == 0)) && echo "no args given" >&2 && exit 1
[ ! -d $1 ] && echo "$1 not a dir" >&2 && exit 2
[ ! -r $1 ] && echo "cannot read $1" >&2 && exit 3
subs=0
for i in $(ls $1)
do
if [ -d $1/$i ]
then
((subs++))
fi
done
echo "$1 has $subs subdirs"
Seconda forma del costrutto for:
for (( iniz; cond; loop ))
do
istruzioni
done
ove:
inizè un'istruzione eseguita prima del ciclo- possono essere più istruzioni se separate da virgole
condè la condizione logica di esecuzione del cicloloopè un'istruzione eseguita alla fine di ciascun ciclo
Questo tipo di for è preso dal linguaggio C
Esempio.
(for2.sh):
#! /bin/bash
for ((i=1;i<11;i++))
do
for ((j=1;j<11;j++))
do
echo -ne "$((i*j))\t"
done
echo
done
Ove:
-n- non va a capo-e- riconosce i caratteri di escape come \t (tab)echoda solo produce una linea vuota
Esempio migliorato.
(for2a.sh):
#! /bin/bash
for ((i=1;i<11;i++))
do
for ((j=1;j<11;j++))
do
printf "%5d" $((i*j))
done
echo
done
printf
printf - print formattato
printf "formato" arg1 arg2 …
- La stringa di formato può contenere dei segnalini di formato di argomento del tipo
%fff - Deve esserci un argomento per ogni segnalino
- I segnalini sono gli stessi dell'equivalente funzione del linguaggio C
Segnalini di formato, esempi:
%d- numero intero decimale%x- numero intero esadecimale%5d- intero decimale in un campo di 5 caratteri%10,2f- numero float in un campo di 10 caratteri con 2 caratteri dopo la virgola%sstringa
Anche i caratteri di escape sono riconosciuti all'interno delle stringhe di formattazione.
Comandi break e continue
Si possono usare con while, until e for
Il comando break esce dal ciclo corrente e manda il controllo all'istruzione dopo il done
Il comando continue manda il controllo all'istruzione done saltando le rimanenti istruzioni del ciclo
- Inizia quindi un nuovo ciclo con l'esecuzione del comando di while o until o l'elemento successivo del for
Esempio.
(break1.sh):
#! /bin/bash
[ $# -lt 1 ] \
&& echo "usage: $0 divisor [max]" >&2 \
&& exit 1
max=${2:-1000}
i=0
while true
do
((++i > max)) && break
(( (i%$1) != 0)) && continue
tput smso
printf "%5d" $i
tput sgr0
printf " "
done
echo -e "\nEnded"
Funzioni e Sottoprocedure
Chiamare altre procedure
Ogni procedura con permesso di esecuzione è un comando Unix e può essere invocata da ogni altra procedura
Si applicano le normali considerazioni di percorsi e permessi
Le procedure chiamate sono eseguite da sottoshell
Tutte le loro variabili sono locali a loro
Se cambiano l'ambiente la procedura chiamante non lo sente
Per eseguire la procedura proc nella shell corrente:
. proc oppure
source proc
Funzioni
Una funzione è semplicemente una serie di istruzioni raggruppate e identificate da un nome
- Le variabili della funzione sono di default globali
- Non vi è un valore di ritorno
In realtà sono subroutines, non funzioni come concepite da altri linguaggi di programmazione.
Sintassi di definizione:
function funzione {
istruzioni
}
Anche solo:
funzione() {
...
}
Invocate solo menzionandone il nome:
. . .
funzione
. . .
Le funzioni devono essere definite prima di essere invocate
Parametri
- Le funzioni possono ricevere parametri
- I parametri attuali sono semplici argomenti dell'invocazione della funzione
- I parametri formali sono
$1 $2ecc.
Ritorno
- La funzione ritorna dopo la
} - Può tornare prima col comando
return - Può settare uno stato di ritorno con
return num
Convenzioni come con le procedure:
0- successo>0- fallimento
Il chiamante può testare $?
Esempio.
(funz1.sh):
#! /bin/bash
error(){
echo "$1" >&2
echo "$0: usage: $0 num" >&2
exit $2
}
# main
(( $# < 1 )) && error "Argomenti mancanti" 3
(( $1 < 100 )) && error "Numero troppo piccolo" 250
echo "$1 e' un bel numero"
Notare che il main:
- non ha nessuna etichetta particolare
- non è una funzione
- è l'ultimo codice del file
- è una buona idea commentare l'inizio del
main
I parametri formali del main sono diversi da quelli delle funzioni
Variabili locali
Variabili locali alla funzione sono dichiarate con la parola chiave local
Si può anche simulare un valore di ritorno
Esempio.
(funz2.sh):
#! /bin/bash
mult() {
local risult=$(($1*$2))
echo "$risult"
}
# main
ris=$(mult 3 5)
echo $ris
Il comando eval
Sintassi:
eval assegnazione
Esegue l'assegnazione due volte, la seconda col risultato della prima
Esempio.
(eval1.sh):
#! /bin/bash
foo=10 bar=foo
x='$'$bar
echo "Senza eval: $x"
eval y='$'$bar
echo "Con eval: $y"
Uso:
./eval1.sh
Senza eval: $foo
Con eval: 10
Notare che non si può scrivere $$bar poichè la shell tenterebbe di interpretarli entrambi. Occorre che il primo $ sia nascosto con '$'.
In presenza di quotes la shell ignora il contenuto, ma al contempo le toglie. Quindi quando valutata la seconda volta, y ha assegnato il valore $foo ovvero 10.
Altro esempio.
(eval2.sh):
#! /bin/bash
$( echo var=5 )
eval $( echo var=5 )
echo $var
a="ls * | sort"
$a
eval $a
Lancio:
./eval2.sh
./eval2.sh: line 2: var=5: command not found
5
ls: cannot access |: No such file or directory
ls: cannot access sort: No such file or directory
eval1.sh eval2.sh ...
eval1.sh
eval2.sh
...
Il comando $( echo var=5 ) esegue echo var=5 che manda ad output la stringa var=5. Non è più un'assegnazione, è una stringa. Tenta poi di eseguire la stringa "var=5" e non trova nessun comando di quel nome.
Con eval invece legge la stringa var=5 come se fosse appena stata digitata da tastiera e la vede come assegnazione.
Con a="ls * | sort" la variabile a riceve una stringa. Non si può eseguire una stringa che contiene metacaratteri, deve essere riscandita dalla shell per comprendere e interpretare i metacaratteri. Altrimenti vengono visti come argomenti del comando.
Se fosse stato solo a="ls *" bastava per l'esecuzione, ma nel nostro caso | e sort sono visti come nome file argomenti di ls.
La parte ls * è ancora valida e viene eseguita, producendo un listato (orizzontale). I comandi completano anche parzialmente.
Se avessimo scritto a="ls *| sort" non avrebbe riconosciuto nemmeno il file *| e avrebbe fallito completamente.
Finalmente eval $a riscandisce la stringa "ls * | sort", la comprende e la esegue, producendo un listato verticale.
Conclusione
Se Unix esistesse ancora nella sua incarnazione originale avrebbe più di 45 anni; Linux ne ha più di 25, come altri discendenti di Unix quali HP-UX, MacOS e lo stesso Windows.
I figli devono crescere, e ogni figlio di Unix ha avuto un'evoluzione propria che lo discosta molto da quello che era in origine, e dai propri fratelli.
Linux è quello che promette meglio, con l'architettura interna migliore, protesa verso innovazioni future.
Non sono però state abbandonate le idee filosofiche di base di Unix, la pulizia del codice, l'estendibilità, l'efficienza, la necessità di capire il funzionamento.
Non si vede al momento nella sfera di cristallo un sistema operativo totalmente innovativo, anche se è forse ora che venga riscritto in qualcosa di più moderno del Linguaggio C.
Linux è vasto, e nessuno può mai essere un totale esperto di tutti i suoi aspetti, ambienti ed utilities.
Ma a mio parere, e forse senza dubbio, Linux ha una proprietà notevole rispetto agli altri: è esteticamente bello.
E funziona.
